我的Python100天打卡:70 np.einsum() 一维数组 | 方阵 | 统计运算
- 2026-06-30 05:57:17

上次笔记,我们初步领略了np.einsum在二维数组求和与转置中的威力。今天,我们将目光聚焦到更基础的一维数组,并延伸到方阵特性与统计运算,这个小小的函数几乎覆盖了线性代数和统计学中大部分的基础计算。
今天的学习内容来自教材第18章,包括:
18.5 一维数组
18.6 方阵
18.7 统计运算
章末习题
--
18.5 一维数组
1️⃣核心概念
一维数组(向量)是线性代数的基石。np.einsum在处理向量时,语法更加直观,对应了高中数学里的向量运算概念。
2️⃣四种基本运算代码实现
import numpy as np# 假设 X 是之前的鸢尾花数据 (150, 4)# 提取两个行向量作为例子a_1D = X[0] # 形状 (4,)b_1D = X[1] # 形状 (4,)# 1. 向量求和:将所有元素加起来sum_a = np.einsum('i->', a_1D)# 对应公式:\sum_i a_i# 等价于 np.sum(a_1D)# 2. 向量逐项积(元素对应相乘):# 注意:这里虽然写的是'i,i->i',但其实是把两个向量当成同形状输入# 它会对对应位置的元素相乘,结果还是一维数组element_prod = np.einsum('i,i->i', a_1D, b_1D)# 等价于 a_1D * b_1D# 3. 向量内积(标量积/点积):对应元素相乘再求和dot_product = np.einsum('i,i->', a_1D, b_1D)# 对应公式:\sum_i a_i * b_i# 等价于 np.dot(a_1D, b_1D)# 4. 向量外积(张量积/Outer Product):生成一个矩阵outer_prod = np.einsum('i,j->ij', a_1D, b_1D)# 结果是一个 4x4 的矩阵,第i行第j列是 a[i] * b[j]# 等价于 np.outer(a_1D, b_1D)
3️⃣图解理解
图18.11 / 18.12:展示了求和与逐项积,维度从i变成空或保持i。
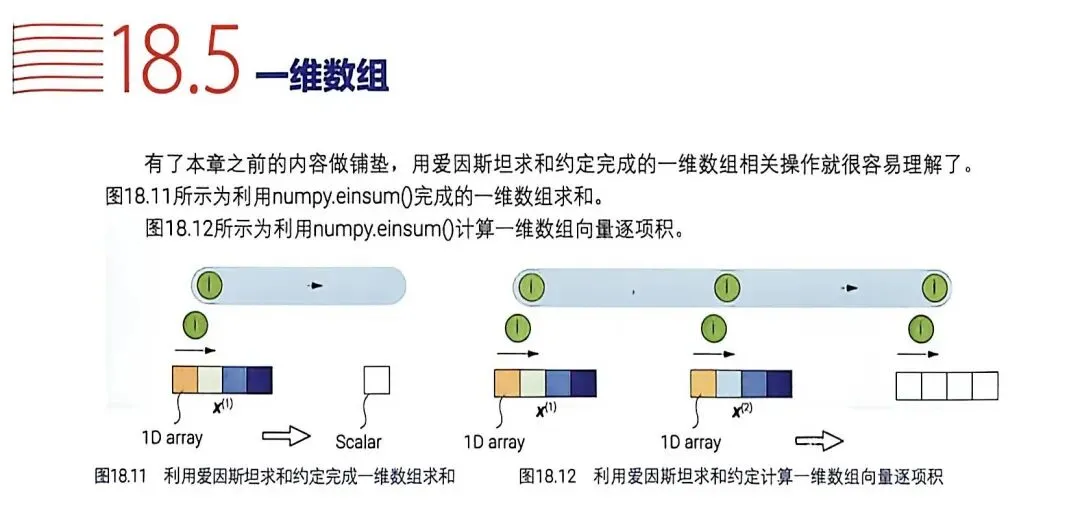
图18.13:内积,两个i维度相遇相消,变成标量。
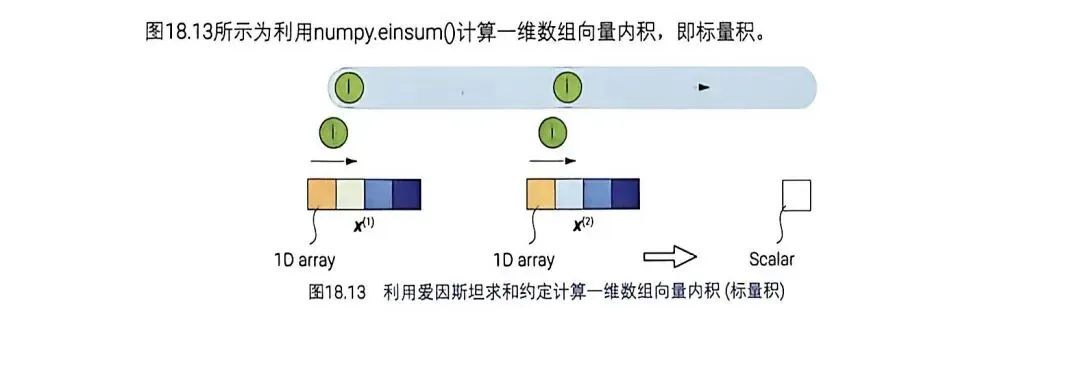
图18.14:外积,i和j保留,生成了一个二维网格(矩阵)。
4️⃣爱因斯坦求和约定进行一维数组的相关操作(与图18.11-18.14相对应)

--
18.6 方阵
1️⃣核心概念
方阵是行数和列数相等的二维数组。在机器学习中,协方差矩阵、相关系数矩阵都是方阵。einsum可以非常优雅地提取方阵的几何特征。
2️⃣方阵的操作相关代码
# 假设 G 是一个方阵,比如之前的格拉姆矩阵 (4, 4)# 或者是数据的协方差矩阵# 1. 提取对角线元素(得到特征值的雏形)diag_elements = np.einsum('ii->i', G)# 解释:输入两个'i'(行和列),输出一个'i'(保留相同的位置)# 等价于 np.diag(G)# 2. 计算方阵的迹(Trace):主对角线元素之和trace_G = np.einsum('ii->', G)# 解释:输入两个'i',但在输出中没有'i',意味着对i求和# 等价于 np.trace(G) 或 np.sum(np.diag(G))
__
18.7 统计运算
1️⃣核心概念
np.einsum不仅能做线性代数,还能做统计。传统的np.cov(协方差矩阵)内部其实就是一个巨大的矩阵乘法,用einsum写出来会让你看清数据的流动。
2️⃣从均值到协方差的推导
n = X.shape[0] # 样本数量 (150)# 1. 计算列均值(每一列的质心)# 'ij->j':对行(i)求和平均,保留列(j)mean_X = np.einsum('ij->j', X) / n# 等价于 np.mean(X, axis=0)# 2. 中心化数据(每个数据减去均值)# 这一步通常直接用减法,但如果硬要用einsum表达广播思想,可以结合reshape,不过这里教材主要展示后续步骤# 3. 计算方差(假设X_c是已经中心化后的数据 X - mean)# 这里 'ij,ij->j' 表示:对每一列j,将该列的所有元素平方后求和variance = np.einsum('ij,ij->j', X_c, X_c) / (n - 1)# 等价于 np.var(X, axis=0, ddof=1)# 4. 计算协方差矩阵(重点!)# 传统写法:X_c.T @ X_c / (n-1)# Einsum写法:cov_matrix = np.einsum('ij,ik->jk', X_c, X_c) / (n - 1)# 解释:# 输入1:X_c 的索引 'ij' (样本i, 特征j)# 输入2:X_c 的索引 'ik' (样本i, 特征k)# 共享索引 'i':表示对样本维度进行求和(点积)# 输出索引 'jk':生成一个特征j和特征k之间的关系矩阵# 等价于 np.cov(X.T, ddof=1)
3️⃣图解理解
图18.17:均值,压缩行维度。
图18.18:方差,自身点积求和。
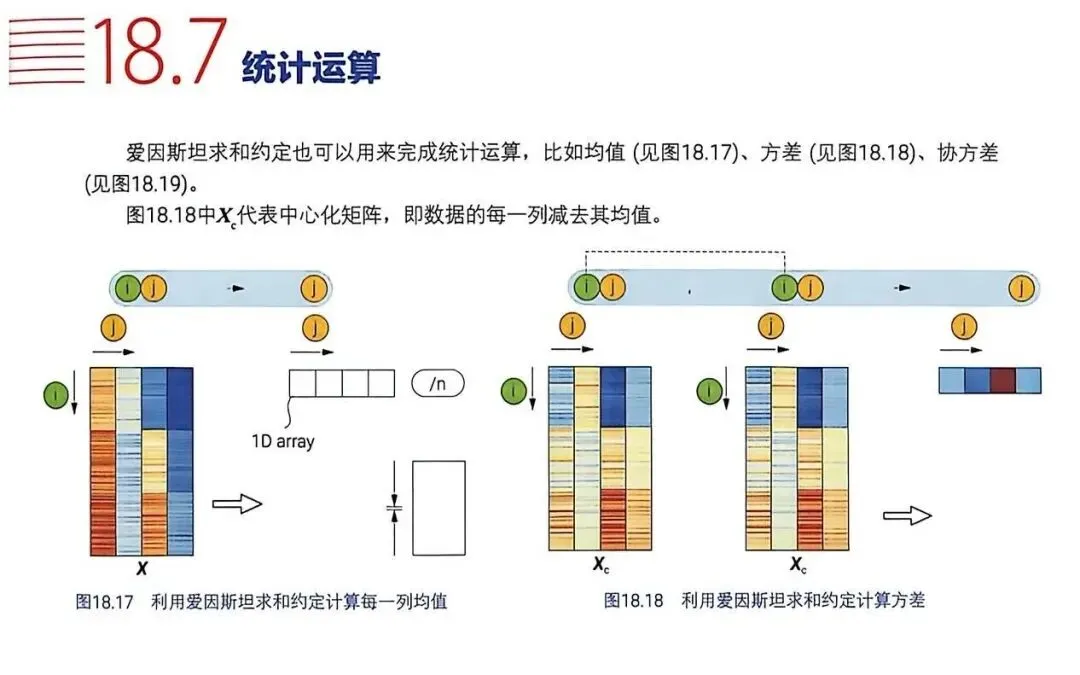
图18.19:协方差,两个特征向量的交叉点积。
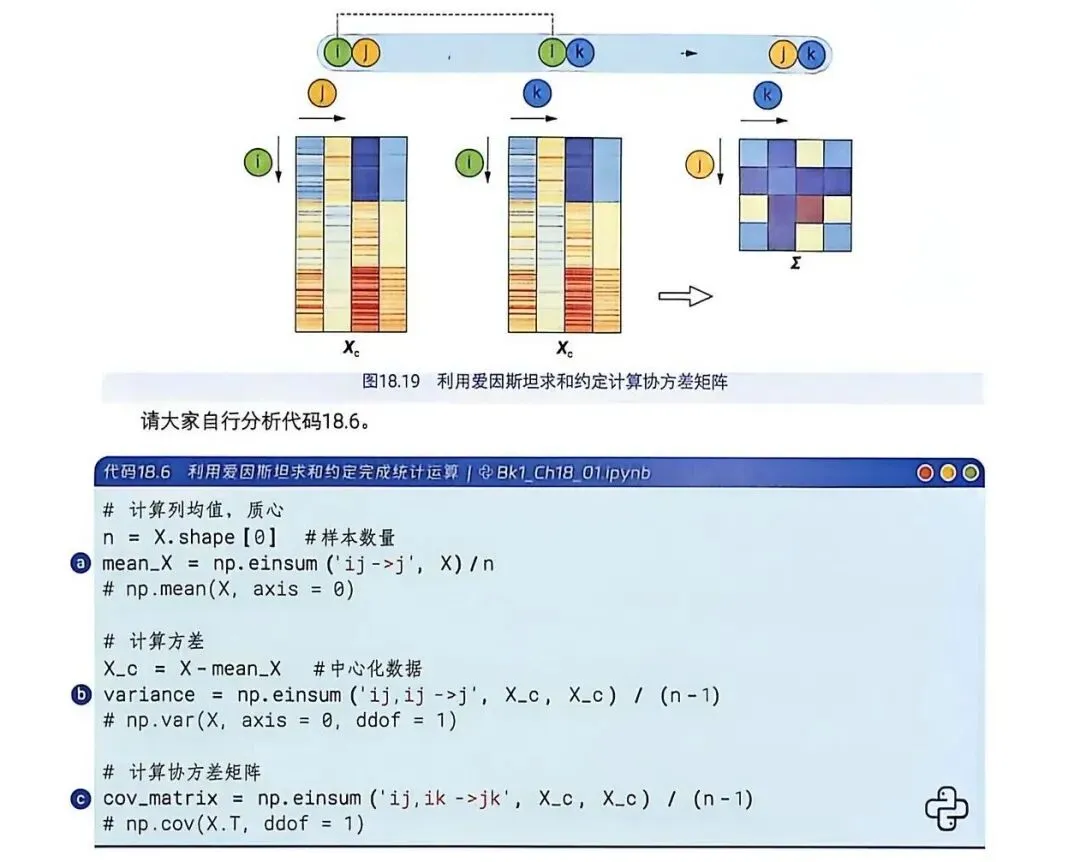
4️⃣用自己的话理解代码18.6:
# 1. 计算列均值mean_Xn = X.shape[0] # 样本数量mean_X = np.einsum('ij->j', X) / n # 计算列的均值,详细过程如下:# 输入:X是二维数组,索引为 i(行/样本)和 j(列/特征)。# 操作:->j表示我们要把 i这个维度“压扁”(求和)。也就是说,把每一列的所有行加起来。# 结果:得到一个长度为 4 的一维数组(每列的总和)。# 2. 计算方差varianceX_c = X - mean_X # 中心化数据variance = np.einsum('ij,ij->j', X_c, X_c) / (n - 1) # 计算方差variance,详细过程如下:# X_c = X - mean_X: 这一步叫“中心化”。把每个特征列减去它的均值,使得这一列数据的平均值变为 0。这是计算方差的前提。# np.einsum('ij,ij->j', X_c, X_c):# 输入:X_c和 X_c自己乘自己。# 操作:ij,ij->j。这里两个数组都有 i和 j维度。# 首先,元素对应相乘:用X_c的第 i行第 j列,乘以 X_c的第 i行第 j列。# 然后,按 j求和# 注意,这里 i并没有出现在输出中,说明 i维度被“折叠”了(也就是对所有样本 i求和)。# 物理意义:对于第 j个特征,计算它所有样本的“离差平方和” (Sum of Squared Differences)。# / (n - 1): 除以 n-1是统计学中求样本方差的无偏估计标准做法。# 另外,这行代码等价于np.var(X, axis=0, ddof=1)# 3. 计算协方差矩阵cov_matrixcov_matrix = np.einsum('ij,ik->jk', X_c, X_c) / (n - 1) # 计算协方差矩阵# 这是整个代码最核心的部分。# 1. 输入:还是 X_c,用了两次:# 第一个 X_c索引是 ij(i=样本, j=特征1)。# 第二个 X_c索引是 ik(i=样本, k=特征2)。# 两个输入共享了 i维度(样本维度)。# 2. 详细分析np.einsum()里面的操作:# 2.1 元素相乘:对应样本 i的两个特征 j和 k相乘。# 2.2 按 i求和:因为 i没有出现在输出 jk中,所以对所有样本的 i进行求和。# 3. 输出结果:按照协方差定义的公式,输出一个 4x4 的矩阵(因为 j和 k都是 4 个特征)。# 4. 标准化/ (n - 1): 对结果除以 n-1,进行标准化。# 这行代码等价于 np.cov(X.T, ddof=1)。# 注意:np.cov默认需要数据是“特征在行,样本在列”的形状,# 所以通常要转置 X.T,# 而这里用 einsum直接处理 X_c非常直观。
---
今天最重要的体会:用自己的话去理解np.einsum()计算协方差矩阵的过程。
1. 其实之前已经学过了np.cov()计算协方差矩阵了,为什么书本还要特意让我们用另一个工具来计算?
真的只有自己体验过,才能理解:np.cov()是基础工具,它简单直接,但需要自己做好转置X.T等操作;而用np.einsum()相当于优化了用户体验,除了不用想如何进行转置,也不用去分析axis = 0 还是 1,只要看字母,ij, ik -> jk,代码就能自动帮我们处理好。有种半自动的人工智能感觉!
2. 说到用户体验,我觉得np.einsum()的整个函数设计,也很符合我们人类直觉思维:它的逻辑很清晰,也避免了np.cov()计算协方差公式中,先要计算中间变量(平均方差)的麻烦,而且对于更大、更复杂的矩阵,np.einsum()还能优化计算路径,更快地得出结果。
明天打算把计算题做一做,掰开揉碎去掌握np.einsum()的应用题。
---
笔记写于:2026年5月6日07:55:33
结束于:2026年5月6日09:13:36
用时:约1小时(有中断)
--
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 30个超有趣的Python代码(中)
- Python大数据项目推荐:Hadoop+Django脑卒中风险分析系统源码解析 毕业设计 选题推荐 毕设选题 数据分析 机器学习 数据挖掘
- Python爬虫实战:爬取全网VIP电影
- Linux内核“核弹级”漏洞 CVE-2026-31431 深度解析与 Payload 披露
- 硬核拆解:Linux 内存性能优化从原理到实战
- plotnine:在Python 里实现“Grammar of Graphics”的库,简单语义化代码,就能得到复杂或优雅的图
- 刘凌峰《用Python自动办公,做职场高手》内训课纲
- Python真的比JAVA好用吗?
- 【Python3.9.5】Python3.9.5下载安装教程Python 软件零基础轻松上手
- Linux 的 cksum 命令
