用Bruker timsTOF做蛋白质组/脂质组/代谢组的你,一定被这些问题卡住:- 原始数据是厂商专属TDF格式,只能用闭源库读取,平台受限
- 想在R/Python里做原始数据质控、可视化、算法开发,完全没入口
- macOS用户彻底没法直接访问timsTOF原始数据
今天详解2021年JPR发表的重磅开源工具链——OpenTIMS + TimsPy + TimsR,彻底打通R/Python → timsTOF原始数据的壁垒,开源、跨平台、高速读取TDF原始数据!一、工具定位:这一套工具到底是什么?
📌 发表信息:2021 年 Journal of Proteome Research📌 研发团队:德国美因茨大学 + 波兰华沙大学 + Bruker官方合作📌 核心一句话:一套开源跨平台工具链,基于C++底层解析Bruker TDF原始数据,提供Python(TimsPy)与R(TimsR)上层接口,直接读取timsTOF Pro的LC-TIMS-MS原始数据,支持PASEF/dda-PASEF/dia-PASEF全采集模式。二、为什么必须用这套工具?5大核心痛点解决
- 打破TDF闭源封锁timsTOF原始数据为TDF格式,此前仅厂商提供闭源二进制库,无开源方案。
- 全平台兼容支持Windows / Linux / macOS,macOS用户终于能直接读timsTOF数据。
- 双语言支持提供Python(TimsPy) + R(TimsR)接口,覆盖数据科学主流生态。
- 高速低耗比厂商官方C++库快约43%,支持HDF5导出+vaex内存外分析,大文件不卡顿。
- 赋能研发与质控支持原始数据质控、算法开发、机器学习、仪器监控、教学演示。
三、技术架构:三层模块化设计
工具采用底层→中层→上层的清晰架构,兼顾性能与易用性:- 底层核心:OpenTIMS(C++库)直接解析TDF数据(analysis.tdf SQLite库 + analysis.tdf_bin二进制),负责数据解码、解压、帧读取。
- 中间绑定:opentimspy / opentimsr轻量绑定层,对接C++与Python/R,无冗余依赖。
- 上层工具:TimsPy(Python)、TimsR(R)面向用户的友好接口,数据以表格形式呈现,支持快速绘图、统计、聚合。
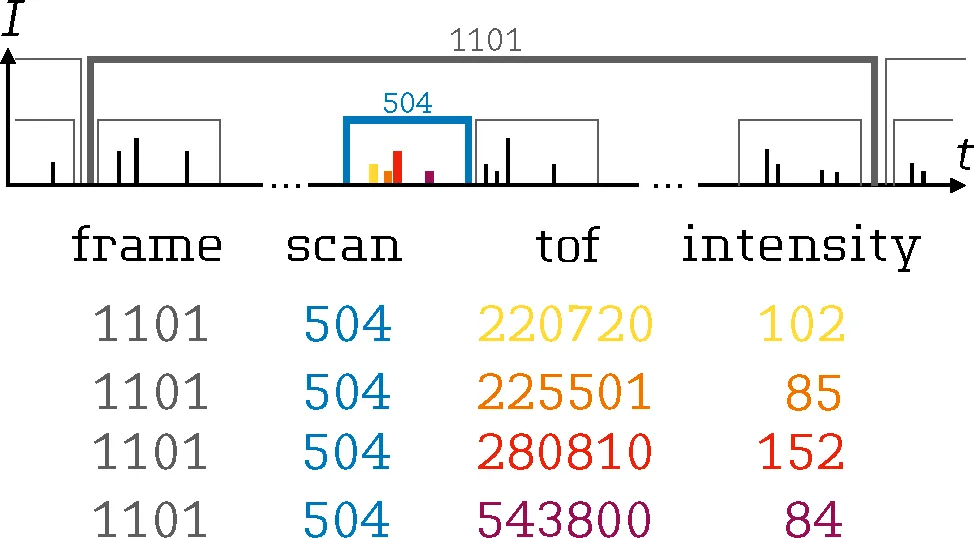
四、timsTOF数据核心逻辑:读懂Figure1,就懂了全部数据结构
timsTOF 数据和普通 Orbitrap 不同,多了离子淌度(TIMS)维度,采集层级为:Frame(帧) → Scan(离子淌度扫描) → TOF(飞行时间) → Intensity(强度)Figure1清晰展示了timsTOF数据采集的全流程:·TOF+Intensity:最微观的数据单元,记录离子飞行时间与信号强度,TOF后续会由仪器换算为m/z;
·Scan:一次TIMS阱释放,对应固定逆离子淌度,同批次离子淌度完全一致,是timsTOF独有的分离维度;
·Frame:一整套完整Scan循环,和LC保留时间精准对齐,一个色谱峰通常会覆盖多个连续Frame;
·最终存储:所有数据以frame、scan、tof、intensity四列表格保存,这也是TimsPy/TimsR直接读取的原始数据格式。
这是理解后续所有质控图表的基础,也是timsTOF数据区别于普通质谱的核心特征。五、实战质控:从分布到定量,从静态到动态,层层看透数据质量
在掌握timsTOF数据结构后,我们最关心的就是原始数据质量。研究团队基于TimsPy工具,以dia-PASEF模式下的HeLa样本为研究对象,按照直观分布→精准定量→动态趋势的逻辑,逐层深入分析不同液相通量对数据质量的影响,完整展现了这套工具在原始数据质控中的强大能力。(一)先看二维分布:单/多电荷天然分层,数据质量一眼区分
判断timsTOF数据好坏,最直观的方式就是观察有效离子和杂质离子的分布特征。蛋白质组中,多电荷离子(2+/3+)是肽段有效分析信号,单电荷离子(1+)多为盐离子、污染物等无效杂质,而timsTOF的离子淌度特性会让这两类离子天然形成分层。图3就是将每个样本的全部MS1前体离子,在m/z(横轴)×逆离子淌度(纵轴)二维空间内做强度聚合后的可视化结果。·样本设置:共计9个独立样本,按照液相通量分为3组,通量越高代表液相流速越快、分析速度越快:第一行:60 spd(低通量,慢流速);第二行:100 spd(中通量,中流速);第三行:200 spd(高通量,快流速),每组3个子图对应3个独立样本;
·分界线:图中对角线是经验分界线,斜线上方为单电荷杂质离子,斜线下方为多电荷有效肽段;
·直观结果:60 spd低通量样本中,斜线下方的多电荷离子信号云极其浓密,有效信号占绝对主导;随着通量提升到100 spd,多电荷信号开始减弱;到200 spd高通量时,斜线上方的单电荷杂质离子信号大幅增多,有效信号被严重稀释。
仅通过这张二维分布图,就能快速定性判断:液相通量越高,timsTOF原始数据的有效信号占比越低,数据质量越差。(二)再做定量统计:用数据实锤,通量越高数据质量越差
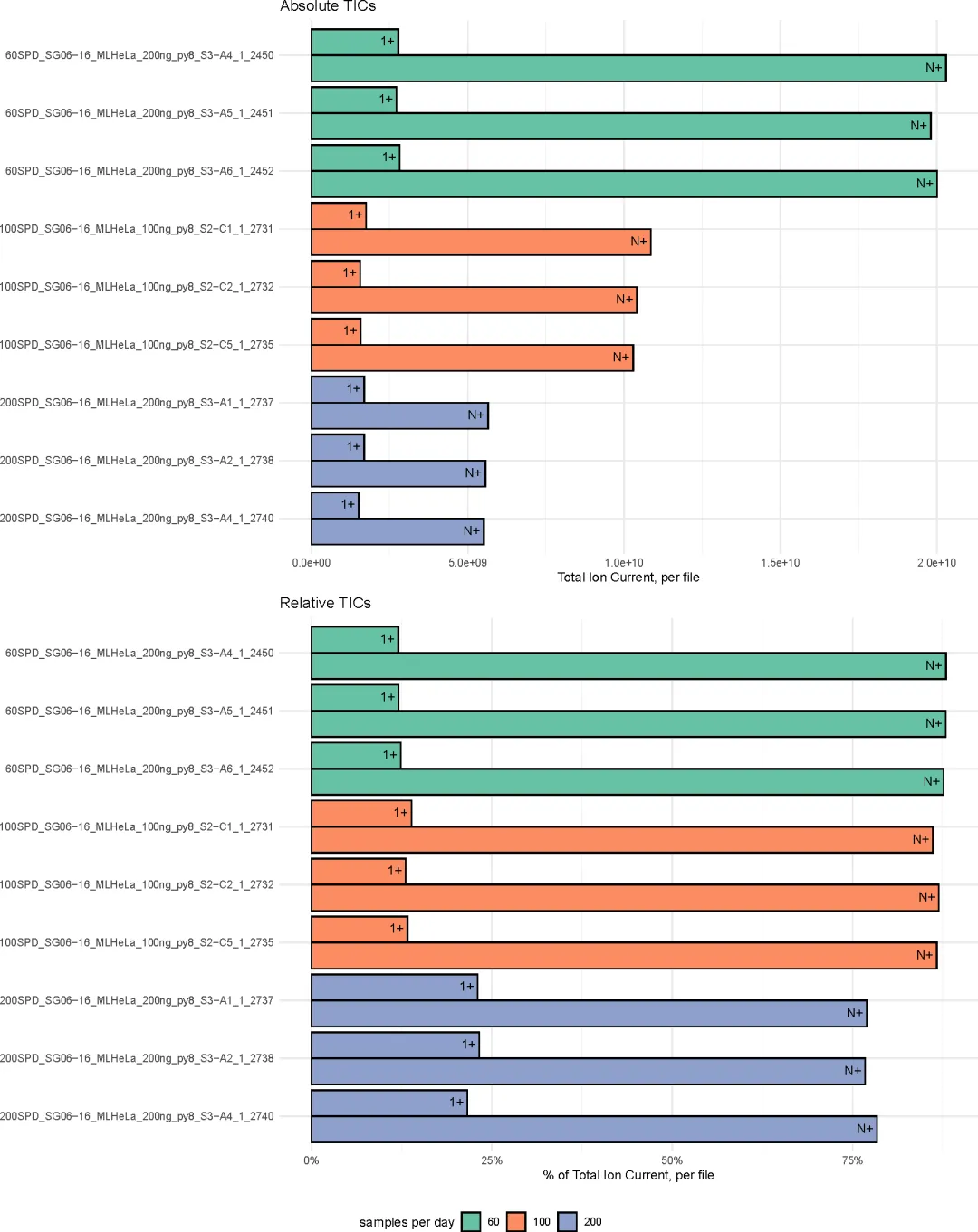
二维分布只能做定性判断,为了精准量化单电荷与多电荷离子的差异,研究团队基于图3的分界线,分别统计了两类离子的绝对总强度和相对占比,形成了图4的定量质控结果。图表分为上下两个部分,样本分组和排序与图3完全一致:·上图:Absolute TICs(绝对总离子流强度)横轴为离子信号的绝对强度值,每个样本的条形由单电荷(1+)和多电荷(N+)两部分组成。可以清晰看到,随着通量从60→100→200 spd升高,样本的总离子信号呈现断崖式下跌,其中下降最明显的就是代表有效数据的多电荷离子,单电荷离子的绝对强度变化则相对平缓。
·下图:Relative TICs(相对总离子流占比)横轴为百分比,将每个样本的总离子流计为100%,直观展示单/多电荷离子的占比关系。60 spd样本中,多电荷离子占比超过80%,是理想的电离状态;100 spd样本中,多电荷占比明显下降,单电荷占比开始上升;200 spd样本中,单电荷杂质离子占比大幅飙升,多电荷有效离子占比被压缩至极低水平。
这组定量数据用实打实的数值证明:盲目提升液相通量,会导致电离效率急剧下降,有效肽段信号大幅流失。(三)追踪动态趋势:电离问题全程存在,贯穿整个实验周期
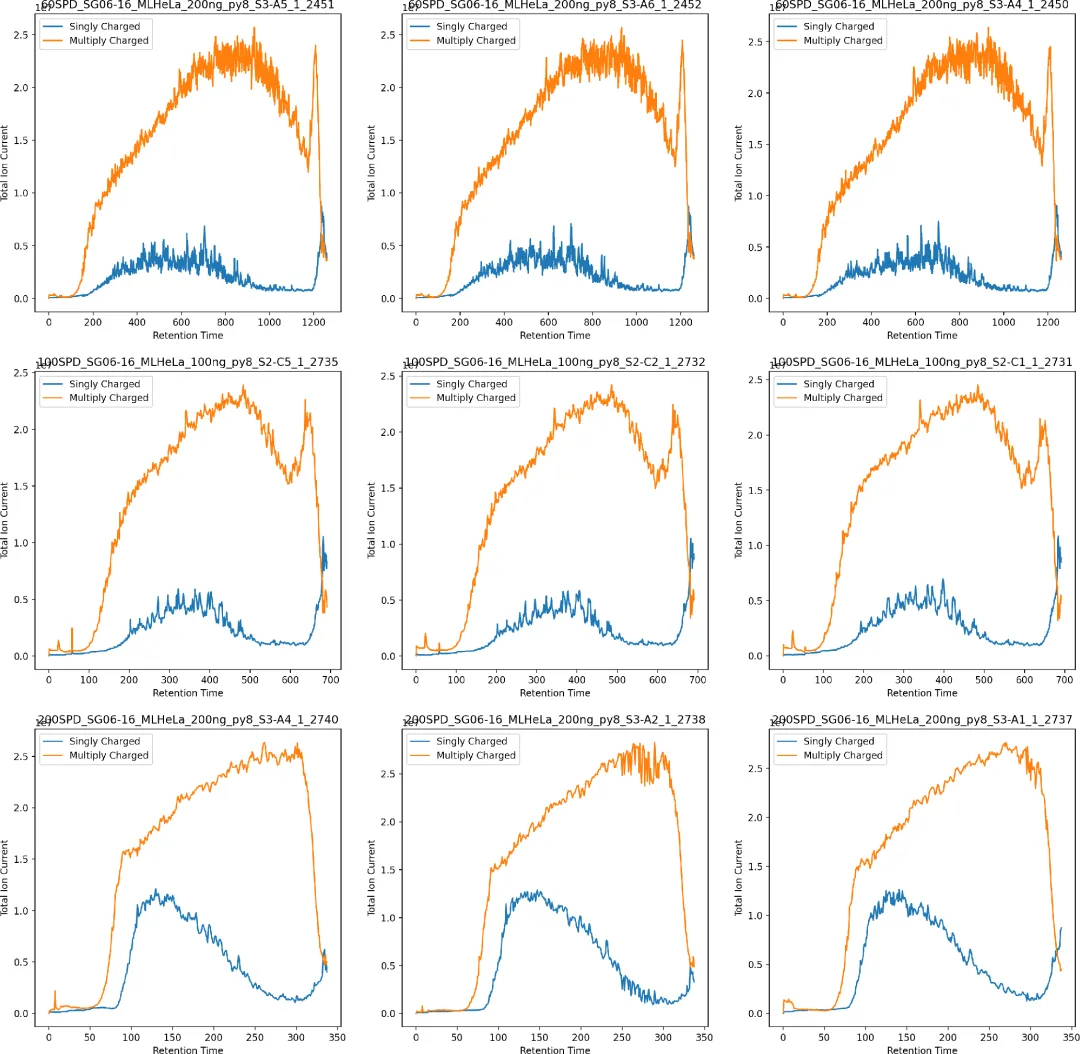
图4的静态统计已经明确了不同通量下的数据质量差距,但我们还需要进一步明确:这种质量问题是实验中某一时间段的局部波动,还是贯穿整个色谱洗脱过程的全局问题?带着这个问题,研究团队绘制了图5,展示单电荷/多电荷离子强度随保留时间的动态变化趋势,完整还原整个LC-MS run的电离状态:·横轴:Retention Time(保留时间),代表整个液相洗脱的全过程;
·纵轴:Ion Intensity(离子强度),反映不同时间段的信号强弱;
·分组结果:60 spd低通量样本全程多电荷离子保持高强度信号,单电荷杂质离子信号几乎可以忽略,电离状态稳定且优质;100 spd中通量样本全程多电荷离子强度明显降低,单电荷离子信号同步升高,电离效率开始出现明显缺陷;200 spd高通量样本全程多电荷离子信号处于极低水平,单电荷杂质离子反而占据信号主导,电离状态全面劣化。
这张图彻底揭开了问题本质:通量提升带来的电离不充分,不是局部异常,而是贯穿整个实验全过程的系统性问题,也进一步坐实了高通量方法对timsTOF数据质量的严重负面影响。(四)最后验证性能:高速引擎加持,批量质控更高效
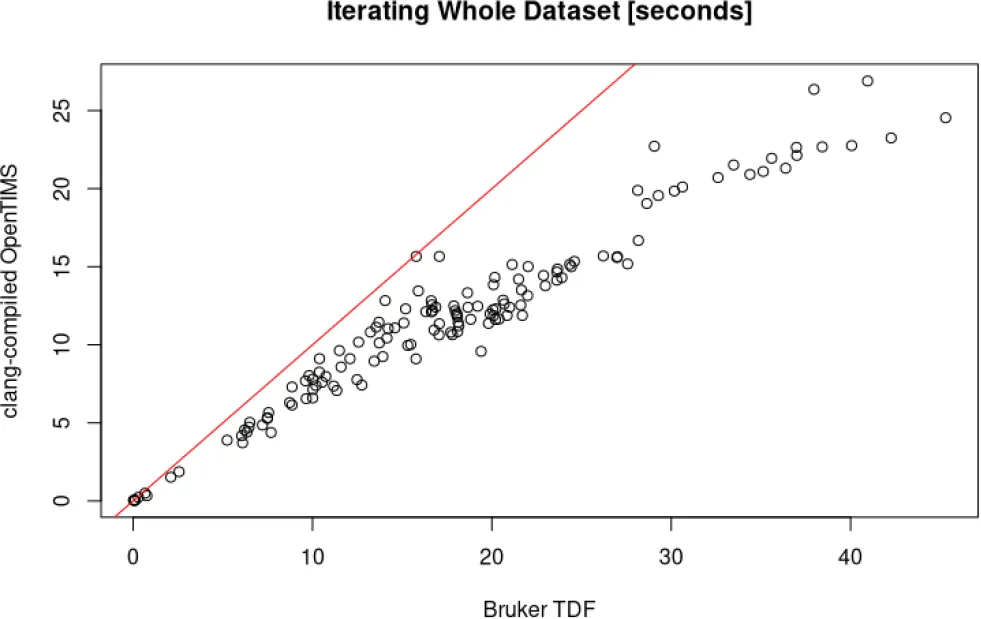
[图6: OpenTIMS vs Bruker官方库性能基准测试]上述层层深入的质控分析,需要快速读取、处理多个GB级别的timsTOF原始数据,对工具的读取速度提出了极高要求。为此,研究团队针对OpenTIMS和Bruker官方C++库做了专项性能基准测试,也就是图6的结果。·测试任务:完整遍历数据集内所有Frame(质谱原始数据处理的最基础操作);
·测试规模:139个真实timsTOF数据集,结果极具说服力;
·图表解读:横轴为Bruker官方库的遍历耗时,纵轴为OpenTIMS的遍历耗时,对角线为两者速度相等的参考线;所有数据点均紧贴在对角线下方,意味着OpenTIMS在所有数据集上的读取速度都快于官方库;
·核心数据:OpenTIMS的遍历耗时比官方库减少约43%,速度提升近1.8倍。
正是凭借这种高性能优势,OpenTIMS、TimsPy、TimsR才能轻松应对批量样本的深度质控,完美适配实验室高通量、高效率的分析需求。六、总结:核心价值
- timsTOF领域首个开源底层数据工具,彻底打破TDF格式的闭源垄断;
- R/Python双语言支持,填补了R语言无法直接访问timsTOF原始数据的行业空白;
- 全平台兼容+高速低耗,Windows/Linux/macOS均可运行,大文件处理不卡顿;
- 质控流程完整闭环,从分布、定量到动态趋势,实现timsTOF原始数据质量的全面评估;
- Bruker官方合作研发,稳定性和兼容性拉满,适配所有timsTOF Pro机型。
这套工具从数据读取→质控可视化→性能优化全覆盖,是每一位timsTOF用户不可或缺的底层分析神器!·OpenTIMS:https://github.com/michalsta/opentims
·TimsPy:https://github.com/MatteoLacki/timspy
·TimsR:https://github.com/MatteoLacki/timsr


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
