Linux top命令详解:从入门到精通,实时监控系统资源的核心工具
- 2026-06-24 10:07:54
本文约3000字,在Linux运维、开发调试中,实时监控系统资源(CPU、内存、进程)是必备技能,而top就是最常用、最核心的两款实时监控工具。top作为Linux系统自带的原生工具,轻量且功能强大,是排查系统卡顿、资源耗尽的“第一手工具”。
本文将详细解读top命令的完整用法、每一个参数的含义,结合实操场景讲解核心技巧,让我们一起彻底掌握这款工具,轻松应对系统资源监控、故障排查等场景。
我建了一个BSP学习交流群,想学BSP或者已经是BSP开发者可私信我,加入群,一起交流学习,共同进步。
关注公众号, 即可获得与Linux相关的电子书籍以及常用开发工具,文末有文档清单。
一 top核心作用与适用场景
top核心作用都是实时监控系统资源使用情况、查看进程运行状态:
它是Linux系统原生工具,无需额外安装,轻量无依赖,支持基础的资源监控和进程管理,适合所有Linux环境(包括最小化部署系统),是排查基础故障的“必备工具”,核心优势是“通用、轻量、无依赖”。
核心使用场景:系统卡顿排查、CPU/内存高占用定位、进程异常监控、资源瓶颈分析,是Linux运维、开发、测试人员日常工作中使用频率最高的命令之一。
二 top命令详解
top命令的核心特点是“实时动态刷新”,默认每3秒刷新一次,通过键盘交互可以调整刷新频率、排序方式、显示内容。
[1]. top基础用法top命令无需复杂配置,直接在终端输入命令即可启动,核心基础用法如下:
# 1. 启动默认top监控(每3秒刷新一次)top# 2. 自定义刷新频率(例如每5秒刷新一次,-d 后面跟秒数)top -d 5# 3. 显示指定数量的进程(例如只显示前10个进程,-n 后面跟进程数)top -n 10# 4. 监控指定用户的进程(例如监控root用户的进程,-u 后面跟用户名)top -u root# 5. 监控指定PID的进程(例如监控PID为1234的进程,-p 后面跟PID,多个PID用逗号分隔)top -p 1234,5678# 6. 以批处理模式运行(不进入交互界面,适合脚本调用,-b)top -b -n 5 # 非交互模式,输出5次后退出
关键说明:启动top后,按q键即可退出监控界面;默认显示的是所有进程,按不同交互键可调整显示内容和排序方式。
[2]. top输出参数详解
启动top后,界面分为两大区域:系统整体资源统计区(前5行)和进程详细信息区(第6行及以下),每一行、每一个参数都有明确含义,掌握这些参数,才能真正读懂系统状态。
【系统整体资源统计区】:
先看一个标准的top输出示例(CentOS 7环境),再逐行解析:
top - 17:05:30 up 2d 3h 10m, 2 users, load average: 0.35, 0.42, 0.38Tasks: 187 total, 1 running, 186 sleeping, 0 stopped, 0 zombie%Cpu(s): 2.3 us, 1.2 sy, 0.0 ni, 96.4 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 stMiB Mem : 15868.0 total, 8920.5 free, 3245.3 used, 3702.2 buff/cacheMiB Swap: 16384.0 total, 16384.0 free, 0.0 used. 11380.7 avail Mem
第1行:系统整体状态
top - 17:05:30 up 2d 3h 10m, 2 users, load average: 0.35, 0.42, 0.3817:05:30:当前系统的实时时间;
up 2d 3h 10m:系统已运行的时间(2天3小时10分钟),若系统重启过,会显示重启时间;
2 users:当前登录系统的用户数(不是用户账号数,是同时在线的会话数);
load average: 0.35, 0.42, 0.38:系统1分钟、5分钟、15分钟的平均负载,核心参数,重点解读:
平均负载表示“单位时间内等待CPU处理的进程数”,数值越低,系统越空闲;
参考标准:若系统是N核CPU,平均负载长期超过N(如4核CPU超过4),说明系统负载过高,CPU处理不过来;
异常判断:1分钟负载远高于15分钟负载,说明系统最近出现短期高负载;反之,说明系统高负载持续了一段时间。
第2行:进程整体统计(Tasks)
Tasks: 187 total, 1 running, 186 sleeping, 0 stopped, 0 zombie187 total:系统当前运行的总进程数(包括所有状态的进程);
1 running:正在运行(占用CPU)的进程数(正常情况下,这个数值不会超过CPU核心数);
186 sleeping:处于休眠状态的进程数(大部分进程都是休眠状态,等待事件触发,如等待用户输入、网络请求);
0 stopped:被停止的进程数(通常是通过kill -STOP命令暂停的进程);
0 zombie:僵尸进程数(核心重点),僵尸进程是“进程已终止,但父进程未回收其资源”的进程,僵尸进程数非0需重点关注,长期存在会占用系统资源,甚至导致系统卡顿,需手动清理。
第3行:CPU资源统计(%Cpu(s))
%Cpu(s): 2.3 us, 1.2 sy, 0.0 ni, 96.4 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st这一行是CPU监控的核心,所有参数的总和为100%,每一项代表CPU的不同占用场景,重点解读每一个参数:
us(user):用户态CPU占用率(2.3%),指应用程序(如nginx、mysql、java)占用的CPU资源,us过高(如超过80%),说明应用程序消耗过多CPU,需定位具体进程;
sy(system):内核态CPU占用率(1.2%),指Linux内核(如进程调度、内存管理、IO操作)占用的CPU资源,sy过高(如超过30%),说明内核操作频繁,可能是IO瓶颈、驱动问题;
ni(nice):调整过优先级的用户态进程CPU占用率(0.0%),nice值用于调整进程优先级(范围-20~19,值越小优先级越高),若有进程调整过nice值,会在这里显示占用率;
id(idle):空闲CPU占用率(96.4%),指CPU处于空闲状态的比例,id越低,CPU越繁忙,id接近0时,系统CPU已耗尽;
wa(iowait):IO等待CPU占用率(0.0%),指CPU等待磁盘、网络IO完成的时间比例,wa过高(如超过10%),说明系统存在IO瓶颈(如磁盘读写缓慢、网络卡顿),CPU一直在等待IO操作完成;
hi(hardware irq):硬件中断CPU占用率(0.0%),指硬件设备(如网卡、键盘、磁盘)触发的中断占用的CPU资源,hi过高可能是硬件故障;
si(software irq):软件中断CPU占用率(0.1%),指系统软件触发的中断(如网络协议栈、定时器)占用的CPU资源,si过高可能是软件配置问题;
st(steal):被虚拟化“偷走”的CPU占用率(0.0%),仅虚拟机场景有效,指宿主机分配给其他虚拟机的CPU资源,st过高说明虚拟机可用CPU资源不足。
补充:按1键可以切换“CPU整体统计”和“单个CPU核心统计”,多核CPU场景下,可查看每个核心的占用情况,定位“单核瓶颈”。
第4-5行:内存与交换分区(Mem/Swap)
MiB Mem : 15868.0 total, 8920.5 free, 3245.3 used, 3702.2 buff/cacheMiB Swap: 16384.0 total, 16384.0 free, 0.0 used. 11380.7 avail Mem
这两行是内存监控的核心,区分“物理内存(Mem)”和“交换分区(Swap)”,
重点解读:
Mem(物理内存):
total:物理内存总容量(15868.0 MiB,约16GB);
free:完全空闲的物理内存(8920.5 MiB);
used:已使用的物理内存(3245.3 MiB);
buff/cache:缓冲区(buff)和缓存(cache)占用的内存(3702.2 MiB),核心重点:buff/cache是“可释放的内存”,当应用程序需要内存时,系统会自动释放这部分内存,所以不能仅凭“used过高”判断内存不足,需看“avail Mem”。
Swap(交换分区):
total:交换分区总容量(16384.0 MiB,约16GB);
free:空闲的交换分区(16384.0 MiB);
used:已使用的交换分区(0.0 MiB),
重点:Swap是“物理内存不足时,用磁盘模拟的内存”,速度远慢于物理内存,Swap used非0,说明物理内存不足,系统开始使用磁盘,会导致系统卡顿,需及时排查内存泄漏或扩容。
avail Mem:可用物理内存(11380.7 MiB),核心参考指标,代表“系统可分配给应用程序的内存”,包括free内存和可释放的buff/cache内存,avail Mem过低(如低于总内存的10%),说明系统内存紧张。
【进程详细信息区】(第6行及以下):
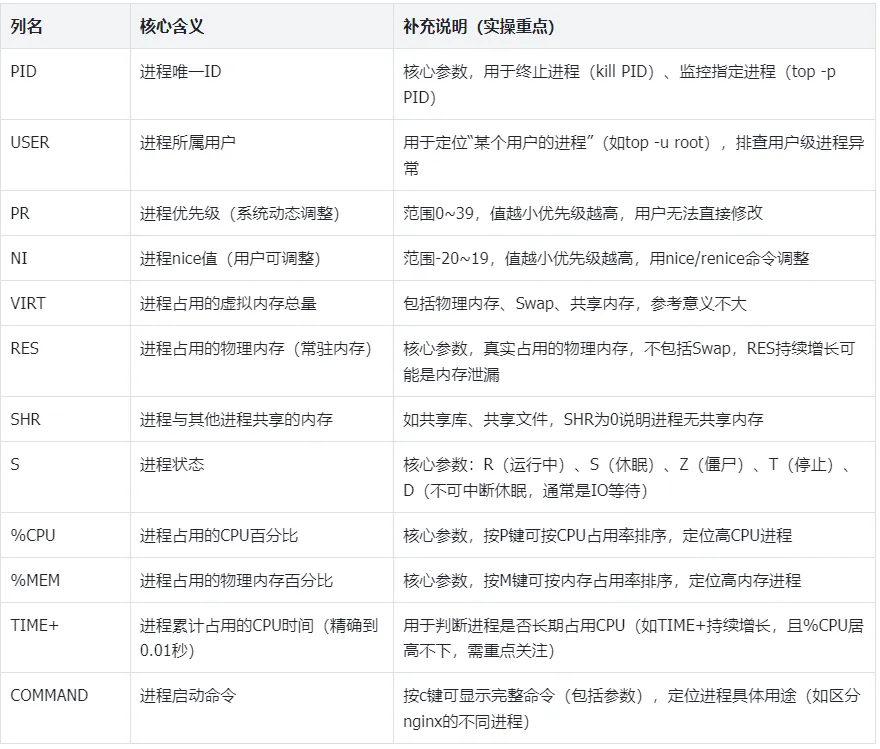
进程区显示每个进程的详细资源占用情况,默认按CPU占用率降序排列,每一列对应一个参数,核心列详解(常用列重点标注):
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND1234 root 20 0 123456 45678 12345 R 5.2 0.3 0:45.32 nginx5678 mysql 20 0 234567 89012 34567 S 2.1 0.5 2:30.15 mysqld
[3]. top交互命令
启动top后,通过键盘按键可实时调整监控界面,无需重新输入命令,常用交互命令如下:
排序相关:
P:按CPU占用率降序排序(默认排序方式);
M:按内存占用率(%MEM)降序排序;
T:按进程累计CPU时间(TIME+)降序排序;
N:按PID升序排序。
显示相关:
1:切换CPU整体统计/单个核心统计;
c:切换“进程命令缩写/完整命令”(如nginx→/usr/sbin/nginx -c /etc/nginx/nginx.conf);
i:隐藏休眠进程,只显示正在运行(R)的进程;
f:自定义显示的进程列(可添加/删除列,如添加PPID、USER等);
o:调整进程列的显示顺序;
l:隐藏/显示第1行(系统整体状态);
m:隐藏/显示内存统计行(第4-5行);
t:隐藏/显示CPU统计行(第3行)和进程状态统计行(第2行)。
进程管理相关:
k:终止指定进程(按k后,输入PID,按回车,再输入信号量,默认15(正常终止),9(强制终止));
r:调整进程的nice值(按r后,输入PID,按回车,输入新的nice值,范围-20~19);
z:将进程按颜色区分(不同状态的进程显示不同颜色,更直观)。
其他操作:
s:调整刷新频率(按s后,输入秒数,默认3秒);
q:退出top监控界面;
W:保存当前top配置(如排序方式、显示列),下次启动top自动生效。
[4]. top高级用法
结合实际运维场景,top的高级用法主要用于“精准监控、脚本调用、故障排查”,常用高级命令如下:
# 1. 监控指定进程的实时状态(每隔2秒刷新,持续监控)top -d 2 -p 1234 # 监控PID为1234的进程,每2秒刷新一次# 2. 只显示活跃进程(排除休眠、僵尸进程)top -i# 3. 按CPU使用率排序,显示前5个进程(非交互模式,适合脚本)top -b -n 1 -o %CPU | head -n 10 # -n 1表示只输出1次,head -n 10过滤前10行(包含统计区)# 4. 监控多个用户的进程(如root和nginx用户)top -u root -u nginx # 注意:-u参数可重复使用# 5. 查看进程的线程信息(按H键,或启动时加-H)top -H -p 1234 # 查看PID为1234的进程的所有线程,定位线程级CPU占用# 6. 输出进程的完整命令(启动时加-c)top -c # 无需交互,直接显示完整命令
实操场景:当系统CPU占用过高时,用“top -o %CPU”快速定位高CPU进程,用“top -H -p PID”查看该进程的线程,定位具体哪个线程占用CPU,再结合其他工具(如strace、gdb)排查问题。
以上为全文内容。
这里是女程序员的笔记本
15年+嵌入式软件工程师兼二胎宝妈
分享读书心得、工作经验,自我成长和生活方式。
希望我的文字能对你有所帮助
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Linux 最新资讯 20260510——Debian Release Team: Debian必须提供Reproducible Packages
- ARM Linux Core Dump高阶调试:gdb分析内存映射与异常访问
- Ruff:打造无错误、高可维护性Python代码的现代化代码检查工具
- Quasar Linux RAT(QLNX):一种用于隐蔽和持久化的无文件 Linux 植入工具
- Python10个高频脚本:上班摸鱼,效率直接拉满!
- 程序员必备!Python 常用库完整大盘点
- 针对Linux的隐形杀手:QLNX无文件化RAT,七种持久化机制直击企业服务器
- Linux超高危漏洞!网络安全一周新闻速看(20260510期)
- 手把手教你学Linux内存管理
- uv:让 Python 包管理快 100 倍的下一代神器
