大模型返回的数据里有一堆多余的空格和换行符,需要清理;或者你有一个时间戳 1745678400,需要转成"2025年4月27日"给用户看;或者你从知识库拿到了一段文字,想提取里面所有的数字;这些操作,大模型节点做不精准,文本处理节点功能不够,变量聚合节点不适合……你打开代码节点,看到一个空白的编辑框,第一反应是:
一、先破除一个迷信
"代码节点是给程序员用的"——这个想法,让很多人白白放弃了工作流里最灵活的一个工具。代码节点本质上就是一个"按你的规则处理数据"的工位。你不需要从零学编程,你需要的只是——把你的需求描述清楚,让AI帮你写代码,你粘贴进去,跑通就行。这就是今天要讲的核心用法:代码节点 + AI生成代码 = 不会编程也能用的超级数据处理器。说白了,你负责"提需求",AI负责"写代码",你负责"把代码搬进去"。
二、代码节点的基本结构,看一眼就记住
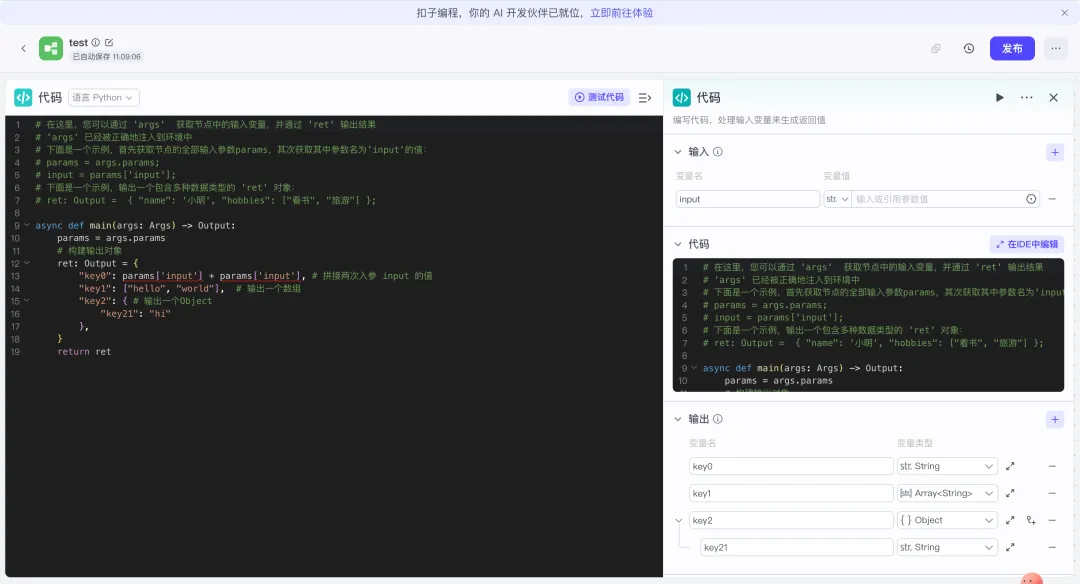
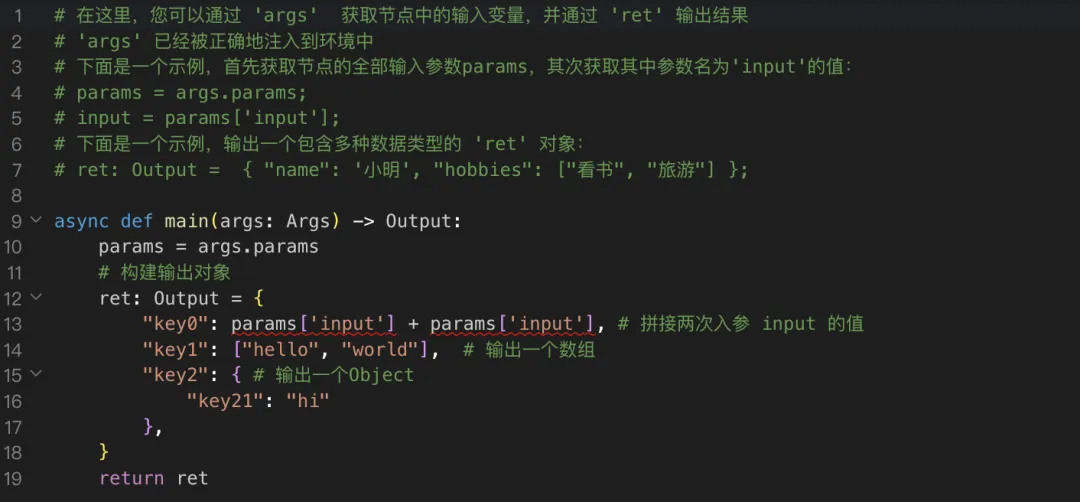
Coze代码节点支持Python和JavaScript两种语言,今天我们用Python。不管你要做什么,Python代码节点的结构永远是这样的:async def main(args: Args) -> Output: params = args.params # 你的处理逻辑写在这里 return Output(...)
从工作流上游传进来的变量,通过 params.变量名 来取:# 比如上游传进来一个叫 inputText 的变量text = params.inputText
处理完的结果,通过 return Output(...) 传出去:return Output(result="处理完的内容")
记住这个结构,后面不管AI给你生成什么代码,你都能看懂往哪里嵌。
三、怎么让AI帮你写代码?
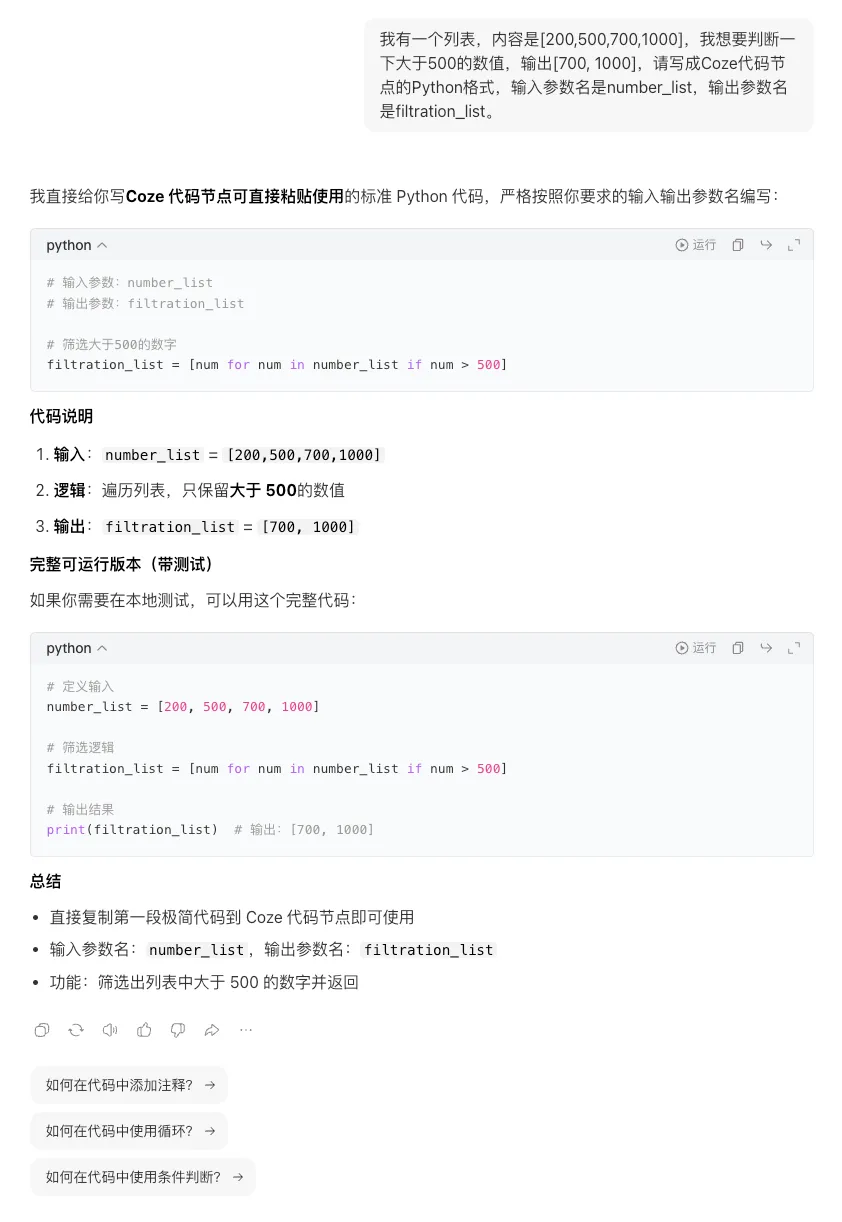
很多人问AI"帮我写个Python代码",结果拿到一堆看不懂的东西,不知道怎么用。"我有一个[数据类型],内容是[具体例子],我想要[具体操作],输出[期望结果],请写成Coze代码节点的Python格式,输入参数名是XXX,输出参数名是XXX。"
❌ 模糊版:帮我写个处理字符串的Python代码
✅ 具体版:我有一个字符串变量叫 inputText,内容比如是 " 你好,世界! ",我想去掉首尾的空格,然后把所有标点符号替换成空字符串,输出清理后的文本,输出参数名叫 cleanText。请写成Coze代码节点的Python格式。
描述越精准,AI给你的代码越能直接用,越不需要你自己改。
四、八个最常用的数据处理场景
下面我把最高频的数据处理需求,逐一说清楚——包括场景描述、给AI的提示词、以及代码示例。你收藏这一段,以后遇到对应需求,照着给AI说就行。
场景一:清理文本(去空格、去乱码、统一格式)
大模型有时候输出内容里有多余的换行符、首尾空格、奇怪的符号。传给下一个节点之前,需要先清理干净。我有一个字符串变量 inputText,需要:去掉首尾空格、把多个连续空格压缩成一个、去掉所有换行符、去掉中文标点(句号逗号等),输出清理后的字符串,参数名 cleanText。Coze Python格式。
import reasync def main(args: Args) -> Output: params = args.params text = params.inputText # 去首尾空格 text = text.strip() # 多个空格压缩成一个 text = re.sub(r' +', ' ', text) # 去掉换行符 text = text.replace('\n', '').replace('\r', '') # 去掉中文标点 text = re.sub(r'[,。!?、;:""''【】()]', '', text) return Output(cleanText=text)
场景二:时间戳转可读日期
API返回的时间通常是时间戳(一串数字),需要转成"2025年4月27日 15:30"这种人能看懂的格式。我有一个整数变量 timestamp,是Unix时间戳,比如 1745678400,需要转换成"2025年04月27日 15:30:00"格式的字符串,输出参数名 formattedDate。Coze Python格式。
from datetime import datetimeasync def main(args: Args) -> Output: params = args.params timestamp = params.timestamp # 时间戳转datetime对象 dt = datetime.fromtimestamp(int(timestamp)) # 格式化成字符串 formatted = dt.strftime('%Y年%m月%d日 %H:%M:%S') return Output(formattedDate=formatted)
场景三:从文本里提取数字
用户输入"我想要3个方案"、"预算大概50000块",你需要把里面的数字单独取出来做计算或判断。我有一个字符串变量 inputText,比如 "预算大概50000块,需要3个方案",需要提取出所有数字(整数和小数都要),返回一个数字列表,输出参数名 numbers。Coze Python格式。
import reasync def main(args: Args) -> Output: params = args.params text = params.inputText # 提取所有数字(包括小数) numbers = re.findall(r'\d+\.?\d*', text) # 转成浮点数列表 numbers = [float(n) for n in numbers] return Output(numbers=numbers)
场景四:列表去重 + 排序 + 截取前N条
从多个地方收集来的数据有重复,需要去重;或者有一堆结果,只需要前五条最相关的。我有一个字符串列表变量 inputList,比如 ["苹果","香蕉","苹果","橙子","香蕉","葡萄"],需要去重、按字母顺序排序、只保留前3条,输出参数名 resultList。Coze Python格式。
async def main(args: Args) -> Output: params = args.params input_list = params.inputList # 去重(保持Python内部顺序) unique_list = list(dict.fromkeys(input_list)) # 排序 unique_list.sort() # 只取前3条 result = unique_list[:3] return Output(resultList=result)
场景五:JSON字符串解析,提取指定字段
HTTP请求节点返回的body是一个JSON字符串,需要取出里面某个字段的值传给下一个节点。我有一个字符串变量 jsonStr,内容是JSON格式,比如 '{"city":"北京","weather":"晴","temperature":28,"humidity":45}',需要分别提取 city、weather、temperature 三个字段,输出三个独立参数。Coze Python格式。
import jsonasync def main(args: Args) -> Output: params = args.params json_str = params.jsonStr # 解析JSON字符串 data = json.loads(json_str) # 提取字段,用get避免KeyError city = data.get('city', '') weather = data.get('weather', '') temperature = data.get('temperature', 0) return Output( city=city, weather=weather, temperature=temperature )
场景六:计算和数学处理
需要做一些数学计算:算平均值、算总和、算百分比、四舍五入……大模型做数学不可靠,代码节点做数学100%准确。我有一个数字列表变量 scores,比如 [85, 92, 78, 96, 88],需要计算平均分(保留一位小数)、最高分、最低分、总分,输出四个参数。Coze Python格式。
async def main(args: Args) -> Output: params = args.params scores = params.scores total = sum(scores) average = round(total / len(scores), 1) highest = max(scores) lowest = min(scores) return Output( total=total, average=average, highest=highest, lowest=lowest )
场景七:字符串分割和重组
大模型输出了一段用特定符号分隔的内容,需要把它切开变成列表;或者有一个列表,需要按照特定格式拼成一段话。我有一个字符串变量 inputStr,内容是用"|"分隔的多个词,比如 "人工智能|机器学习|深度学习|自然语言处理",需要切成列表,然后给每个词加上序号和"·"前缀,重新拼成一段文字,每个词换行,输出参数名 formattedText。Coze Python格式。
async def main(args: Args) -> Output: params = args.params input_str = params.inputStr # 按|切割 items = input_str.split('|') # 给每个词加序号和前缀,换行拼接 formatted_lines = [f"{i+1}· {item.strip()}" for i, item inenumerate(items)] formatted_text = '\n'.join(formatted_lines) return Output(formattedText=formatted_text)
场景八:条件判断和数据分类
你有一个分数或者数值,需要根据范围判断等级;或者根据输入内容的某个特征,把它归到不同的类别里。我有一个数字变量 score,需要根据分数区间输出等级:90以上是"优秀",75-89是"良好",60-74是"及格",60以下是"不及格"。输出参数名 grade。Coze Python格式。
async def main(args: Args) -> Output: params = args.params score = params.score if score >= 90: grade = "优秀" elif score >= 75: grade = "良好" elif score >= 60: grade = "及格" else: grade = "不及格" return Output(grade=grade)
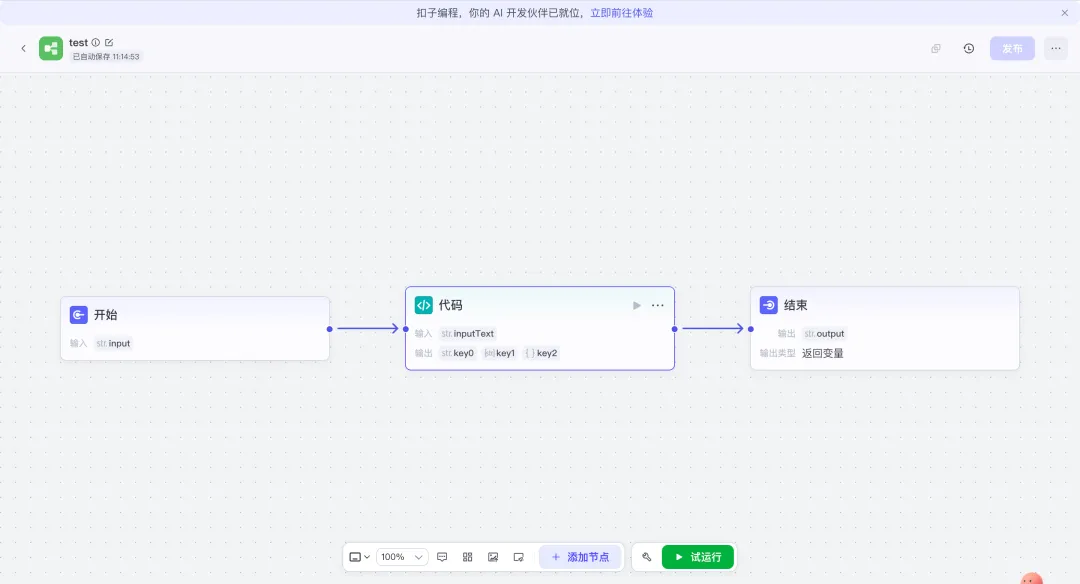
五、配置节点的完整步骤
拿到AI生成的代码之后,怎么配进Coze?四步走:在工作流画布里,添加节点 → 选"业务逻辑" → "代码节点",拖进来。点开节点,在左侧"输入"区域,添加你的输入变量,变量名要和代码里 params.变量名 保持一致。在右侧"输出"区域,添加和 return Output(...) 里对应的输出参数名。然后点"测试",填入测试数据,跑一遍,看输出结果对不对。
六、AI生成代码跑不通怎么办?
这是新手最常遇到的问题。代码粘进去,一跑报错,不知道怎么办。代码节点运行失败会显示报错信息,把这段报错信息完整复制下来。"这段代码运行报错了,报错信息是:[粘贴报错内容],帮我找出问题并修复。"
最常见的报错原因:代码里写的 params.inputText,但你在输入配置里添加的变量名是 input_text(有下划线)——名字对不上,就会报找不到变量的错。确认代码里的变量名和输入配置里的变量名完全一致,大小写也要一样。
七、一个进阶技巧:把代码节点当"万能转换器"
掌握了基本用法之后,你会发现代码节点最大的价值,是充当不同格式之间的"翻译官"。你可以把代码节点理解为工作流里的"万能适配器"——当两个节点之间数据格式对不上、或者需要做一些定制化的加工,就在中间插一个代码节点,写三五行逻辑,问题解决。
常见坑,提前帮你踩
return Output(cleanText=text) 但输出配置里添加的参数名叫 clean_text——名字对不上,下游节点引用不到值。上游传进来的 score 可能是字符串 "85",不是数字 85,直接做数学运算会报错。需要先转换:score = int(params.score) 或 score = float(params.score)。有时候上游传进来的Array,在代码节点里拿到的是一个字符串格式的列表(比如 "['苹果', '香蕉']"),需要先用 json.loads() 转成真正的列表再操作。Coze代码节点支持Python内置库(json、re、datetime、math等),但不支持pip安装的第三方库(比如pandas、numpy)。遇到报错说找不到某个库,先问AI有没有用内置库实现的替代方案。
总结
一句话记住核心:代码节点不是程序员专属的工具,它是"按你的规则处理数据"的工位——你负责把需求描述清楚,AI负责生成代码,你负责把代码粘进去跑通。不会写代码不是障碍,描述不清楚才是。八个高频场景(清理文本、时间戳转换、提取数字、列表处理、JSON解析、数学计算、字符串分割、条件分类),用今天给的提示词模板告诉AI,拿到代码,三分钟配好节点。从最简单的场景练手:找一个你目前工作流里"数据格式对不上"的地方,用今天的方法让AI生成一段代码,插进去,跑通一次——你就会发现,代码节点其实没有你想象的那么难。下期打算聊:Coze工作流里那些让你百思不得其解的报错,逐一拆解——遇到红色节点不用慌,看完这期你能自己排查80%的问题。
不会写代码不是问题,问题是你有没有试过让AI帮你写——点个在看,咱们下期见 😄


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
