最近圈内疯传一个真相,好多HR招数据科学还在死磕Python库和AI流行语清单?醒醒吧,按这套路招来的调包侠,指标跑得再好看,线上也是秒翻车!
- 发生了什么:Machine Learning早期原型指标好看得离谱,HR招人只看工具清单
- 真相是什么:强指标全是数据泄漏和默认参数撑起来的假象
- 影响是什么:招来的人根本没法把模型落地,线上直接拉胯
讲真,这事儿我必须站队吐槽。最近看了一篇爆文,里面把Machine Learning比作希腊神话里的迷宫,简直太贴切了。你看着是在杀那个叫Minotaur的怪物,也就是你要打败的那个评估指标,但真正的危险根本不是这个怪物本身,而是你在那个极其复杂的迷宫里彻底迷失了方向,找回来的路比打怪还难。这时候你需要Ariadne's thread,也就是阿里阿德涅之线,代表你在复杂环境中不迷失的方法论纪律。现在的问题是,太多人只顾着杀怪,完全不管脚下的坑。
特别是HR招人的时候,这现象太严重了!原文里直接开炮,说当数据科学职位的候选人在HR或招聘流程中,主要只通过工具、Python库或AI流行语的清单来评估时,这简直令人担忧。这种筛选方式奖励的只是对机器学习表面的熟悉,却忽略了最核心的深层技能:质疑结果的能力、发现方法缺陷的能力,以及识别强表现可能只是幻觉的能力。说白了,如果问题不是Minotaur本身,而是在它周围的迷宫中迷失的风险,那么隐藏的假设、脆弱的默认值和评估陷阱,远比背诵工具名称的能力重要得多。背名字比培养真正的科学判断容易太多了!
就像Catalini等人说的,在AI丰富的世界里,真正的瓶颈可能会从生成输出转移到验证它们。核心挑战不再是产生快速、低成本的代码和令人信服的结果,而是发展评估这些结果是否真正值得信赖所需的方法论纪律。你跑出个看似说服力的结果算什么?核心是你有没有方法论的纪律去评估这些结果到底能不能信!
扒一扒那些好看的指标是怎么骗人的
那到底怎么个不信法?原文直接列了6个坑,每一个都能让模型看起来比实际强得多。第一个叫The Default Pitfall,默认陷阱,就是被动接受默认选项,根本不去检查这些选项带来的隐藏风险和技术包袱。行为经济学里叫status quo bias或default effect,决策者不成比例地保留预先选择的选项。在机器学习里,默认设置绝不是方法上中立的,它们编码了关于数据结构、任务目标和良好性能含义的假设。
第二个是The Hidden Danger of Data Leakage,数据泄漏的隐藏危险,来自未见数据的信息通过有缺陷的分割、不适当的交叉验证或全样本转换进入模型训练、验证或预处理,让性能看起来比实际更好。第三个The Mirage Metric,海市蜃楼指标,一个吸引人的性能指标给出了成功的表象,同时掩盖了重要的弱点,如尺度偏差、目标对齐不良或经济相关性有限。
第四个The Complexity Amplifier,复杂性放大器,建模管道中增加的复杂性增加的脆弱性超过了它对真实预测性能的改善。第五个The Reversion-to-the-Mean Reality,均值回归现实,表观的预测能力部分只是自然回归到平均行为,即不寻常的极端值随时间推移回到更典型水平的趋势。第六个The Free-Rider Problem,搭便车问题,一个治理陷阱,模型的收益归一方所有,而失败的成本由另一方承担。
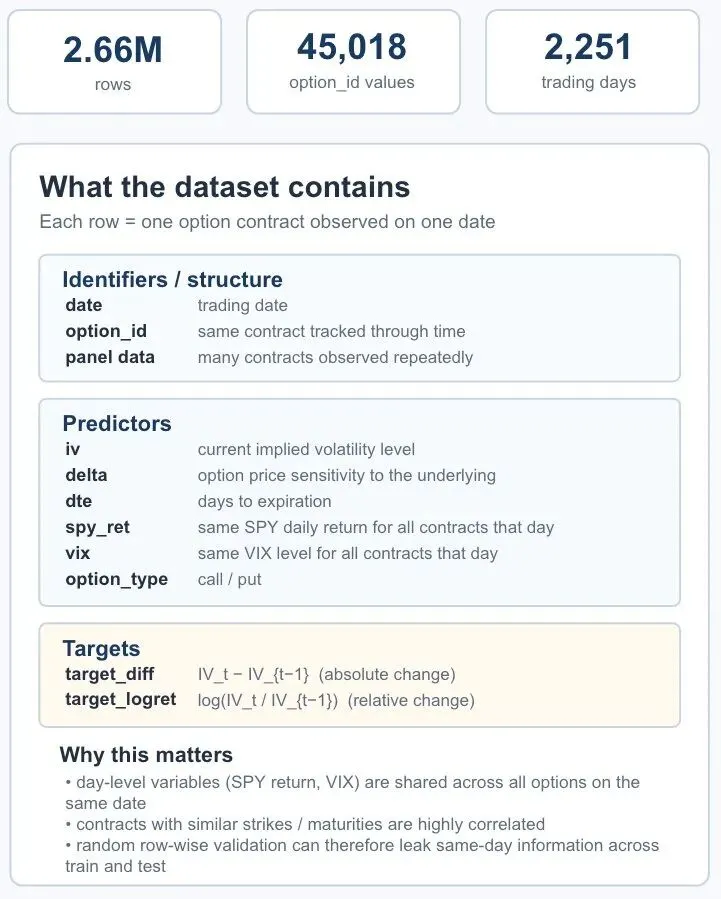
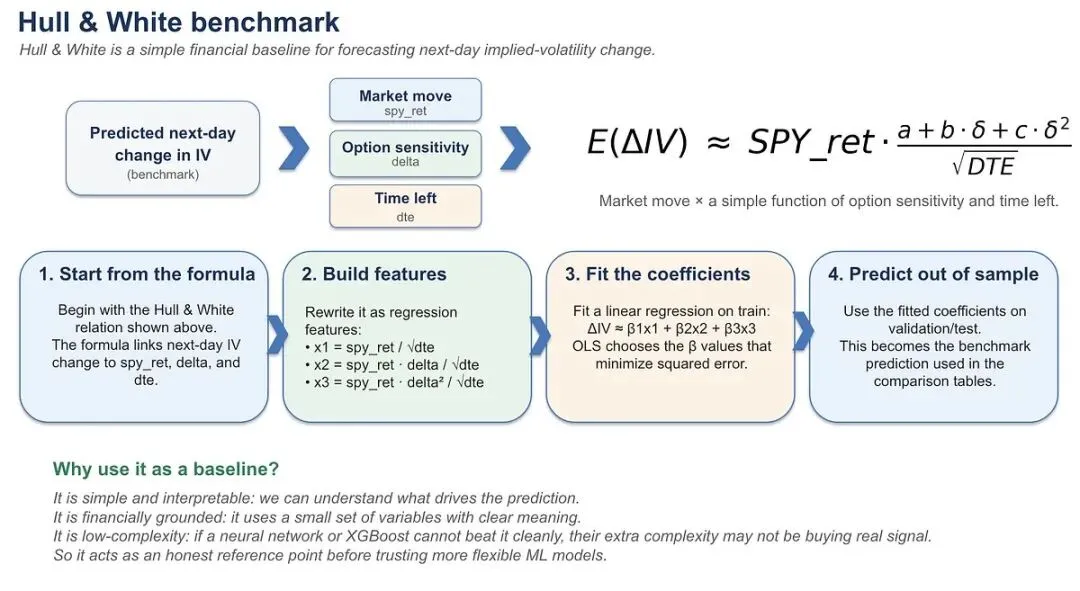
原文里拿隐含波动率预测做了个案例,这玩意儿是从期权价格中得出的衡量标准,反映了市场对未来不确定性的预期。用的是Kaggle上2010到2018年的SPY期权链每日观测值数据,来自Options DX。这数据有面板结构,也就是许多单个期权合约随时间的重复观测值,每行对应一个在特定日期观测到的期权合约option_id。数据集包括隐含波动率IV、Delta、到期天数DTE、标普500指数回报SPY_ret和VIX值。
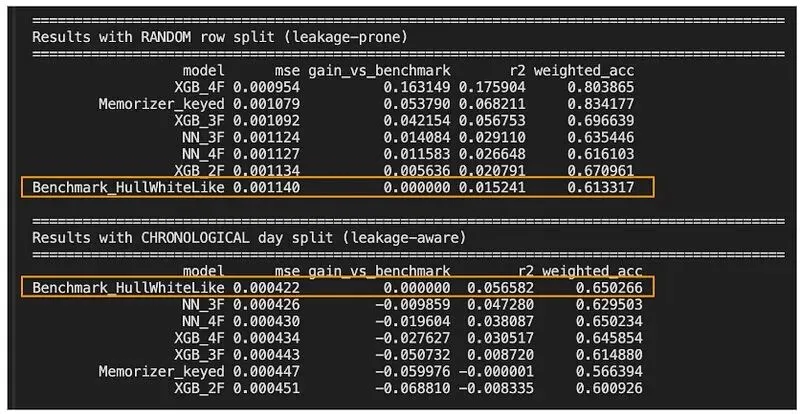
在这种数据里,你如果用默认随机分割,加上那个shuffle=True,这绝对不是一个无害的选择!它可以把同一日期的合约同时放在训练集和测试集中,让模型利用共享的市场结构,而不是去学真正的预测能力。
你想啊,同一天的市场预测变量像SPY_ret和VIX是共享的,模型直接就利用了这个共享的市场结构,这能不强吗?但这根本不是模型懂预测,这是作弊啊!这些陷阱不是独立的技术错误,而是相互关联的机制,通过这些机制,模型看起来比实际更可靠。
这事对你有什么影响
这事儿对咱们影响太大了。做HR和猎头的,别再去死磕候选人会不会念那几个Python库的名字了,懂行的看的是他能不能在迷宫里找到方向,能不能识别那些fragile defaults和evaluation traps。你要找的是能质疑结果的人,不是背词大师。
做产品和运营的,也别被研发一上来跑出的striking metrics给忽悠了,指标好看不代表模型ready for deployment,数据泄漏、不恰当的交叉验证、预处理隐藏的不稳定性,分分钟让线上效果打回原形。你看着模型似乎很有前途,信号看起来很强,结果看起来很鼓舞人心,但在实践中,仅凭强指标并不意味着模型真正理解了潜在现象、泛化良好、稳健或准备好在现实世界环境中部署。这就是现实!
留言聊聊
你面试被问过最离谱的Python库问题是什么?你站背工具名还是真懂行?
来源:Towards Data Science|原文:Why Powerful Machine Learning Is Deceptively Easy
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
