数据缺失直接删除或统一填充会失真,进阶分析需要根据字段类型,使用差异化方案精准补全。场景:用户数据包含数值缺失、文本缺失、时间缺失,根据字段业务属性差异化填充。核心知识点:缺失值分布统计、按类型填充、ffill向前填充、缺失比例可视化判断。① 生成测试数据
import pandas as pdimport numpy as npdf = pd.DataFrame({ "user_id": range(1,101), "pay_money": np.random.normal(200,80,100), "user_type": np.random.choice(["普通","会员","VIP"],100), "login_date": pd.date_range("2025-01-01",periods=100,freq="D")})# 手动制造不同类型缺失df.loc[10:20,"pay_money"] = np.nandf.loc[30:40,"user_type"] = np.nandf.loc[60:70,"login_date"] = np.nandf.to_excel("miss_data.xlsx", index=False)print("多类型缺失值测试数据已生成")
② 核心代码
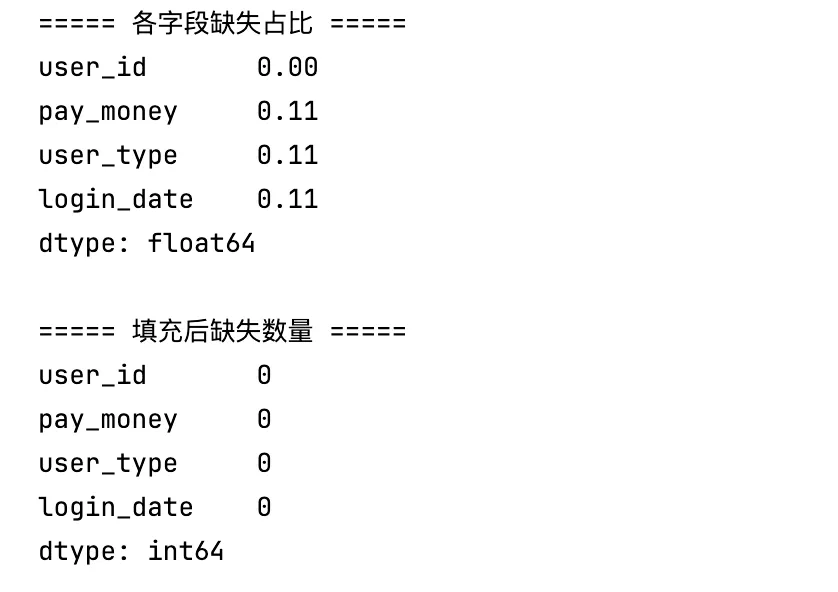
import pandas as pddf = pd.read_excel("miss_data.xlsx")# 统计缺失比例print("===== 各字段缺失占比 =====")print((df.isnull().sum() / len(df)).round(3))# 差异化填充df["pay_money"] = df["pay_money"].fillna(df["pay_money"].mean()) # 数值:均值填充df["user_type"] = df["user_type"].fillna(df["user_type"].mode()[0]) # 文本:众数填充df["login_date"] = df["login_date"].fill() # 时间:向前填充print("\n===== 填充后缺失数量 =====")print(df.isnull().sum())
结果展示
总结
差异化缺失值填充贴合业务逻辑,避免一刀切处理导致的数据偏差,是高质量数据分析、模型预处理的标准流程,实用性极强。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
