大家好,我是木木。
今天给大家分享一个清爽的 Python 库,html2text。
html2text
很多内容处理流程都会遇到一个小麻烦:网页是 HTML,但后续更想要 Markdown 或纯文本。html2text 做的事情很直接,把标题、链接、列表、强调和代码块尽量转成清爽可读的 Markdown,方便归档、摘要、知识库同步或喂给下游模型。
项目地址:https://github.com/Alir3z4/html2text
官方文档:https://github.com/Alir3z4/html2text/blob/master/docs/usage.md
三大特点
输出清爽
它会把常见 HTML 标签转换成 Markdown 结构,结果比直接取纯文本更保留语义。
配置直接
链接、图片、自动换行、代码块标记等行为都能通过 HTML2Text 对象调整。
接入轻量
不需要启动浏览器,也不依赖复杂渲染流程,适合放在清洗脚本、爬虫后处理和内容导入任务里。
最佳实践
安装方式:python -m pip install html2text==2025.4.15
建议把它放在“HTML 已经拿到之后”的处理环节:先负责抓取或读取 HTML,再用 html2text 做 Markdown 转换,最后再做去重、摘要或入库。
功能一:把 HTML 转成 Markdown
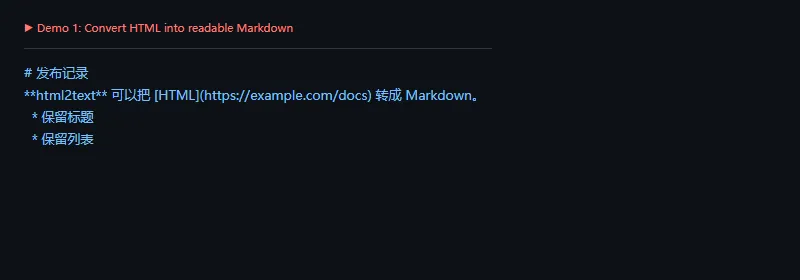
这段代码解决什么问题:把标题、加粗、链接和列表转成 Markdown,保留基本语义,方便后续进入知识库或文档系统。
importhtml2texthtml="""<article><h1>发布记录</h1><p><strong>html2text</strong> 可以把 <a href="https://example.com/docs">HTML</a> 转成 Markdown。</p><ul><li>保留标题</li><li>保留列表</li></ul></article>"""markdown=html2text.html2text(html).strip()print(markdown)
这个默认输出已经适合很多简单场景。如果你要做长期内容同步,建议把转换前 HTML 和转换后 Markdown 都留样本,方便发现页面结构变化。
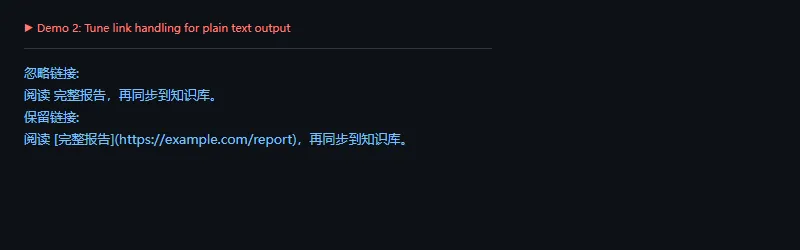
功能二:控制链接输出方式
这段代码解决什么问题:有些流程只要纯文本,不想保留 URL;有些流程则必须保留链接来源。ignore_links 可以让同一段 HTML 按不同用途输出。
importhtml2texthtml='<p>阅读 <a href="https://example.com/report">完整报告</a>,再同步到知识库。</p>'converter=html2text.HTML2Text()converter.body_width=0converter.ignore_links=Trueprint("忽略链接:")print(converter.handle(html).strip())converter.ignore_links=Falseprint("保留链接:")print(converter.handle(html).strip())
我的习惯是:给摘要任务保留可读文本,给溯源和归档任务保留链接。不要在同一个输出里同时满足所有场景,后面会越来越难维护。
环境与版本信息
- Demo 环境:Windows 11,Python 3.11
- 本文安装的
html2text 版本:2025.4.15 - 主要能力:HTML 转 Markdown、链接处理、图片处理、代码块标记、正文换行控制
- GitHub 最近一次推送时间:
2025-10-28T11:03:41Z
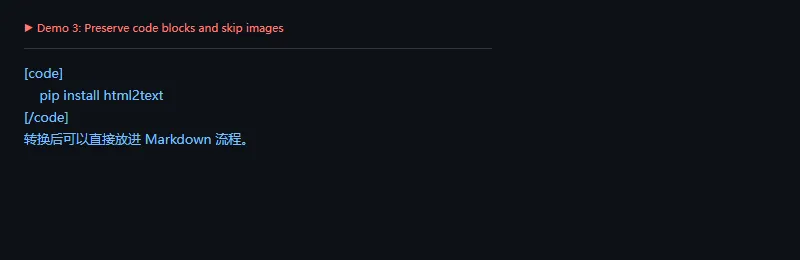
高级功能
这段代码解决什么问题:内容归档时,图片可能已经由别的流程处理,但代码块需要保留。通过 ignore_images 和 mark_code 可以让输出更贴合 Markdown 流水线。
importhtml2texthtml="""<section><img src="hero.png" alt="首图"><pre><code>pip install html2text</code></pre><p>转换后可以直接放进 Markdown 流程。</p></section>"""converter=html2text.HTML2Text()converter.body_width=0converter.ignore_images=Trueconverter.mark_code=Truemarkdown=converter.handle(html).strip()print(markdown)
如果你的内容里有复杂表格、交互组件或脚本生成内容,html2text 只负责转换已有 HTML,不负责还原浏览器渲染结果。这一点要提前和抓取层分清楚。
适用场景
- 你已经拿到 HTML,需要转成 Markdown 或可读文本
- 你要把网页内容同步到知识库、文档库、摘要任务或搜索索引
不适用场景
- 页面内容依赖 JavaScript 渲染,原始 HTML 里没有正文
- 你需要完整保留页面视觉布局、CSS 样式或复杂表格
上线检查
- 先确定 HTML 来源是否稳定,动态页面要先由抓取层渲染或调用接口。
- 为不同下游准备不同配置,比如摘要版、归档版和带链接版。
- 抽样检查标题、链接、列表、代码块和图片处理结果,避免语义丢失。
总结
html2text 是一个很清爽的 HTML 转 Markdown 工具。它不负责抓网页,也不追求复刻视觉布局,但很适合把网页内容变成更容易阅读、存储和继续处理的文本。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
