写在前面的话
我也是拼了。一位公司同事看我朋友圈说,你搞这个头条运营啊,收益还不错,我现在开公司,想运营点东西,咱们可以见面聊聊,看看能不能搞一下。于是,昨天,我就去他住的地方找他,他在房山住,我来回倒车,把自己整懵之前,终于找到了他。他说,想吃什么。我说,什么都行,咱们主要聊聊天。于是我们去吃了羊蝎子,我平常是不喝酒的,抽烟比较厉害。但为了把这个事能顺利推进,我也是拼了,喝了五瓶啤酒,同事也不差事,陪了五瓶,我上了四次厕所,他去了两次。我们回忆了几年前在一起工作的美好时光,聊了下该怎么给我当团长拉人,最后就是各种胡乱说话,答非所问,因为我俩都有点多了,一直到晚上11:45,我才求饶式往回走。我要付钱,同事付了。总体还好吧,回来的路上,我有种为了销售业绩大量陪酒的感觉,发展发展看吧,也许有好结果,加油!
[236+100]-------->底部有张生活照片 (头条号运营:大家想全托管上号的联系我哦,每天让你得个早餐钱,wx: qhz198607)
(头条号运营:大家想全托管上号的联系我哦,每天让你得个早餐钱,wx: qhz198607)
【关键词】python、ragflow、专家诊断、es慢
一、web端专家诊断(三级)
描述:web端专家诊断,搜索数据库时比较慢,现在龙哥优化了搜索语句,秒回,按照这个搜索语句,拼接下程序中的语句。
开工:
第一步:打断点(四级)
20250401周二时间段:21:17-22:00
写个专家诊断的接口,直接测试比较方便。写测试用例如下:
@manager.route('/expert_diagnosis', methods=['POST'])
@validate_request("question")
def expert_diagnosis():
"""
这个接口主要测试专家诊断的速度
"""
req = request.json
log.info(f"req: {req}")
question = req.get("question", '')
if not question:
return get_data_error_result(message="question is not found!")
conversation_id = req.get("conversation_id", '')
if not conversation_id:
return get_data_error_result(message="conversation_id is not found!")
e, conv = ConversationService.get_by_id(conversation_id)
# log.info(f"e:{e} conv: {conv}")
if not e:
return get_data_error_result(message="Conversation not found!")
message = [{"role": "user", "content": question}]
messages = conv.message + message
e, dia = DialogService.get_by_id(conv.dialog_id)
if not e:
return get_data_error_result(message="Dialog not found!")
return expert_diagnosis_request(conversation_id,dia,messages,question)注:接下来,写个测试用例,运行一下,看看效果。发现es还是慢,先搞一会es测试。
第二步:es查询测试(四级)
20250401周二时间段:21:17-22:00
看测试例子,如下:
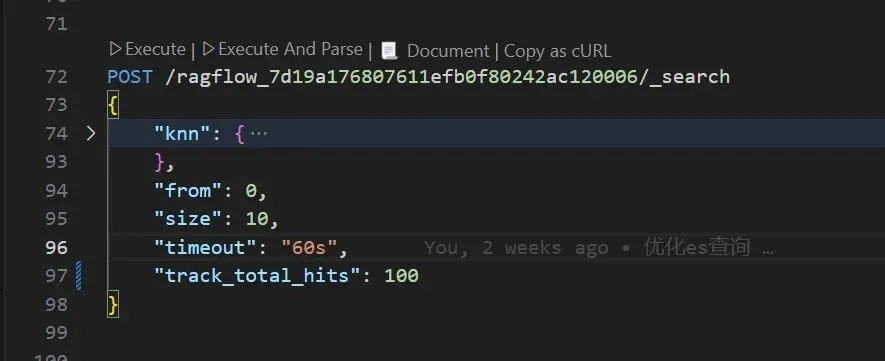
图6a-1
注:在测试服上的测试结果如下:
图6a-2
注:现在是0.5s,看下配置日志。没找到慢的日志。接下来,按deepseek排查一波。
第三步:deepseek排查(四级)
a. 硬件资源不足(五级)
20250401周二时间段:21:17-22:00
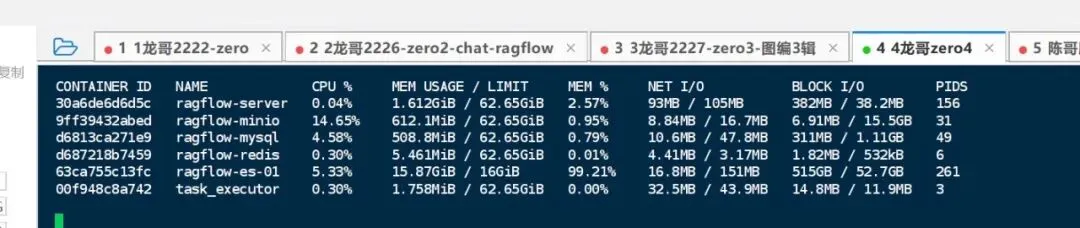
注:内存使用情况如下:
图6a-3
注:这个内存分配太少了,优化一下,重启zero4.
现在查询报错:
// all shards failed [ { "type": "null_pointer_exception", "reason": "Cannot invoke \"java.lang.Integer.intValue()\" because \"parent\" is null" }, { "type": "index_out_of_bounds_exception", "reason": "Index: 15, Size: 11" } ]b.报错处理(五级)
20250402周三时间段:10:03-10:30
这个先不管。接下来,继续搞配置。
c. 验证索引状态(五级)
20250402周三时间段:11:58-12:00
20250402周三时间段:15:20-16:00
确认索引是否正常打开且分片已分配:
# 查看索引状态
curl -XGET "http://localhost:9200/_cat/indices?v"
# 检查分片分配情况
curl -XGET "http://localhost:9200/_cat/shards?h=index,shard,prirep,state,node&v"
如果索引状态为 close,需先打开索引:
curl -XPOST "http://localhost:9200/<index_name>/_open"
如果分片处于 UNASSIGNED 状态,尝试手动分配:
curl -XPOST "http://localhost:9200/_cluster/reroute?retry_failed"
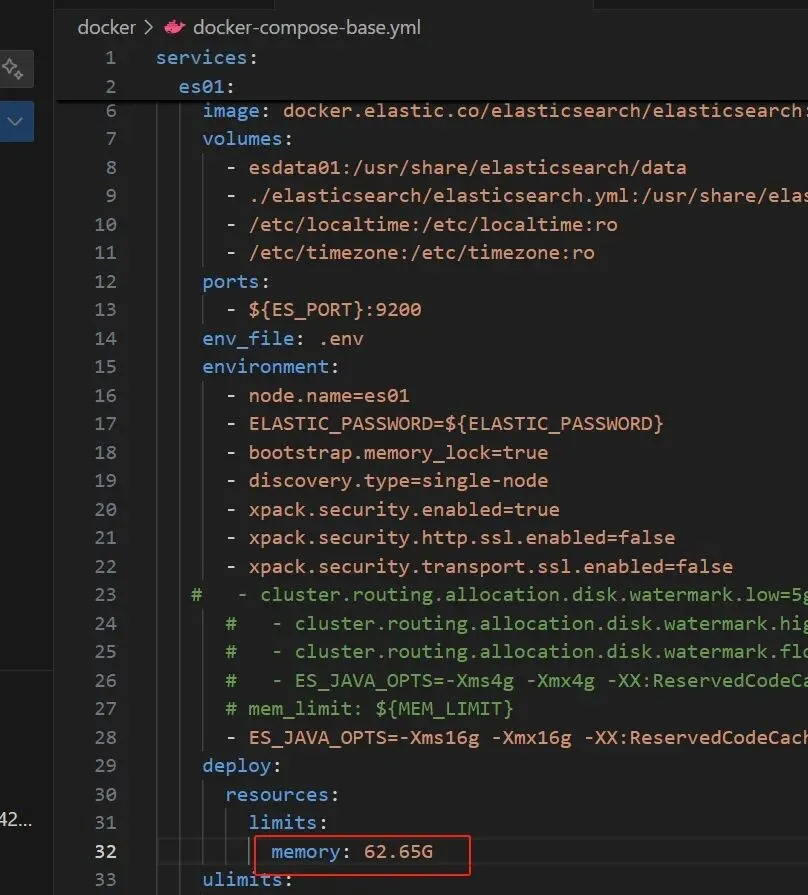
注:修改了es的配置,把内存变大了,修改如下:
图6a-4
注:重启一下服务器,如下:
图6a-5
注:接下来,先写测试用用例,es的优化是个长期的过程,不能一直盯着。
二、专家诊断测试用例(三级)
描述:写个专家诊断测试用例,方便进行测试es速度慢的问题。
开工:
第一步:写测试用例(四级)
20250402周三时间段:09:56-10:00
20250402周三时间段:16:50-17:00
写测试用例如下:
def test_expert_diagnosis(client):
log.info("test_expert_diagnosis")
'''
测试专家诊断--主要为了测试es的速度
'''
json_data = {
"conversation_id": 'fff19f22fc0111efa7f900e003c42347',
"question": '我家狗拉肚子'
}
url = f"/v1/conversation/expert_diagnosis"
resp = client.post(
url,
json=json_data,
headers={
"Content-type": "application/json",
"Authorization": "Bearer ragflow-UxOGYzZjUwYjMwOTExZWZiODc0MDI0Mm"
}
)
if not 200 <= resp.status_code < 300:
raise Exception(f"GET {url} status_code {resp.status_code}.")
# received_data = []
for chunk in resp.iter_encoded():
answer = chunk.decode('utf-8').strip()
log.info(f"\n\n answer: {answer} \n\n")
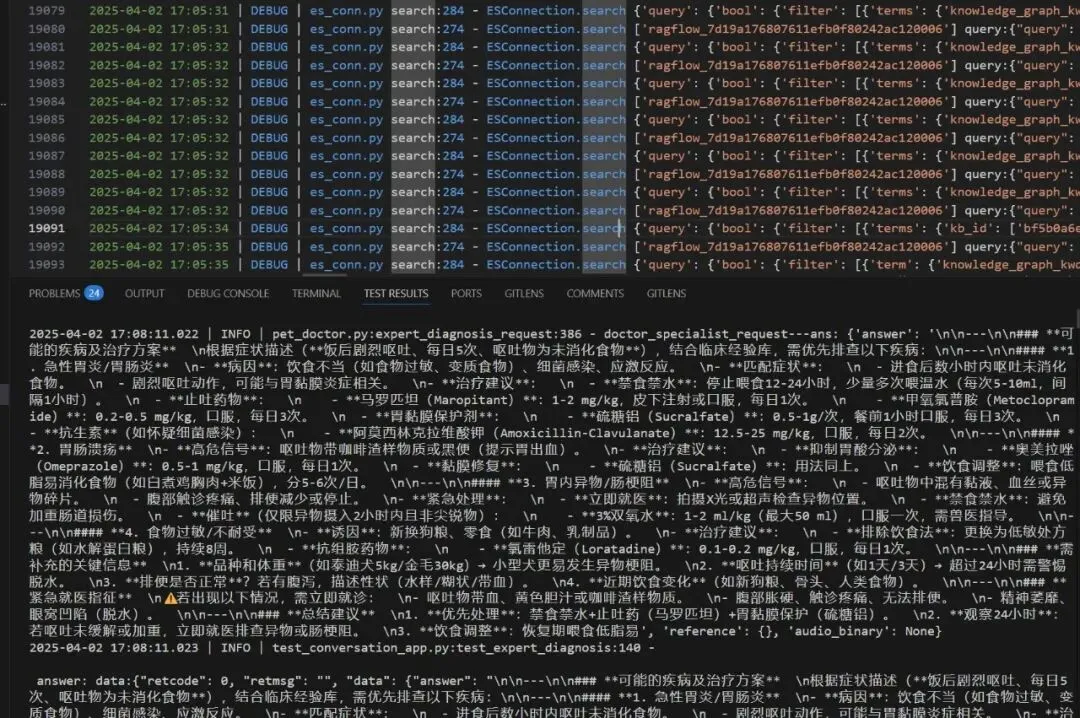
注:测一下,看看效果。主要是找到es查询语句,进行修改。
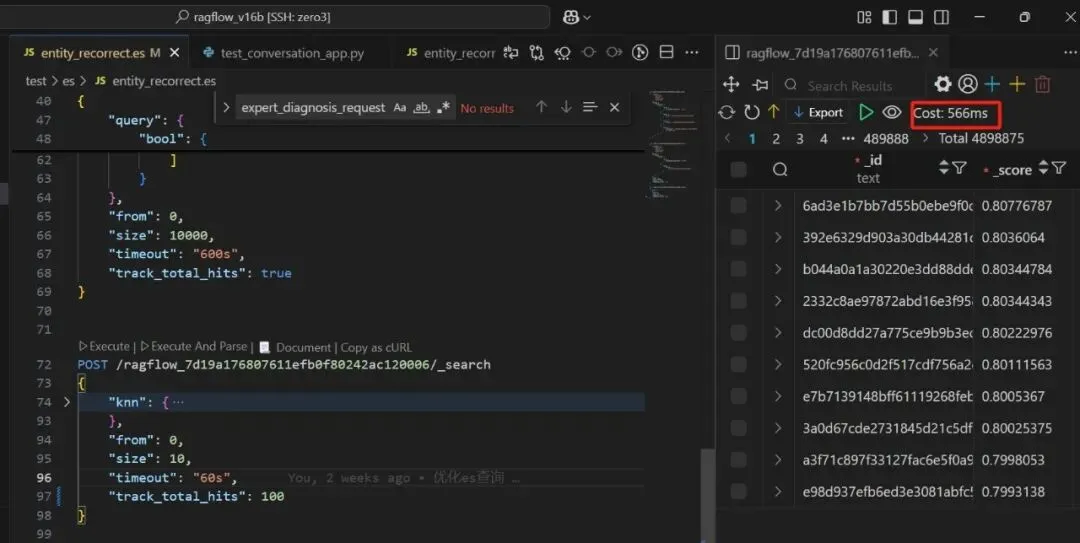
看了下,效果如下:
图6a-6
注:这个数据是能出来的,只是总时间耗时太长,可能是龙哥那边在修改数据。而下面这个不到10秒就出来,如下:
图6a-7
注:按这个把查询语句改一下。
第二步:改es搜索语句(四级)
20250402周三时间段:17:15-18:00
当前慢的查询语句,先看下es的信息,如下:
{
"name": "es01",
"cluster_name": "docker-cluster",
"cluster_uuid": "A41kmvFWR5mwzRs3J8zJbg",
"version": {
"number": "8.11.3",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "64cf052f3b56b1fd4449f5454cb88aca7e739d9a",
"build_date": "2023-12-08T11:33:53.634979452Z",
"build_snapshot": false,
"lucene_version": "9.8.0",
"minimum_wire_compatibility_version": "7.17.0",
"minimum_index_compatibility_version": "7.0.0"
},
"tagline": "You Know, for Search"
}接着,看下当下索引,如下:
{
"version": 283,
"mapping_version": 8,
"settings_version": 8,
"aliases_version": 1,
"routing_num_shards": 1024,
"state": "open",
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"refresh_interval": "1000ms",
"number_of_shards": "2",
"provided_name": "ragflow_7d19a176807611efb0f80242ac120006",
"similarity": {
"scripted_sim": {
"type": "scripted",
"script": {
"source": "double idf = Math.log(1+(field.docCount-term.docFreq+0.5)/(term.docFreq + 0.5))/Math.log(1+((field.docCount-0.5)/1.5)); return query.boost * idf * Math.min(doc.freq, 1);"
}
}
},
"max_result_window": "200000",
"creation_date": "1727843529722",
"number_of_replicas": "0",
"uuid": "-SS6hhitR-uBu04QevyV1Q",
"version": {
"created": "8500003"
}
}
},
"mappings": {
"_doc": {
"dynamic_templates": [{
"int": {
"mapping": {
"store": "true",
"type": "integer"
},
"match": "*_int"
}
},
{
"ulong": {
"mapping": {
"store": "true",
"type": "unsigned_long"
},
"match": "*_ulong"
}
},
{
"long": {
"mapping": {
"store": "true",
"type": "long"
},
"match": "*_long"
}
},
{
"short": {
"mapping": {
"store": "true",
"type": "short"
},
"match": "*_short"
}
},
{
"numeric": {
"mapping": {
"store": true,
"type": "float"
},
"match": "*_flt"
}
},
{
"tks": {
"mapping": {
"analyzer": "whitespace",
"similarity": "scripted_sim",
"store": true,
"type": "text"
},
"match": "*_tks"
}
},
{
"ltks": {
"mapping": {
"analyzer": "whitespace",
"store": true,
"type": "text"
},
"match": "*_ltks"
}
},
{
"kwd": {
"match_pattern": "regex",
"mapping": {
"similarity": "boolean",
"store": true,
"type": "keyword"
},
"match": "^(.*_(kwd|id|ids|uid|uids)|uid)$"
}
},
{
"dt": {
"match_pattern": "regex",
"mapping": {
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||yyyy-MM-dd_HH:mm:ss",
"store": true,
"type": "date"
},
"match": "^.*(_dt|_time|_at)$"
}
},
{
"nested": {
"mapping": {
"type": "nested"
},
"match": "*_nst"
}
},
{
"object": {
"mapping": {
"dynamic": "true",
"type": "object"
},
"match": "*_obj"
}
},
{
"string": {
"mapping": {
"index": "false",
"store": true,
"type": "text"
},
"match": "*_with_weight"
}
},
{
"string": {
"mapping": {
"type": "rank_feature"
},
"match": "*_fea"
}
},
{
"dense_vector": {
"mapping": {
"dims": 512,
"similarity": "cosine",
"index": true,
"type": "dense_vector"
},
"match": "*_512_vec"
}
},
{
"dense_vector": {
"mapping": {
"dims": 768,
"similarity": "cosine",
"index": true,
"type": "dense_vector"
},
"match": "*_768_vec"
}
},
{
"dense_vector": {
"mapping": {
"dims": 1024,
"similarity": "cosine",
"index": true,
"type": "dense_vector"
},
"match": "*_1024_vec"
}
},
{
"dense_vector": {
"mapping": {
"dims": 1536,
"similarity": "cosine",
"index": true,
"type": "dense_vector"
},
"match": "*_1536_vec"
}
},
{
"binary": {
"mapping": {
"type": "binary"
},
"match": "*_bin"
}
}
],
"date_detection": true,
"properties": {
"weight_int": {
"store": true,
"type": "integer"
},
"content_with_weight": {
"index": false,
"store": true,
"type": "text"
},
"create_timestamp_flt": {
"store": true,
"type": "float"
},
"img_id": {
"similarity": "boolean",
"store": true,
"type": "keyword"
},
"title_tks": {
"analyzer": "whitespace",
"similarity": "scripted_sim",
"store": true,
"type": "text"
},
"weight_flt": {
"store": true,
"type": "float"
},
"available_int": {
"store": true,
"type": "integer"
},
"important_kwd": {
"similarity": "boolean",
"store": true,
"type": "keyword"
},
"kb_id": {
"similarity": "boolean",
"store": true,
"type": "keyword"
},
"rank_int": {
"store": true,
"type": "integer"
},
"position_int": {
"store": true,
"type": "integer"
},
"top_int": {
"store": true,
"type": "integer"
},
"lat_lon": {
"store": true,
"type": "geo_point"
},
"title_sm_tks": {
"analyzer": "whitespace",
"similarity": "scripted_sim",
"store": true,
"type": "text"
},
"q_4096_vec": {
"dims": 4096,
"similarity": "cosine",
"index": true,
"type": "dense_vector"
},
"create_time": {
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||yyyy-MM-dd_HH:mm:ss",
"store": true,
"type": "date"
},
"knowledge_graph_kwd": {
"similarity": "boolean",
"store": true,
"type": "keyword"
},
"content_ltks": {
"analyzer": "whitespace",
"store": true,
"type": "text"
},
"content_sm_ltks": {
"analyzer": "whitespace",
"store": true,
"type": "text"
},
"authors_sm_tks": {
"analyzer": "whitespace",
"similarity": "scripted_sim",
"store": true,
"type": "text"
},
"doc_id": {
"similarity": "boolean",
"store": true,
"type": "keyword"
},
"q_1024_vec": {
"dims": 1024,
"similarity": "cosine",
"index": true,
"type": "dense_vector"
},
"authors_tks": {
"analyzer": "whitespace",
"similarity": "scripted_sim",
"store": true,
"type": "text"
},
"docnm_kwd": {
"similarity": "boolean",
"store": true,
"type": "keyword"
},
"page_num_int": {
"store": true,
"type": "integer"
},
"name_kwd": {
"similarity": "boolean",
"store": true,
"type": "keyword"
},
"entities_kwd": {
"similarity": "boolean",
"store": true,
"type": "keyword"
}
}
}
},
"aliases": [],
"primary_terms": {
"0": 220,
"1": 219
},
"in_sync_allocations": {
"0": [
"Zk8zfkveTvi9V5Sg9oR-2A"
],
"1": [
"rrv6c9oVT9WBW2sjQ8uBcQ"
]
},
"rollover_info": {},
"system": false,
"timestamp_range": {
"unknown": true
}
}注:这个可以和查询出的做下对比。
三、头条号战果汇报
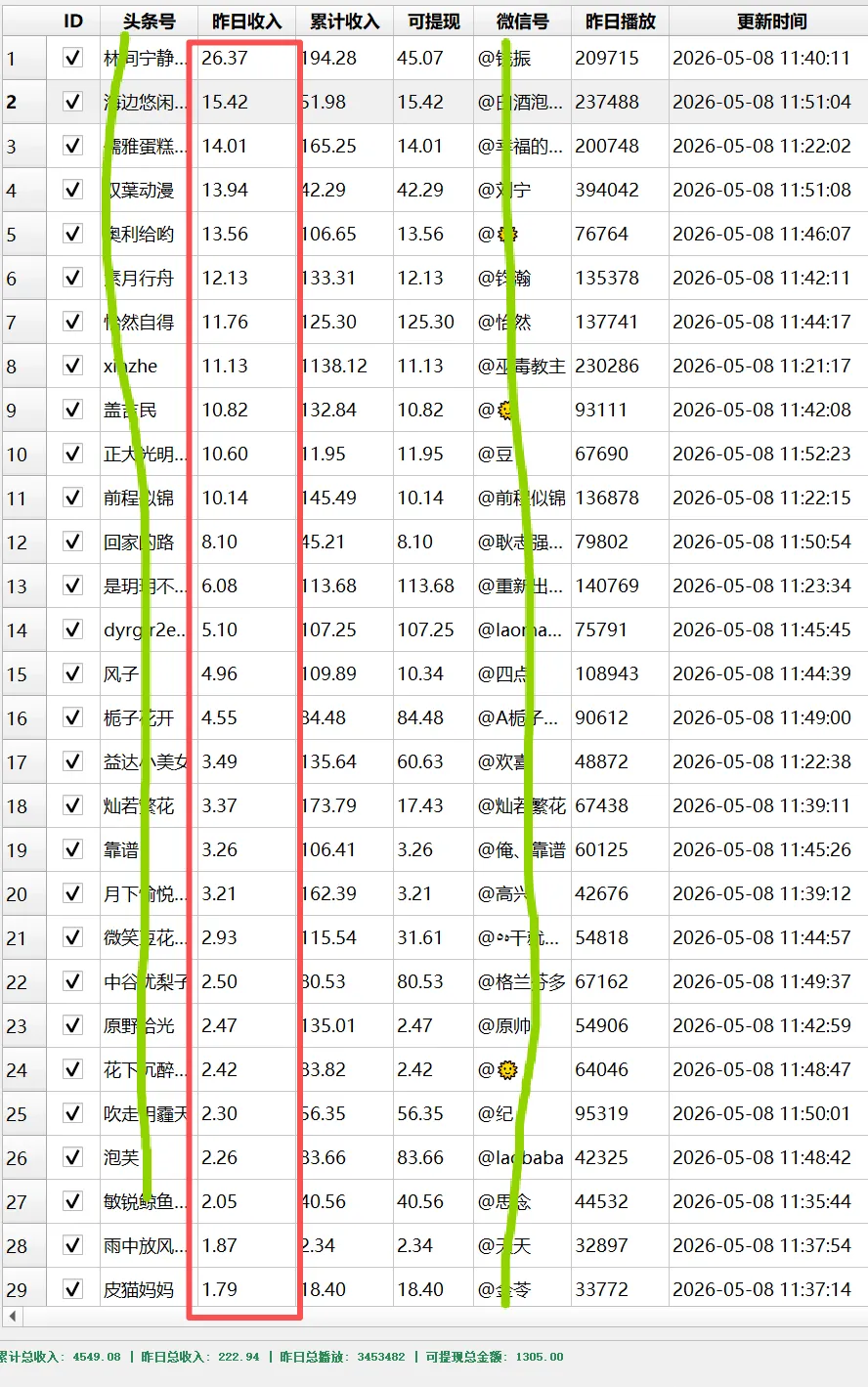
昨日总播放:345.7万,总收入:222.94,累计收入:4549.08块,可提现:1305.14,软件截图如下:
图6c-1
注:想要全脱管运营头条号的联系我,你出账号,我来运营,收益五五分成,你当甩手掌柜,每天都能得几块零花钱,财富wx: 17701328814,也可以加群先了解一下。
图6c-2
四、生活照片
拍摄于2026年1月17日,20:31:02,带二宝在外面玩雪,当时二宝三岁三个月。昨天和同事吃饭,同事可能也没想着灌我酒,但我是带着目的去的,希望通过他的公司,能让我的挂号人数增多,所以,他说要喝酒,我就应承下来,可能无意识的觉得不能让同事不开心,最终导致这个事合作不下去。所以,两个人一旦有了利益关系,谈起话来就没那么轻松,没那么放肆,这也是正常的,我都四十了,总不能老活在自己的童话里,该正经的时候一定要正经起来,因为家里孩子还等吃喝,我不能那么的放飞自我。
图6c-1
《本文完》


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
