大家好,我是木木。
今天给大家分享一个灵巧的 Python 库,micawber。
micawber
内容平台经常会遇到这种需求:用户贴了一个视频、图片或音频链接,页面里不能只显示 URL,而是要变成可预览的嵌入卡片。micawber 就是围绕这类富媒体链接处理设计的,它可以识别链接、请求 provider 元数据,并把文本或 HTML 里的链接替换成嵌入内容。
项目地址:https://github.com/coleifer/micawber
官方文档:https://micawber.readthedocs.io
三大特点
富媒体聚焦
它主要处理 oEmbed 这类富媒体链接,把普通 URL 转成标题、缩略图、iframe 或其它嵌入 HTML。
规则清楚
通过正则把 URL 匹配到对应 provider,适合按平台管理不同的视频、图片或内容源。
替换灵巧
既能直接请求单个 URL 的元数据,也能解析整段文本或 HTML,把匹配到的链接替换成富媒体内容。
最佳实践
安装方式:python -m pip install micawber==0.6.2
真实项目里,外部 provider 可能会超时、限流或返回不完整数据。建议把 provider 请求、缓存、白名单和 HTML 安全过滤分开做,不要把远端返回直接无条件塞进页面。
功能一:注册 Provider 并获取元数据
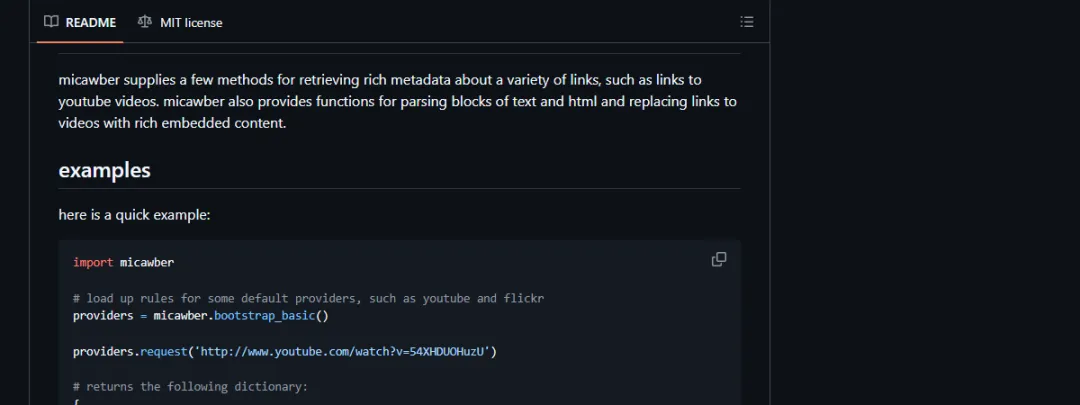
这段代码解决什么问题:先定义一个本地 provider,模拟 oEmbed 返回结果,再通过 URL 正则把链接路由到对应 provider。这样可以在不访问外网的情况下理解 micawber 的核心模型。
frommicawberimportProvider,ProviderRegistryclassLocalVideoProvider(Provider):defrequest(self,url,**extra_params):slug=url.rstrip("/").split("/")[-1]return{"type":"rich","provider_name":"ExampleVideo","title":f"演示视频 {slug}","url":url,"html":f'<iframe src="https://player.example.com/{slug}" width="560" height="315"></iframe>',"width":560,"height":315,}providers=ProviderRegistry()providers.register(r"https://video\.example\.com/watch/.+",LocalVideoProvider("https://provider.example.com/oembed"))info=providers.request("https://video.example.com/watch/intro")print("服务商:",info["provider_name"])print("标题:",info["title"])print("尺寸:",f"{info['width']}x{info['height']}")print("HTML:",info["html"])
正式接入时,provider 返回的 HTML 一定要按业务白名单过滤。尤其是 iframe、script、style 相关内容,不能只因为来自 provider 就默认可信。
功能二:替换文本里的媒体链接
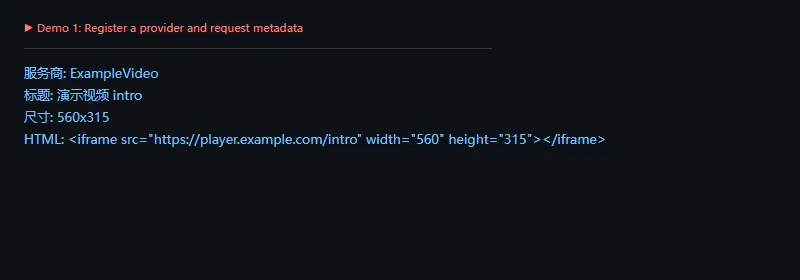
这段代码解决什么问题:用户输入通常是一整段文字,而不是单独一个 URL。parse_text 可以扫描文本,把已知 provider 的链接替换成嵌入 HTML。
frommicawberimportProvider,ProviderRegistryclassLocalVideoProvider(Provider):defrequest(self,url,**extra_params):slug=url.rstrip("/").split("/")[-1]return{"type":"rich","provider_name":"ExampleVideo","title":f"演示视频 {slug}","url":url,"html":f'<iframe src="https://player.example.com/{slug}"></iframe>',"width":560,"height":315,}providers=ProviderRegistry()providers.register(r"https://video\.example\.com/watch/.+",LocalVideoProvider("https://provider.example.com/oembed"))text="推荐内容:\nhttps://video.example.com/watch/intro"print(providers.parse_text(text))
这个模式适合评论、帖子、文章编辑器和内部知识库。我的建议是先抽取链接并做白名单判断,再决定是否替换,避免用户随便贴一个未知链接就触发外部请求。
环境与版本信息
- Demo 环境:Windows 11,Python 3.11
- 关键依赖版本:
beautifulsoup4 4.12.3、lxml 5.4.0 - 主要能力:provider 注册、oEmbed 请求、文本解析、HTML 解析、链接抽取
- GitHub 最近一次推送时间:
2026-03-10T11:59:12Z
高级功能
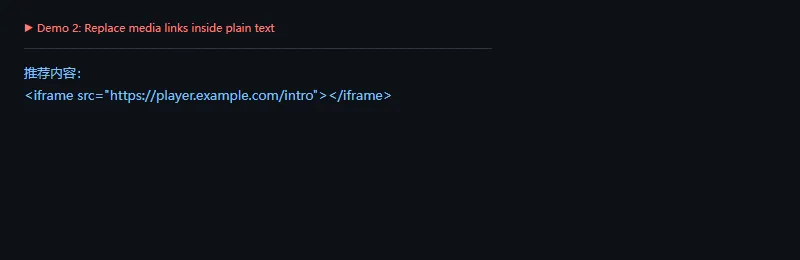
这段代码解决什么问题:有时不想立刻替换内容,而是先知道文本里有哪些链接、哪些能识别成富媒体。extract 可以把原始链接和成功解析的富媒体数据分开返回。
frommicawberimportProvider,ProviderRegistryclassLocalVideoProvider(Provider):defrequest(self,url,**extra_params):slug=url.rstrip("/").split("/")[-1]return{"provider_name":"ExampleVideo","title":f"演示视频 {slug}","url":url,"html":f'<iframe src="https://player.example.com/{slug}"></iframe>'}providers=ProviderRegistry()providers.register(r"https://video\.example\.com/watch/.+",LocalVideoProvider("https://provider.example.com/oembed"))links,rich=providers.extract("看看 https://video.example.com/watch/intro 和 https://example.com/plain")print("识别链接:",len(links))print("富媒体:",len(rich))forurl,datainrich.items():print(url)print(data["title"])
这一步适合做审核、预览和缓存预热。比如先列出页面里所有链接,再只对允许的域名执行 provider 请求,最后把结果写入缓存。
适用场景
- 你在做文章、评论、帖子或知识库,需要把媒体链接变成嵌入卡片
- 你希望按平台注册 provider,而不是到处写 if/else 判断链接
不适用场景
- 你只是抓网页正文,不需要处理 oEmbed 或富媒体卡片
- 你无法控制 HTML 安全过滤,不能安全展示第三方返回的嵌入内容
上线检查
- 给 provider 域名、URL 正则和最大请求超时设置白名单。
- 对返回 HTML 做安全过滤,避免未知 iframe、script 或恶意属性进入页面。
- 给 provider 结果加缓存,记录失败次数和最后成功时间,避免每次渲染都请求外部服务。
总结
micawber 是一个很灵巧的富媒体链接处理工具。它不是通用爬虫,也不是 Markdown 转换器,而是专注把 URL 识别、元数据请求和嵌入替换串起来。做内容平台时,这种小而专的能力很有用。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
