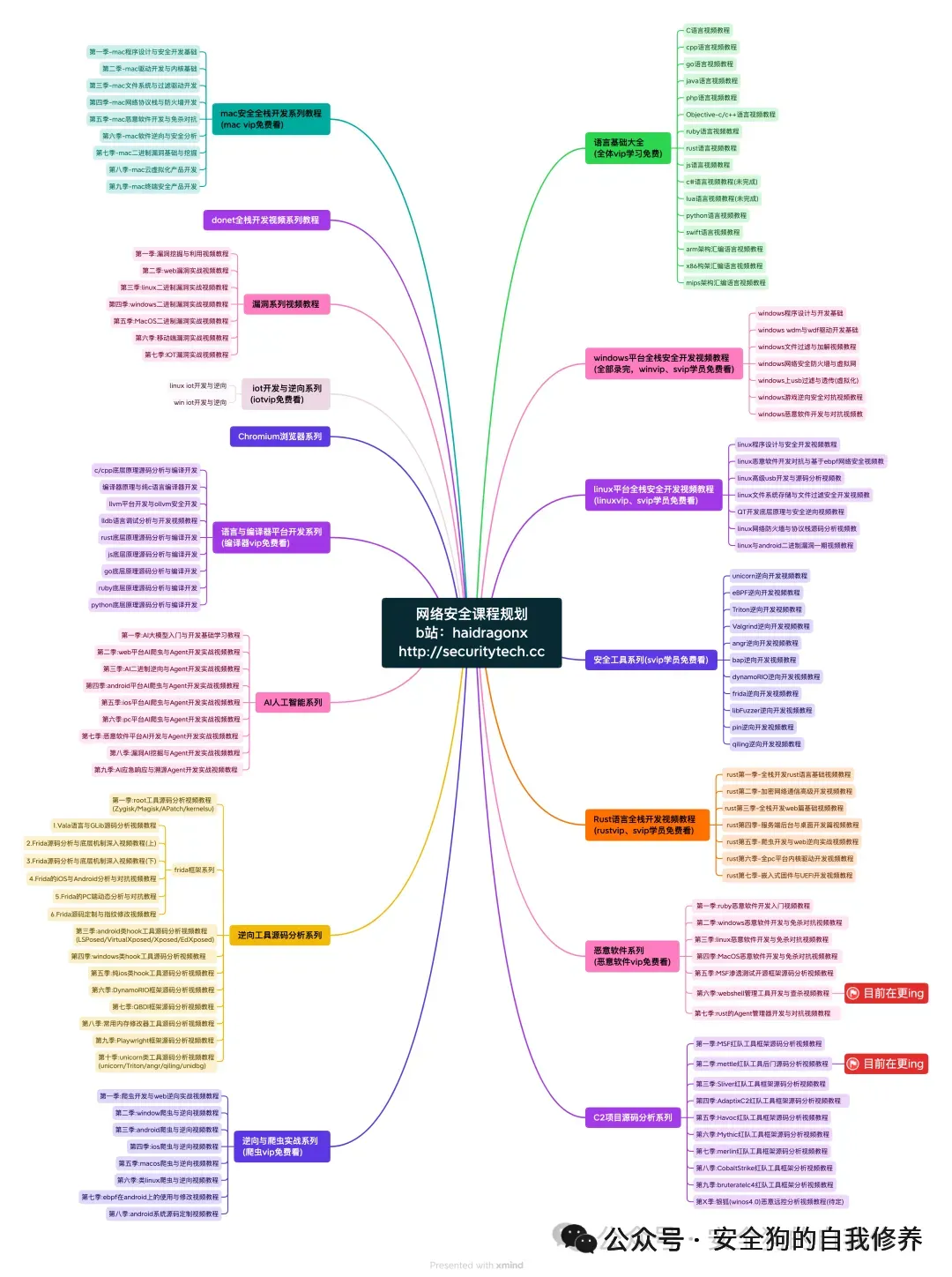
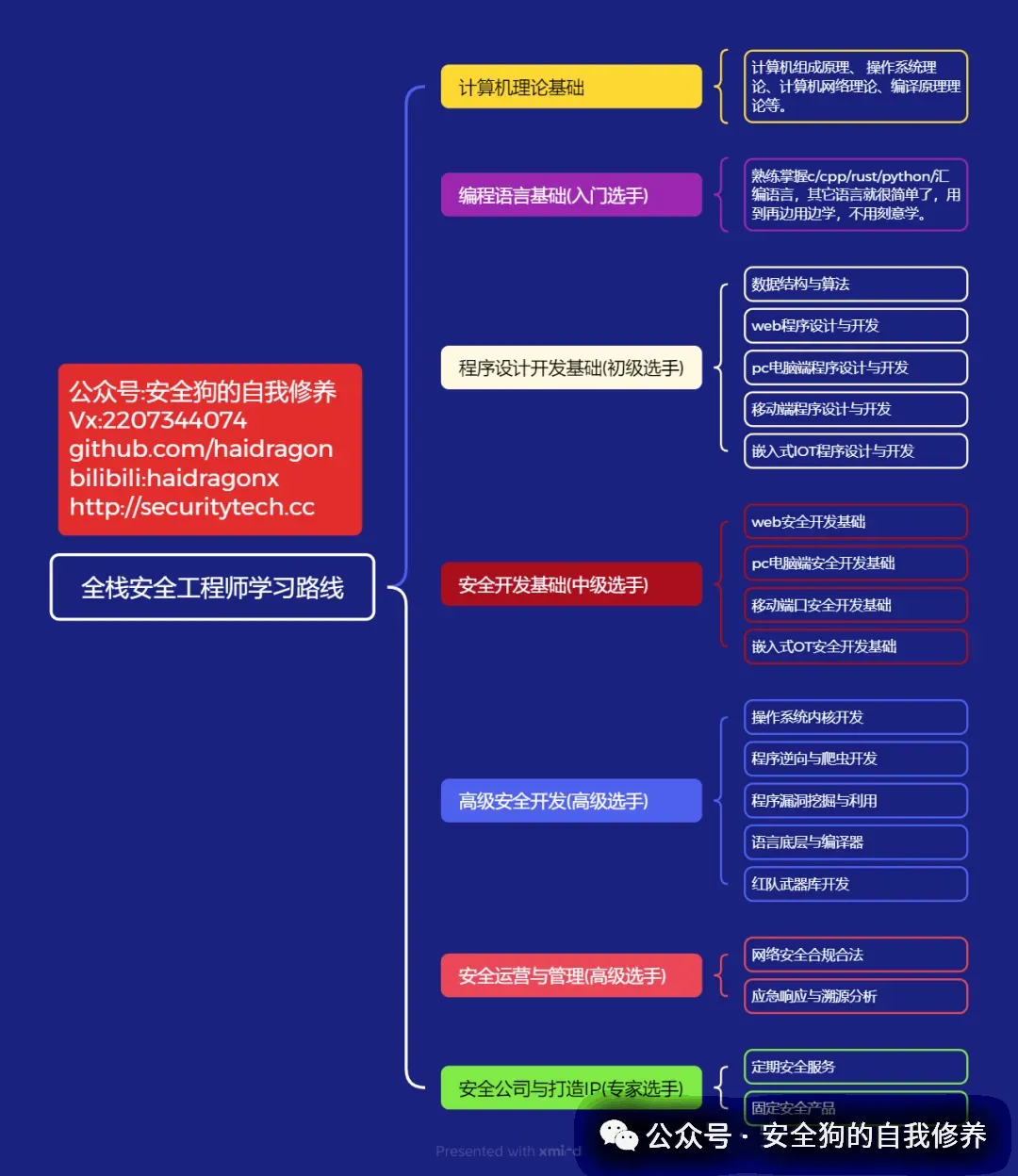
官网:http://securitytech.cc
今天学什么?
- 漏洞赏金的 Python 基础知识——快速回顾
- 针对HTTP请求发起攻击
- 创建自定义的IDOR扫描器
- 创建子域名暴力破解工具
- 创建API密钥暴露扫描器
- 多线程速度提升10倍
- 完整的重建自动化流水线
为什么一定要这么做? 手动测试 = 慢 = 缺少漏洞!Python自动化 = 10倍速度 = 10倍漏洞 = 10倍赏金!顶尖猎手们会开发自己的定制工具,去挖掘那些通用工具遗漏的细节!这是高级系列的第一篇文章,从今以后,我们不仅要做猎手,还要成为工具开发者!
为什么我的漏洞赏金是Python?
通用工具(Nuclei、Subfinder等):→所有猎人都拥有→相同结果=重复风险 zyada!→无法自定义逻辑,我的Python工具:→只有你才有!→自定义逻辑=独特的漏洞!→针对特定目标进行优化→多种技术串联起来→可以集成AI!真正差异:100个猎人核心正在狩猎=相同结果1款猎人定制Python工具,挑战来袭!=独一无二!Python=漏洞赏金的秘密武器!🐍
第一部分:设置环境,准备Karo
# 检查 Python 3.10+:python3 --version# 创建虚拟环境(最佳实践!):python3 -m venv bugbounty_env来源 bugbounty_env/bin/activate# Windows: bugbounty_env\Scripts\activate# 一次性安装必备库:pip 安装 requests \httpx \aiohttp \BeautifulSoup4lxml \颜色ama \丰富的tqdm \python-dotenv \argparse# 验证安装:python3 -c "import requests, colorama, rich; \print('✅ 所有库已就绪!')
第二部分:HTTP请求基础 学习一下
基本请求:
import requests# ─── GET请求 ──────────────────────────r = requests.get("https://target.com/api/user")print(r.status_code)# 200、401、403、500……print(r.text)# 完整响应体print(r.json())# JSON解析(如果为JSON格式)print(r.headers)# 响应头print(r.cookies)# Cookies# ─── 带参数的GET请求 ──────────────────参数={"id":"1001","format":"json"}r = requests.get(“https://target.com/api/user”,参数=参数)# 最终URL:/api/user?id=1001&format=json# ─── 使用JSON的POST请求──────────────────────数据={"用户名":"admin","密码":"test123"}r = requests.post(“https://target.com/login”,json=数据,# 自动内容类型:JSON超时=10)#───包含头信息与Cookie的完整请求──头部={“授权”:“Bearer YOUR_JWT_TOKEN”,“用户代理”:Mozilla/5.0(X11;Linux x86_64)“X-Forwarded-For”:“127.0.0.1”}cookies ={"session":"ABC123XYZ"}r = requests.get(“https://target.com/api/dashboard”headers=headers,饼干=饼干,verify=False,# 跳过SSL检查(仅用于测试!)超时=10,允许重定向=True)
会话对象 Cookie 自动管理:
import requests# 会话 = 登录一次——所有请求都用这个会话# 自动化Cookie保持!session = requests.Session()# 第一步:登录会话.post(“https://target.com/login”,json={"用户":"attacker@test.com",“密码”:“mypassword123”})# ✅ 会话Cookie自动保存!# 第二步:经过身份验证的请求——Cookie自动附加!r1 =会话.get("https://target.com/api/profile/1002")r2 =会话.get("https://target.com/api/invoices/9876")r3 = session.get("https://target.com/api/messages/555")print(r1.text)# 受害者个人资料——IDOR测试!print(r2.text)# 受害者的发票! print(r3.text)# 私密消息!# ─── Requests 忽略 SSL 警告 ─────────导入urllib3urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
第三部分:打造属于你的自定义IDOR扫描器!
#!/usr/bin/env python3"""IDOR扫描器v2.0 — HackerMD测试数字 + UUID ID 参数
python import requests
导入 json导入时间来自colorama的Fore、Style和initimport urllib3urllib3.disable_warnings()init(autoreset=True)类IDORScanner:def __init__(self, base_url, token,我的ID,ID范围=(1,200),延迟=0.1):self.base_url = base_urlself.my_id = my_idself.id_range = id_rangeself.delay =延迟self.session = requests.Session()self.session.headers.update({“授权”: f“Bearer{token}”,“用户代理”:“Mozilla/5.0”})self.session.verify =Falseself.脆弱=[]self.errors =0def get_baseline(self):获取你的数据——基线长度尝试:r =self.session.get(f"{self.base_url}/{self.my_id}",超时=10)返回 r.status_code, len(r.text)除Exception以外:print(f"{Fore.YELLOW}⚠️ 基线错误:{e}")返回空值,0def test_single_id(self, test_id, base_len):“测试单个ID”尝试:r =self.session.get(f"{self.base_url}/{test_id}",超时=10)# 200 + 长度显著不同# = 可能是不同用户的数据!长度差= abs(len(r.text)-基线长度)如果 r.status_code ==200且长度差>30:返回{“id”:测试ID,“状态”:r.status_code,“长度”:len(r.text),“差异”:长度差异,“预览”:r.text[:150]}除 requests.exceptions.Timeout之外:self.errors +=1除了Exception作为 e:self.errors +=1返回空def扫描(self):打印(f"{Fore.CYAN}╔══════════════════════════════╗)print(f"{Fore.CYAN}║ IDOR扫描器—HackerMD║")print(f"{Fore.CYAN}╚══════════════════════════════╝")打印(f"目标:{self.base_url}") print(f"我的ID :{self.my_id}") print(f"范围:{self.id_range[0]}–{self.id_range[1]}")print(f"延迟:{self.delay}秒")print("─" * 40) # 基线基础状态,基础长度 = 自我获取基线() 如果基础状态不存在: print(f"{Fore.RED}❌无法连接目标!") 返回 打印(f"基准:{base_status}|{base_len}字节")) # 扫描卡罗总和 = self.id_range[1] - self.id_range[0]对于 i,测试 ID in enumerate(范围(self.id_range[0], self.id_range[1]+1)):如果 test_id == self.my_id:继续 # 进度条进度 = int((i / 总数) * 30)bar = “█” * 进度 + “░” * (30 - 进度)百分比 = 整数((i / 总数) × 100)print(f"\r{Fore.CYAN}[{bar}]{pct}%|")f"测试ID:{test_id}",end="", flush=True) result = self.test_single_id(测试ID,基础长度) 如果结果:打印(f"{Fore.RED}🔴可能存在IDOR!)print(f" ID : {result['id']}")print(f" 状态 : {result['status']}")print(f" 长度 : {result['length']}")f"(差值:{result['diff']})")打印(f" 预览:"f"{result['preview'][:80]}...” self.vulnerable.append(result) time.sleep(self.delay) # 总结打印(f"{'─'*40}print(f"✅ 扫描完成!")打印(f" 测试:{total} 个ID")打印(f" 找到 : "f"{Fore.RED}{len(self.vulnerable)}"“{Style.RESET_ALL}潜在的IDOR”print(f" 错误 : {self.errors}")# 保存结果如果self.脆弱:输出文件=“idor_results.json”with open(out_file,"w")as f:json.dump(self.vulnerable, f, indent=2)print(f" 已保存 : {out_file}")returnself.vulnerable# ─── 使用方法 ────────────────────────────────如果 __name__ =="__main__":扫描仪= IDOR扫描仪(base_url ="https://target.com/api/v1/invoices",令牌=“您的认证令牌在这里”,我的ID =1050,id_range =(1000,1150),延迟=0.1# 用于避免速率限制!)扫描仪.扫描()
第4部分:多线程子域名爆破工具!
#!/usr/bin/env python3"""子域名暴力破解器 v2.0 — HackerMD快速多线程子域名发现
python import requests
导入线程来自队列的队列来自colorama的Fore、Style和init导入时间导入 jsonurllib3 已导入=False尝试:导入urllib3禁用 urllib3 警告urllib3已导入=True除了:passinit(autoreset=True)类子域名爆破器:def __init__(self, domain, wordlist_path,线程数=50,超时=5)self.domain =域名self.wordlist =self.load_wordlist(wordlist_path)self.threads = threadsself.timeout =超时self.queue =Queue()self.found =[]self.lock= threading.Lock()self.checked=0self.total = len(self.wordlist)self.start_time =Nonedef load_wordlist(self, path):尝试:with open(path,"r", errors="ignore")as f:words =[line.strip()for line in f]如果行.strip()]print(f"✅ 词表已加载:{len(words)} 个词")返回单词除了FileNotFoundError:print(f"❌ 未找到字典文件:{path}")# 默认小列表返回[“www”、“mail”、“ftp”、“admin”、“api”,“开发”、“测试”、“预发布”、“beta”、“旧版”,应用、门户、仪表板、安全、“vpn”、“内部”、“备份”、“cdn”、“博客”,商店、店铺、支持、文档、Git]def check_subdomain(self, subdomain):“检查单个子域名”url = f"https://{子域名}.{self.domain}"尝试:r = requests.get(网址,超时=self.超时,验证=False,允许重定向=True)使用self.lock:self.found.append({“子域名”:f"{子域名}.{self.domain}",“状态”:r.status_code,“长度”:len(r.text),“服务器”: r.headers.get(“服务器”,“未知”),“url”: url})# 按状态码着色:如果 r.status_code ==200:颜色=前景.绿色如果 r.status_code 在[301,302]中:颜色=前景.黄色如果 r.status_code ==403:颜色=Fore.RED否则:颜色=前景.青色打印(“{color}🔴[{r.status_code}]”“{subdomain}.{self.domain}”f"({r.headers.get('Server','')})")except requests.exceptions.ConnectionError:通过# 子域名不存在除了异常:通过最后:使用self.lock:self.checked+=1def worker(self):“线程工作者”无限循环:子域名=self.queue.get()如果子域名为空:中断self.check_subdomain(子域名)self.queue.task_done()def progress_monitor(self):“进度显示线程”当self.checked<self.total 时:百分比=整数((已选/总数)×100)已用时=当前时间-自我开始时间速度=自我检查/最大(已用时,1)打印(f"\r{Fore.CYAN}进度:{pct}% | "f"已检查:{self.checked}/{self.total} | "f"已找到:{len(self.found)} | "f"速度:{speed:.0f}/秒 ",end="", flush=True)time.sleep(0.5)def run(self):打印(f"{Fore.CYAN}╔═══════════════════════════════╗")print(f"{Fore.CYAN}║ 子域名爆破器 — HackerMD ║")print(f"{Fore.CYAN}╚═══════════════════════════════╝")打印(f"域名:{self.domain}")print(f"单词数量:{len(self.wordlist)}")打印(f"线程:{self.threads}")print("─"*42)self.start_time = time.time()# 启动工作线程线程列表=[]对于 _ 在self.线程范围内:t =线程.Thread(target=self.worker,守护进程=True)t.start()线程列表.append(t)# 填充队列对于单词in自我单词列表:self.queue.put(word)# 停止信号对于 _ 在self.线程范围内:self.queue.put(None)# 等待对于线程列表中的每个t:t.join()经过时间=时间.time()-self.start_time # 结果打印(f"{'─' * 42} print(f"✅完成!耗时:{elapsed:.1f}秒")print(f"🔴找到:{len(self.found)}个子域名”)# 按状态排序self.found.sort(key=lambda x: x["status"])对于 s 在self.found 中:print(f" [{s['status']}] {s['subdomain']}")# 保存with open(f"subs_{self.domain}.txt","w")as f:对于 s 在self.found 中:f.write(f"{s['子域名']} "f"[{s['status']}]”) with open(f"subs_{self.domain}.json", "w") as f:json.dump(self.found, f, indent=2) print(f"💾已保存:subs_{self.domain}.txt)返回self.found# ─── 用法 ────────────────────────────────如果 __name__ =="__main__":bruter =子域名爆破器(域名=“target.com”,词汇表路径=(“/usr/share/wordlists/SecLists/”发现/DNS/顶级百万子域名-5000.txt),线程=100,超时=4)布鲁特.运行()
第5部分:秘密扫描器JS文件,我的秘密!
#!/usr/bin/env python3"""秘密扫描器 v2.0 — HackerMDJS/配置文件中的API密钥、令牌和密钥
python import requests
导入正则表达式导入 json来自colorama的Fore和initinit(autoreset=True)requests.packages.urllib3.disable_warnings()#───秘密正则表达式模式────────────────模式={“AWS访问密钥”:r"AKIA[0-9A-Z]{16}",“AWS密钥”: r"(?i)aws.{0,20}secret.{0,20}['\"][0-9a-zA-Z/+]{40}['\"]",“GitHub令牌”: r"ghp_[0-9a-zA-Z]{36}",“GitHubClassic”:r"github_pat_[0-9a-zA-Z_]{82}”“Google API密钥”:r"AIza[0-9A-Za-z\-_]{35}", “Stripe密钥”:r"sk_live_[0-9a-zA-Z]{24,}", “Stripe 发布”:r"pk_live_[0-9a-zA-Z]{24,}" “Slack 令牌” : r"xox[baprs]-[0-9a-zA-Z\-]{10,48}",“Twilio SID” : r"AC[a-zA-Z0-9]{32}",“SendGrid密钥”:r“SG\.[a-zA-Z0-9\-_]{22}\.[a-zA-Z0-9\-_]{43}”, “Firebase URL”:r"https://[a-z0-9-]+\.firebaseio\.com",“JWT 令牌”: r"eyJ[A-Za-z0-9\-_=]+\.[A-Za-z0-9\-_=]+\.?[A-Za-z0-9\-_.+/=]*",“私钥”: r"-----BEGIN (?:RSA |EC )?PRIVATE KEY",“数据库连接”:r"(?:mysql|postgres|mongodb|redis|mssql)://[^\s\"'<>]+"“通用密钥”:r"(?i)(?:secret_key|api_key|apikey|access_token|auth_token)\s*[=:]\s*['\"]([^'\"]{10,})['\"]"“通用密码”:r"(?i)(?:password|passwd|pwd)\s*[=:]\s*['\"]([^'\"]{6,})['\"]",}#───敏感文件路径──────────────────敏感路径=[/.env、/.env.local、/.env.production、/.env.backup、/config.js、/config.json、“/settings.py”、“/app.js”、“/main.js”,“/bundle.js”,“/webpack.config.js”,“/api/config”,“/api/settings”,/.git/config,/web.config,“/phpinfo.php”,“/info.php”,“/server-status”,“/server-info”,“/actuator/env”,“/actuator/configprops”,“/api/v1/config”,“/api/v2/config”,]类SecretScanner:def __init__(self, domain):self.domain = domainself.base_url = f"https://{domain}"self.session = requests.Session()self.session.verify =Falseself.session.headers.update({“用户代理”:Mozilla/5.0(X11;Linux x86_64)})self.findings =[]self.js_urls =[]def extract_js_urls(self):“从主页获取JS文件URL”尝试:r =self.session.get(self.base_url,超时=10)# src="..." 模式模式= r'src=["\']([^"\']*\.js(?:\?[^"\']*)?)["\']'匹配项= re.findall(模式, r.text)对于 m 在匹配项中:如果 m 以“http”开头:self.js_urls.append(m)如果 m 以“//”开头:self.js_urls.append(f"https:{m}")elif m.startswith("/"):self.js_urls.append(f"{self.base_url}{m}")print(f"✅ 找到 {len(self.js_urls)} 个 JS 文件")除了Exception作为 e:print(f"❌ 提取JS时出错:{e}")def scan_content(self, content, source):“在内容中寻找秘密”已找到此处=[]对于 secret_type, pattern in PATTERNS.items():匹配= re.findall(模式,内容)对于比赛中的每场比赛:值=匹配如果 isinstance(匹配, str) \否则返回 match[0],如果 match 为空则返回空字符串。如果长度大于等于8:查找={“类型”:密钥类型,“值”:val[:60]+(“…”if len(val)>60else“”),“来源”:来源}如果未在self.findings中找到:self.findings.append(发现)已找到的添加到此处.append(发现)打印(f" {Fore.RED}🔴 {secret_type}"f”{val[:55]}...)返回已找到def扫描_js文件(self):扫描所有JS文件打印(f"{Fore.YELLOW}[2/3] 正在扫描JS文件...)对于 self.js_urls 中的每个 URL:# 最多 20 个文件尝试:r = self.session.get(url, timeout=8)文件名 = URL.split("/")[-1].split("?")[0] print(f"检查:{fname[:40]}") self.scan_content(r.text, url)除了:通过 def scan_sensitive_paths(self):“检查敏感路径” 打印(f"{Fore.YELLOW}[3/3]正在扫描敏感路径...对于路径in敏感路径:url = f"{self.base_url}{path}"尝试:r =self.session.get(网址,超时=5,允许重定向=False)如果 r.status_code ==200:大小= len(文本)打印(f" {Fore.GREEN}✅ [200] "“{path}({size}字节)”)self.scan_content(r.text, url)# .env 是否泄露? 如果路径中包含“.env”且大小大于10:打印(f" {Fore.RED}🔴🔴 "f“.ENV文件已暴露!{url}”)除了:传递def run(self):打印(f"{Fore.CYAN}╔══════════════════════════════╗)print(f"{Fore.CYAN}║密码扫描器—HackerMD║")print(f"{Fore.CYAN}╚══════════════════════════════╝")打印(f"目标:{self.domain}")) print(f"{Fore.YELLOW}[1/3]提取JS文件...") self.extract_js_urls()self.scan_js_files()self.scan_sensitive_paths() # ─── 最终报告 ─────────────────打印(f"{'─'*42}**print(f"✅ 扫描完成!")print(f" 找到的密钥:"f"{Fore.RED}{len(self.findings)}")如果self.findings:out= f"secrets_{self.domain}.json"with open(out,"w")as f:json.dump(self.findings, f, indent=2)print(f" 已保存:{out}")# 按类型汇总打印(f"{Fore.RED}📋 摘要:) 类型 = {}对于 f_item in self.findings:t = f_item["类型"]types[t] = types.get(t, 0) + 1对于 t,计数 in types.items():print(f"{t}:{count}") return self.findings# ─── 使用方法 ────────────────────────────────如果 __name__ == "__main__":导入系统域名 = sys.argv[1] 如果 len(sys.argv) > 1 \否则“target.com”扫描器 = 秘密扫描器(域名)扫描仪运行()
第6部分:异步扫描速度提升10倍!
#!/usr/bin/env python3"""异步URL扫描器 — HackerMDaiohttp 10倍速并行扫描
python import asyncio
导入aiohttp导入 json导入时间from colorama importFore, initinit(autoreset=True)asyncdef check_url(session, url, semaphore):“单URL异步检查”异步使用信号量:尝试:异步与会话.get(网址,超时=aiohttp.ClientTimeout(总超时=6),ssl=False,允许重定向=False)作为回应:文本=await resp.text(错误="忽略")返回{“url”: url,“状态”:resp.状态,“长度”:len(文本),“服务器”:resp.headers.get(“服务器”,“”),“标题”:文本[text.find("<title>")+7:文本.find("</title>")[:60]如果“<title>”在文本中,则返回;否则返回空字符串。}除了:返回Noneasyncdef async_scan(urls, max_concurrent=150,仅限有趣=True):“并行扫描所有URL”信号量= asyncio.Semaphore(最大并发数)连接器= aiohttp.TCPConnector(限制=最大并发,SSL=False)结果=[]打印(f"{Fore.CYAN}╔══════════════════════════════╗)print(f"{Fore.CYAN}║异步扫描器—HackerMD║")print(f"{Fore.CYAN}╚══════════════════════════════╝")print(f"URLs:{len(urls)}")打印(f"并发:{max_concurrent}") print("─" * 42) 开始 = 时间.time() 异步 with aiohttp.ClientSession(连接器=连接器,headers={"User-Agent": "Mozilla/5.0"}) 作为会话:任务 = [检查URL(会话,URL,信号量)对于url in urls]responses = await asyncio.gather(*任务,返回异常=True) for resp in responses:如果 resp 为空或 resp 是异常类型: 继续 状态 = 响应["状态"]如果仅限有趣且 \状态不在 [200, 301, 302, 403] 中:继续 results.append(响应) # 按状态着色:如果状态码等于200:颜色 = 前景.绿色如果状态码为403:颜色 = Fore.RED如果状态在[301, 302]中:颜色 = 前景.黄色否则:颜色 = 红色.青色 打印(“{color}[{status}] ”f"{resp['length']:6d}字节|"f"{resp['url']}"+ (f"|{resp['title']}")如果 resp['title'] 不存在,则返回空字符串) 经过时间 = 时间.time() - 开始速度 = URL数量 / 最大(已用时,0.1) print(f"{'─'*42}print(f"✅ 完成!耗时:{elapsed:.2f}秒 | ")f"速度:{speed:.0f} 请求/秒")print(f"找到:{len(results)} 个有趣的URL")return results# ─── 使用方法 ────────────────────────────────如果 __name__ =="__main__":基础=“https://target.com”路径=[“/admin”、“/api/v1/users”、“/dashboard”,/.env、/.git/HEAD、/swagger.json、“/api-docs”、“/actuator”、“/debug”“/config”、“/backup”、“/phpinfo.php”,“/api/v2/users”,“/internal/admin”“/api/v1/config”,“/api/health”,]urls =[f"{BASE}{p}"for p in PATHS] results = asyncio.run(异步扫描(urls,最大并发=100))# 保存with open("async_results.json","w")as f:json.dump(结果, f,缩进=2)
第7部分:完成侦察管道,萨布组合!
#!/usr/bin/env python3"""完整侦察流程 v2.0 — HackerMD通过命令实现全面的侦察自动化!
python import subprocess
导入 requests导入 json导入 os导入 asyncio导入aiohttp从 datetime import datetime来自colorama的Fore和initinit(autoreset=True)requests.packages.urllib3.disable_warnings()类ReconPipeline:def __init__(self, domain):self.domain = domainself.ts = datetime.now().strftime(“%Y%m%d_%H%M”)self.out_dir = f"recon_{domain}_{self.ts}"os.makedirs(self.out_dir, exist_ok=True)self.session = requests.Session()self.session.verify =Falseself.results ={“域名”:域名,“时间戳”:self.ts,“子域名”:[],“live_hosts”:[]“秘密”:[]“有趣”:[],“技术”:[]}def run_cmd(self, cmd, timeout=60):“运行Shell命令”尝试:输出=子进程.run(命令,shell=True,捕获输出=True,文本=真,超时=超时)返回out.stdout.strip()除 subprocess.TimeoutExpired以外:返回“”除了异常:返回“”# ─── 第1步:子域名发现 ──────def step1子域名(self):打印(f"{Fore.CYAN}[1/5] 🌐 子域名发现)out_file = f"{self.out_dir}/subdomains.txt" output = self.run_cmd(f"subfinder -d {self.domain}-silent 2>/dev/null") 如果输出:subs = [s for s in output.split('') 如果 s]self.results["子域名"] = 子域名列表with open(out_file, "w") as f:f.write(输出)print(f"✅找到:{len(subs)}个子域名") 否则:常见 = [f"www.{self.domain}",f"api.{self.domain}",f"dev.{self.domain}",f"admin.{self.domain}",f"邮件.{self.domain}",f"暂存.{self.domain}",]self.results["子域名"] = 公共with open(out_file, "w") as f:f.write("“.join(公共)”print(f" ⚠️ subfinder 未找到 — "f"使用 {len(common)} 个公共子串")# ─── 第二步:实时主机过滤 ──────def step2_live_hosts(self):打印(f"{Fore.CYAN}[2/5] 🔥 直播主持人检查)子文件 = f"{self.out_dir}/subdomains.txt"live_file = f"{self.out_dir}/live_hosts.txt" 如果子文件不存在:打印("❌子域名文件缺失!") 返回 live_out = self.run_cmd(f"猫{sub_file}| httpx -silent "f"-mc 200,301,302,4032>/dev/null",超时=120) 如果 live_out:主机 = [h for h in live_out.split('') 如果 h]self.results["live_hosts"] = 主机with open(live_file, "w") as f:f.write(直播输出)print(f"✅在线主机:{len(hosts)}")否则:print("⚠️ httpx未找到——跳过") # ─── 第3步:技术检测───────────def step3_技术检测(self):打印(f"{Fore.CYAN}[3/5]🔍技术检测)尝试:r =self.session.get(f"https://{self.domain}",超时=10)技术=[]headers = r.headers 服务器= headers.get("Server","")如果服务器:techs.append(f"服务器:{server}")如果“X-Powered-By”在标头中:技术员.append(f"由 {headers['X-Powered-By']} 提供支持")如果“X-Generator”在标头中:技术员.append(f"生成器:{headers['X-Generator']}")正文= r.text.lower()如果“wp-content”在正文中:技术栈.append("WordPress")如果“drupal”在正文中:技术栈.append("Drupal")如果正文包含“react”或“__react”:techs.append("ReactJS")如果“angular”在正文中:技术栈.append("AngularJS")如果“laravel”在正文中:技术栈.append("Laravel")如果“django”在正文中:techs.append("Django")缺失=[]for h in["内容安全策略",X-框架选项,X-XSS-保护,“严格传输安全”:如果 h 不在 headers 中:missing.append(h)self.results["technologies"]= techs如果缺失:self.results["interesting"].append(f“缺少安全标头:”f"{', '.join(missing)}")for技术in技术们:打印(f" 📦 {t}")如果缺失:print(f" {Fore.YELLOW}⚠️ 缺失的标题:")f"{len(missing)}")除了Exceptionas e:print(f" ❌ 错误:{e}")# ─── 第4步:快速密钥扫描 ────────def step4_secrets(self):打印(f"{Fore.CYAN}[4/5] 🔑 快速秘密扫描)导入 re 快速模式 = {“AWS密钥”:r“AKIA[0-9A-Z]{16}”, “GitHub” : r"ghp_[0-9a-zA-Z]{36}",“Stripe”:r"sk_live_[0-9a-zA-Z]{24}",“谷歌API”:r"AIza[0-9A-Za-z\-_]{35}", “JWT” : r"eyJ[A-Za-z0-9\-_=]{10,}\.",} 检查网址 = [f"https://{self.domain}/.env",f"https://{self.domain}/config.js",f"https://{self.domain}/main.js",]for url in check_urls:尝试:r =self.session.get(url, timeout=6)如果 r.status_code ==200:对于名称,模式in \快速模式.项():匹配= re.findall(模式,r.text)对于 m 在 matches 中:查找=(“{name}在{url}:”“{m[:30]}…”)self.results[秘密].追加(发现)打印(f" {Fore.RED}"f"🔴 {finding}")除了:通过如果self.results["secrets"]为空:print(f" {Fore.GREEN}✅ 没有发现快速秘诀")# ─── 第5步:生成报告 ──────────def step5_report(self):打印(f"{Fore.CYAN}[5/5] 📝 生成报告”) report = f"{self.out_dir}/recon_report.json"with open(report, "w") as f:json.dump(self.results, f, indent=2) print(f"{Fore.CYAN}╔══════════════════════════════════╗")print(f"{Fore.CYAN}║侦察完成—HackerMD║")print(f"{Fore.CYAN}╚══════════════════════════════════╝")print(f"🌐子域名:")f"{len(self.results['subdomains'])}"print(f"🔥实时主播:")f"{len(self.results['live_hosts'])}"print(f"📦技术:"f"{len(self.results['technologies'])}"print(f"🔑找到的密钥:")f"{Fore.RED}"f"{len(self.results['secrets'])}"print(f"📍有趣:")f"{len(self.results['interesting'])}"打印(f"💾报告:{report})print(f" 📂 目录 : {self.out_dir}/")def run(self):打印(f"{Fore.CYAN}{'═' * 42}**print(f"{Fore.CYAN}🚀侦察管道—HackerMD")print(f"目标:{self.domain}") print(f"{Fore.CYAN}{'═'*42}") self.step1_subdomains()self.step2_实时主机()self.step3_tech_detect()self.step4_secrets()self.step5_report()# ─── 使用方法 ────────────────────────────────如果 __name__ == "__main__":导入系统域名 = sys.argv[1] 如果 len(sys.argv) > 1 \否则“example.com”管道 = 重建管道(域名)流水线运行()
只需一条命令,搞定一切!
python3 recon_pipeline.py target.com
工具概要
工具|用例|文件-------------------|----------------------|--------------------IDOR扫描器| IDOR ID测试| idor_scanner.py子域名爆破器|子域名暴力破解| sub_bruter.pySecretScanner| JS/.env 中的 API 密钥| secret_scanner.py异步扫描器|快速批量URL检查| async_scanner.py重建管道|全自动化|重建管道.py
今天的作业
# 1. 环境搭建:python3 -m venv bugenv来源 bugenv/bin/activatepip 安装 requests aiohttp colorama rich tqdm# 2. 测试 Secret Scanner(合法目标!):python3 secret_scanner.py testphp.vulnweb.com# 3. 异步扫描器测试:python3 async_scanner.py# 在URL列表中添加httpbin.org路径# 4. 运行侦察流水线:python3 recon_pipeline.py hackerone.com# (仅公开信息——合法!)# 5. 升级您的Apna:在IDORScanner中添加 UUID 支持。# 在SecretScanner中添加Slack webhook模式# 将SubdomainBruter的DNS解析添加到您的DNS中
快速复习
🐍Python=漏洞赏金自动化利器!📦库= requests, aiohttp, colorama,丰富,tqdm,json🔍 IDOR扫描器= ID范围→不同响应= IDOR!🌍SubBruter=线程+字典=快速!🔑SecretScan=正则表达式模式→ JS/.env 密钥⚡异步扫描器= aiohttp + asyncio =10倍速度!🚀流程=萨布组合=全自动侦察!💰结果=自定义工具=独特漏洞=重复次数越少,奖励越多!
我的谈话……
起初,我都是手动测试每个端点的。
目标在6到8小时内完成。 Python自动化之后:
python3 recon_pipeline.py target.com
15分钟内:
- 发现847个子域名
- 134位直播主持人
- 暴露了 3 个
.env 文件! - 找到 2 个管理面板(403)
在我的 .env 文件中:
STRIPE_SECRET=sk_live_xxxxxxxxxxxxxxxxxxAWS_ACCESS_KEY_ID=AKIAXXXXXXXXXXXXXXXXDB_PASSWORD=超级秘密2024!
手册卡片需要2到3天!3份独立报告:
.env 泄露 = 2,500 美元- AWS密钥 = 3,200美元
- 条纹密钥 = 1,500美元
总计:15分钟自动化操作,节省7,200美元! 🎉
课程:在Python中投资一次,打造一个工具,反复使用,回报率无限! 在另一篇文章中,我将向大家介绍Gemini CLI + AI漏洞狩猎,打造2026年最强大的AI助手组合!🤖🔥



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
