Linux 的压缩文件为什么都是以 tar.gz 的形式出现,而不是 .tar 或 .gz?
- 2026-06-30 02:54:27
大家好,我是Q。
你每天都在用 tar -xzf,但你知道为什么吗?
一个你从未想过的问题
$ ls ~/Downloads/cmake-3.28.1.tar.gzredis-7.2.3.tar.gznginx-1.25.3.tar.gzlinux-6.6.tar.gz...有没有发现一个规律?Linux 世界里几乎所有压缩包都叫 .tar.gz,而不是 .tar,也不是 .gz。
这很奇怪。Windows 上 .zip 一统天下,一个后缀搞定一切。为什么 Linux 非要搞出这种"两段式"后缀?.tar 和 .gz 中间那个点,到底是什么意思?
更奇怪的是——如果你试过只用 .gz,你会发现目录结构没了、文件权限丢了、一百个文件变成一百个 .gz;如果你试过只用 .tar,你会发现文件压根没变小。单独用哪个都不行,必须两个一起才行。
这背后藏着 Unix 世界最核心的设计哲学:每个工具只做一件事,做到极致,然后通过管道组合出无穷可能。
听起来很抽象?
别急。今天我们就从一行 tar -czf 出发,揭开这段横跨 50 年的技术故事——从 1970 年代的磁带机,到专利战争,到压缩算法的底层原理,再到今天的 zstd 革命。
看完这篇文章,你对 Linux 的理解会深一个层次。
一、先回答最核心的问题:tar 和 gzip 各自干了什么?
1.1 tar:只归档,不压缩
tar 这个名字来自 Tape ARchiver——磁带归档器。它最初的设计目标非常明确:把一堆文件和目录打包成一个单一的流,方便写入磁带。
注意,tar 的核心能力是归档(archiving),不是压缩。
归档是什么意思?就是把多个文件按照一定的格式串联在一起,形成一个连续的字节流。在这个过程中,每个文件的元数据——文件名、权限(mode)、所有者(uid/gid)、时间戳(mtime)、文件大小——都被保存在对应的头部(header)中,紧接着是该文件的实际内容。
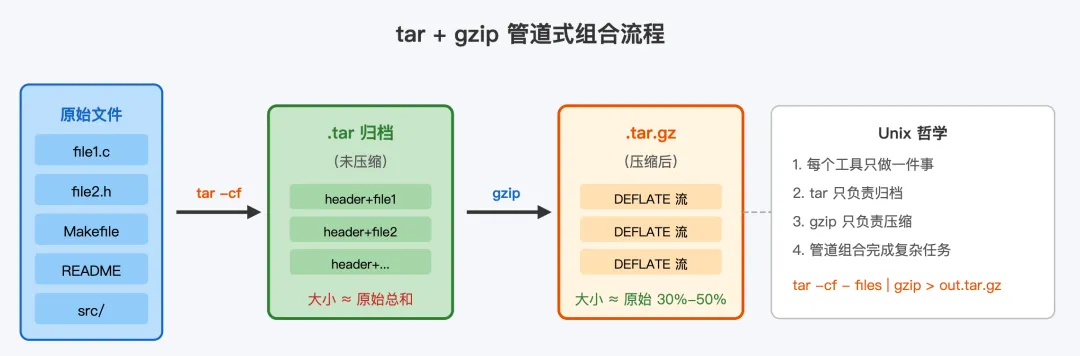
关键点来了:tar 在归档过程中,不对文件内容做任何压缩处理。原始数据有多大,归档后的 .tar 文件就有多大,甚至因为增加了头部信息和对齐填充,还会稍微大一点。所以你如果只执行 tar -cf archive.tar src/,得到的 .tar 文件和原始目录的大小几乎一样。
1.2 gzip:只压缩,不归档
gzip 是 GNU zip 的缩写,由 Jean-loup Gailly 和 Mark Adler 于 1992 年开发,用来替代当时受专利限制的 Unix compress 程序。gzip 的核心能力是压缩(compression),不是归档。
gzip 的设计有一个根本性的限制:它只能压缩单个文件。当你执行 gzip file1.c 时,gzip 读取 file1.c 的内容,对其进行压缩,输出 file1.c.gz。原始文件被替换为压缩后的文件(除非你加 -k 保留)。gzip 不会记住这个文件叫什么名字,不会保留目录结构,不会保存文件权限。它只是忠实地把输入的字节流变成更短的输出字节流。
1.3 二者结合:tar.gz 的诞生
既然 tar 只归档不压缩,gzip 只压缩不归档,那把它们串起来就完美了:
1. 先用 tar 把多个文件归档成一个 .tar文件2. 再用 gzip 把这个 .tar文件压缩成.tar.gz文件
这就是经典的管道操作:
tar -cf - src/ | gzip > backup.tar.gz解压时反过来:
gunzip -c backup.tar.gz | tar -xf -或者更简洁地,现代版本的 tar 已经内置了压缩支持:
tar -czf backup.tar.gz src/ # 压缩tar -xzf backup.tar.gz # 解压二、为什么不能只用 gzip?
2.1 gzip 只能压缩单个文件
这是最根本的原因。gzip 的文件格式(RFC 1952)在设计上就是面向单文件流的。一个 gzip 文件的结构非常简单:头部(10 字节固定 + 可选字段)+ DEFLATE 压缩数据 + 尾部(CRC32 + 原始大小)。它没有"文件列表"的概念,没有"目录树"的概念。
如果你有一个包含 100 个文件的项目目录,用 gzip 去压缩,你只能这样做:
gzip file1.c → file1.c.gzgzip file2.h → file2.h.gzgzip Makefile → Makefile.gz...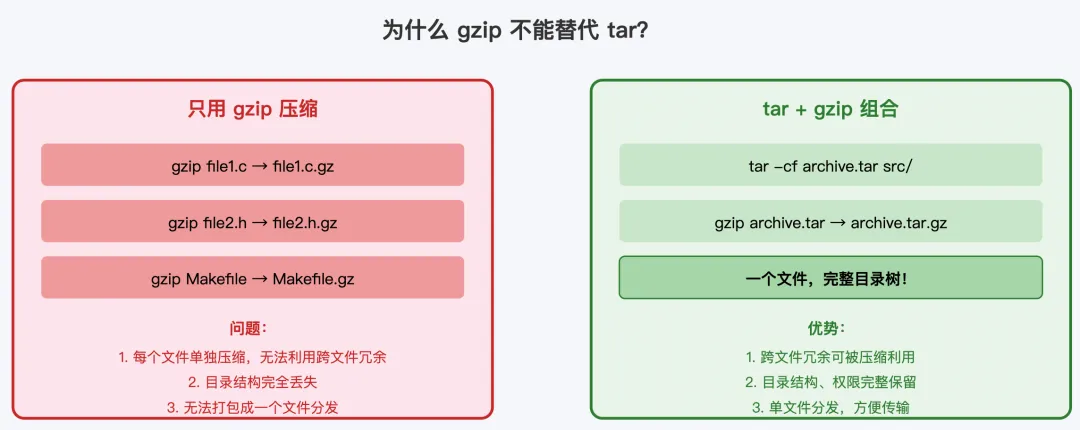
这样做的后果是灾难性的:
• 目录结构完全丢失:原始的 src/main.c和include/utils.h的层级关系没了,解压后所有文件都变成平铺的• 文件权限丢失:可执行文件的 x权限没了,配置文件的属主信息没了• 无法合并为一个文件:100 个文件变成 100 个 .gz文件,分发时需要再打包一次,陷入循环• 压缩效率低下:每个文件独立压缩,gzip 无法利用不同文件之间的冗余。例如,多个 C 源文件中重复的 #include指令、相同的函数声明,这些跨文件的重复模式在独立压缩时无法被消除
2.2 gzip 没有归档语义
更深层的问题是,gzip 的设计哲学是流处理器——它处理的是字节流,不是文件系统。它不关心输入来自文件还是管道,不关心输出到哪里。这种设计保证了极大的灵活性(任何程序的输出都可以通过管道交给 gzip 压缩),但也意味着它完全没有"文件集合"的概念。
gzip 确实在头部中有一个可选的 FNAME 字段,可以记录原始文件名,但这只是个"备忘录",不是归档结构。它不能记录目录层级、符号链接、设备文件等信息。
三、为什么不能只用 tar?
3.1 tar 不压缩,文件太大
如果你只做归档不做压缩,那就是 .tar 文件。tar 文件的大小约等于所有原始文件大小之和,再加上头部和对齐填充的开销。
对于典型的源代码项目,未压缩的 tar 归档可能有 100MB,而经过 gzip 压缩后可能只有 30MB。在网络传输或磁盘存储场景下,3 倍的大小差异是非常显著的。
3.2 磁带时代的遗留:压缩不是 tar 的职责
回到 tar 的诞生年代——1970 年代末,Ken Thompson 和 Dennis Ritchie 在贝尔实验室开发 Unix。那时候的存储介质是磁带(magnetic tape),容量极其有限,但磁带驱动器本身就有硬件压缩功能。
更重要的是,tar 不做压缩是刻意的——压缩算法在不断演进,从早期的 LZW,到 DEFLATE(gzip),到 BWT(bzip2),到 LZMA(xz),再到 Zstandard(zstd)。如果压缩逻辑耦合在 tar 里,每次算法升级都要改 tar;而通过管道组合,你只需要换一个压缩工具就行。这正是我们在开头提到的 Unix 哲学的体现。
3.3 .tar 文件的实际用途
虽然 .tar 不如 .tar.gz 常见,但它确实有适用场景:
• Docker 镜像层:Docker 的镜像层实际上就是 tar 归档(不压缩),因为 Docker 需要快速随机访问层内的文件 • 本地备份:在高速磁盘间传输时,压缩和解压的 CPU 开销可能比节省的 I/O 时间更多 • 中间产物:当你需要先归档再交给其他压缩工具(bzip2、xz、zstd)时, .tar是中间步骤
说完了"为什么不单独用",你可能还想问:tar 和 gzip 到底是怎么被设计出来的?要真正理解它们的格式设计,我们得先回到它们的诞生年代。
四、tar 的历史——从磁带到现代
4.1 磁带时代的产物
tar 的历史可以追溯到 1970 年代末的 Version 7 Unix。在那个年代,数据备份的主要介质是磁带(magnetic tape)。磁带是顺序访问介质——你只能从头到尾依次读取,不能随机跳转。这与硬盘的随机访问特性截然不同。
tar 的设计完美匹配了磁带的特性:
• 顺序写入:Header + Data + Header + Data + End Marker,与磁带的物理特性完全吻合 • 512 字节对齐:磁带的物理块大小通常是 512 字节或更大,tar 的对齐设计减少了磁带的块边界开销 • 可追加:在磁带末尾追加新文件非常自然,不需要重写整个磁带 • 容错友好:如果磁带某处损坏,只需跳过损坏的数据块,找到下一个有效的 Header 即可继续读取
4.2 从磁带到磁盘
随着硬盘容量增长和价格下降,tar 的使用场景从磁带备份扩展到了磁盘上的文件分发。1990 年代,互联网兴起,源代码的发布需要一个跨平台的归档格式。tar 成为了事实标准——不是因为它是最好的,而是因为它无处不在,每个 Unix 系统都有 tar。
4.3 GNU tar 的演进
GNU tar 在原始 Unix tar 的基础上做了大量扩展:
• 长文件名支持:通过 --format=posix(pax 格式)支持任意长度的文件名和路径• 增量备份: --listed-incremental选项支持增量备份,只归档自上次备份以来修改的文件• 多卷支持: --multi-volume选项支持将归档拆分到多个磁带或文件• 远程磁带: --rsh-command选项支持直接写入远程主机的磁带设备• 内置压缩: -z(gzip)、-j(bzip2)、-J(xz)选项可以直接调用压缩工具,无需手动管道
五、gzip 的历史——专利战争的产物
5.1 Unix compress 的专利困局
1980 年代,Unix 系统上最流行的压缩工具是 compress,它使用 LZW(Lempel-Ziv-Welch)算法。然而,LZW 算法被 Sperry(后来的 Unisys)申请了专利。这意味着使用 compress 的用户可能面临专利侵权风险。
5.2 gzip 的诞生
1992 年,Jean-loup Gailly 编写了 gzip,Mark Adler 编写了解压库 zlib。他们选择了 DEFLATE 算法——一个基于 LZ77 + Huffman 编码的组合算法,刻意避开了 LZW 专利。
gzip 的设计目标很明确:
1. 专利自由:不使用任何受专利保护的算法 2. 兼容替代:提供与 compress 相同的命令行接口,方便迁移 3. 更好的压缩率:DEFLATE 的压缩率优于 LZW 4. 开放标准:格式规范完全公开(RFC 1952)
5.3 gzip 与 zlib 的关系
很多人不清楚 gzip 和 zlib 的关系。它们使用相同的压缩算法(DEFLATE),但服务于不同的场景:
• gzip:完整的文件格式,包含头部、文件名、时间戳、CRC32 等。适合文件压缩 • zlib:轻量级的压缩库,只提供 DEFLATE/INFLATE 操作和简单的包装层。适合网络协议(HTTP、SSH、TLS)和文件格式(PNG、PDF)内嵌压缩
HTTP 协议中的 Content-Encoding: gzip 实际上用的是 zlib 的 deflate 包装,而不是完整的 gzip 文件格式。这种区分虽然微妙,但在开发中经常导致混淆。
了解了 tar 和 gzip 的历史渊源,现在我们可以深入看看它们的格式设计——为什么 tar 的 Header 是 512 字节?为什么 gzip 的 Magic Number 是 0x1f 0x8b?这些看似随意的数字背后,都有精确的设计理由。
六、tar 文件格式深度解析
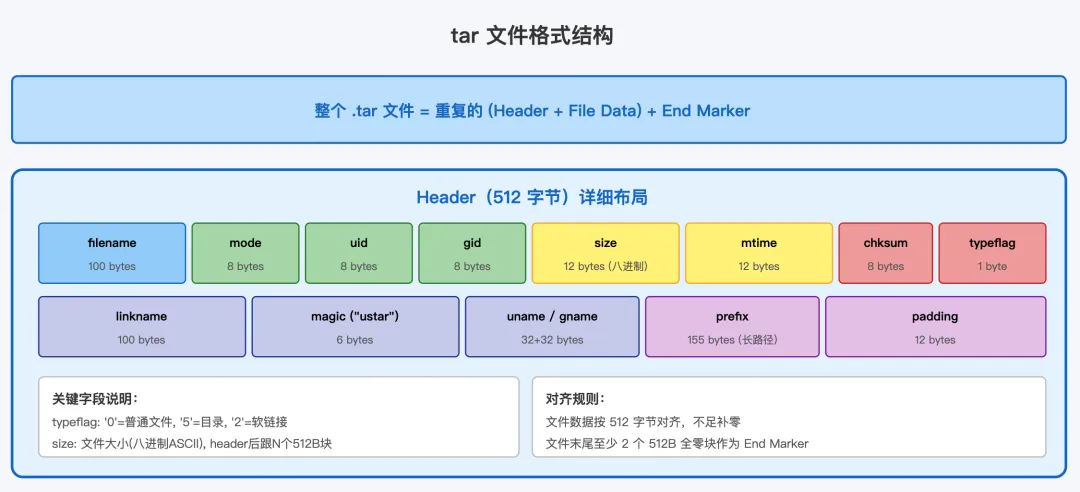
6.1 基本结构:Header + Data 的重复
tar 文件的格式极其简单,甚至可以说简陋——它就是一系列 "Header + Data" 的重复:
1. 512 字节的 Header,记录文件元数据 2. 文件内容,按 512 字节对齐(不足补零) 3. 下一个文件的 Header + Data... 4. 文件末尾至少两个 512 字节的全零块作为结束标记
6.2 Header 字段详解
tar 的 Header 是一个精心设计的数据结构,它最初是为了在磁带上记录文件信息而设计的:
• filename(100 字节):文件名,以 null 结尾的字符串。早期 POSIX tar 只支持 100 字节文件名,后来通过 prefix 字段扩展到 255 字节 • mode(8 字节):文件权限,以八进制 ASCII 表示,如 0100644表示普通文件、rw-r--r--• uid/gid(各 8 字节):文件所有者的用户 ID 和组 ID • size(12 字节):文件大小,以八进制 ASCII 表示。注意是八进制字符串,不是二进制数值 • mtime(12 字节):修改时间,Unix 时间戳,同样以八进制 ASCII 表示 • chksum(8 字节):Header 的校验和,用于检测磁带读取错误 • typeflag(1 字节):文件类型标志, '0'或'\0'表示普通文件,'5'表示目录,'2'表示软链接,'1'表示硬链接,'6'表示 FIFO 等• linkname(100 字节):软链接或硬链接的目标路径 • magic(6 字节): "ustar",表示这是 POSIX 标准的 tar 格式• prefix(155 字节):长路径前缀,与 filename 组合可表示最长 255 字节的路径
6.3 tar 格式的设计哲学
tar 格式有几个非常有趣的设计特点,反映了 1970 年代的技术约束和设计智慧:
全是 ASCII 文本:Header 中的数值字段(权限、大小、时间戳等)都用八进制 ASCII 表示,而不是二进制。这意味着你可以用 cat 或 od 命令直接查看 tar 文件头部的内容。这在调试时极为方便,也避免了字节序(endian)问题——大端和小端系统读取同一个 tar 文件都不会出错。
512 字节对齐:磁带的物理块大小通常是 512 字节或 1024 字节,tar 的对齐设计确保了磁带读取时不需要额外的块边界处理。
追加友好:tar 文件可以原地追加新文件,只需要删除末尾的结束标记(两个全零块),写入新的 Header+Data,再加回结束标记即可。这对于磁带这种顺序介质来说非常自然。
向前兼容:Header 中有 magic 字段标识格式版本,后续扩展(GNU tar、POSIX pax 扩展等)都通过新的 magic 值或扩展 Header 来实现,不会破坏旧版本的兼容性。
6.4 tar 格式的局限
tar 格式也有明显的局限:
• 不支持随机访问:要读取 tar 中的第 N 个文件,必须从头读取前 N-1 个文件的 Header 来计算偏移量。虽然 tar Header 中记录了文件大小,理论上可以跳过数据块,但这要求 tar 文件是存储在可寻址设备上的(对磁带无效) • 文件名长度限制:原始格式只支持 100 字节文件名,POSIX ustar 扩展后支持 255 字节,但对于极深嵌套的目录树仍然不够 • 无内置压缩:数据以原始形式存储,没有压缩支持 • 无校验文件内容的能力:Header 的 chksum 只校验头部,不校验文件内容。虽然 gzip 的 CRC32 可以间接提供文件内容校验,但这不是 tar 本身的功能
七、gzip 文件格式深度解析
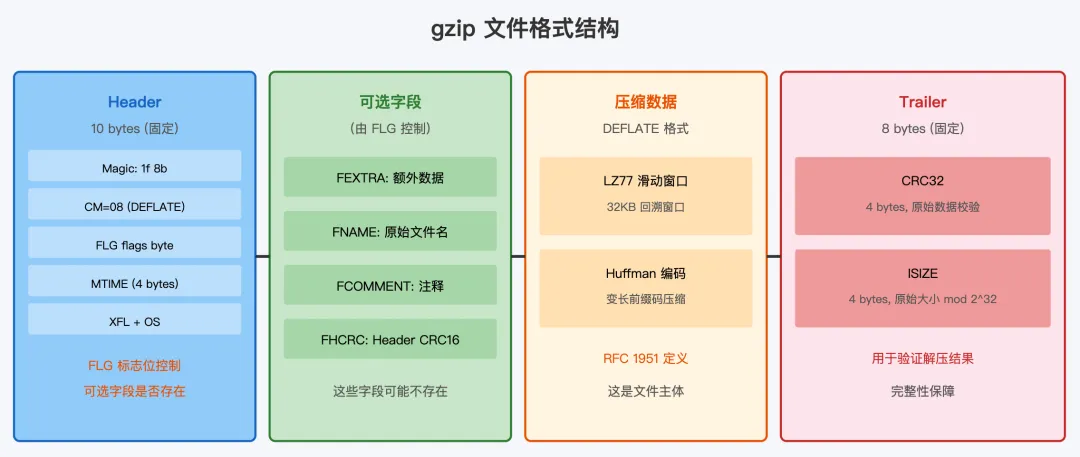
7.1 整体结构
gzip 文件由三部分组成:
1. Header(至少 10 字节):固定头部 + 可选字段 2. 压缩数据:DEFLATE 格式的压缩字节流 3. Trailer(8 字节):CRC32 校验和 + 原始数据大小
7.2 Header 详解
gzip 的固定 Header 只有 10 字节,极其紧凑:
0x1f 0x8b | |||
0x08(DEFLATE) | |||
FLG 标志位控制了可选字段的存在:
• FTEXT(bit 0):提示文件是 ASCII 文本 • FHCRC(bit 1):Header 后有 CRC16 校验 • FEXTRA(bit 2):有额外字段 • FNAME(bit 3):有原始文件名(null 结尾字符串) • FCOMMENT(bit 4):有注释
7.3 DEFLATE 压缩算法
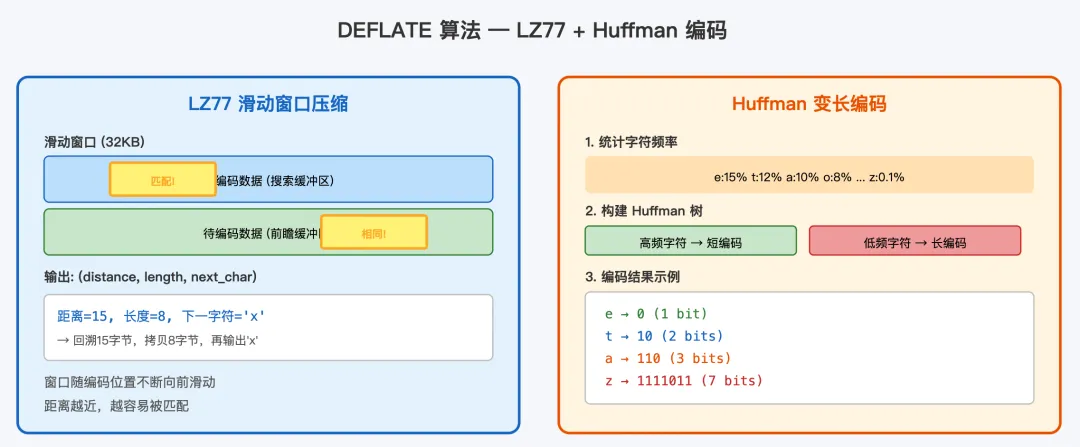
gzip 使用 DEFLATE 作为压缩算法,这是由 Phil Katz 为 PKZIP 设计的算法,后来被 RFC 1951 标准化。DEFLATE 是两阶段压缩的组合:
第一阶段:LZ77 滑动窗口
LZ77 算法使用一个 32KB 的滑动窗口在已编码数据中查找与当前待编码数据的匹配。如果找到匹配,就输出一个 (distance, length) 对,表示"回退 distance 字节,复制 length 字节"。如果没有匹配,就输出原始字节。
举个例子,假设数据中有这样的模式:
#include <stdio.h>#include <stdlib.h>第二行的 #include 与第一行完全相同,LZ77 会将其编码为 (distance=19, length=10),表示"回退 19 字节,复制 10 字节"。这样就避免了重复存储。
第二阶段:Huffman 编码
LZ77 的输出(字面字节和匹配引用)再经过 Huffman 编码。Huffman 编码的核心思想是:出现频率高的符号用短编码,频率低的用长编码。
例如,在 C 源代码中,字符 e、空格、换行出现频率很高,可以分别编码为 1-2 bit;而字符 z、Q 很少出现,编码为 7-8 bit。相比之下,固定长度编码(如 ASCII)每个字符都需要 8 bit。Huffman 编码平均可节省 20%-30% 的空间。
DEFLATE 中的 Huffman 编码有两种模式:
• 固定 Huffman 树:使用预定义的编码表,不需要额外空间存储编码表,适合小文件 • 动态 Huffman 树:根据实际数据频率构建最优编码表,编码表本身也存储在压缩流中,适合大文件
7.4 Trailer 的重要性
gzip 的 Trailer 包含两个关键字段:
• CRC32(4 字节):原始(未压缩)数据的 CRC32 校验和。这个校验和可以检测数据传输或存储中的错误,保证解压后的数据和原始数据一致 • ISIZE(4 字节):原始数据大小对 2^32 取模。这个值有两个用途:一是预分配解压缓冲区,二是验证解压结果的完整性
这两个字段使得 gzip 具有端到端的完整性校验能力,这对于网络传输和长期存储都非常重要。
八、zip 与 tar.gz——两种设计哲学的碰撞
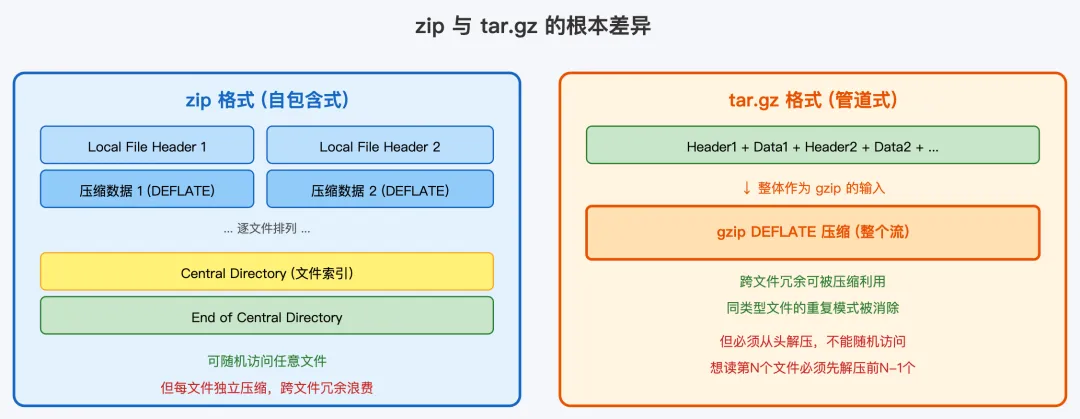
很多人会问:Windows 上 .zip 一统天下,一个文件搞定归档加压缩,为什么 Linux 要搞这么复杂的两步走?
8.1 zip 的设计:自包含式
zip 格式由 Phil Katz 于 1989 年创建(PKZIP),它的设计理念是自包含——每个文件在 zip 包中都有自己的 Local File Header 和压缩数据,文件末尾有一个 Central Directory 记录所有文件的索引信息。
这种设计的优势是随机访问:由于 Central Directory 记录了每个文件的偏移量,你可以直接跳转到某个文件的压缩数据并解压,无需解压整个包。这也是为什么 Windows 资源管理器可以直接打开 zip 文件浏览其中内容。
8.2 tar.gz 的设计:管道式
tar.gz 的设计理念是管道式——先归档成一个流,再整体压缩。gzip 看到的是一个连续的字节流,它不知道其中有多个文件,也不关心。
这种设计的优势是压缩效率:由于 gzip 是对整个 tar 流进行压缩,LZ77 的滑动窗口可以跨越不同文件之间的边界。比如多个 C 源文件中重复的头文件包含、相同的注释风格、相似的代码模式,这些跨文件的冗余在 zip 的逐文件压缩模式下无法被消除,但在 tar.gz 的整体压缩模式下可以被高效压缩。
8.3 实际对比
8.4 为什么 Linux 世界偏爱 tar.gz?
原因不仅仅是技术上的,还有文化和历史因素:
组合优于耦合:tar 做归档,gzip 做压缩,通过管道组合。你可以自由替换压缩工具——用 bzip2 替换 gzip 得到 .tar.bz2,用 xz 替换得到 .tar.xz,用 zstd 替换得到 .tar.zst。而 zip 将归档和压缩耦合在一起,替换压缩算法就意味着创建一种全新的格式。
流式友好:在 Unix 的管道世界中,数据以流的形式在进程间传递。tar.gz 天然适合这种模式——你可以在网络传输的同时进行压缩和解压:
# 通过 SSH 远程备份,数据流式传输tar -cf - /data | gzip | ssh user@remote 'cat > backup.tar.gz'元数据完整性:Linux 文件系统的元数据(权限、所有者、符号链接、设备文件等)比 Windows 丰富得多。tar 原生支持这些元数据,而 zip 对 Unix 元数据的支持是有限的、后来添加的,经常出现权限丢失或符号链接被解析的问题。
历史惯性:Linux 内核源码、GNU 工具链、各种开源项目从 1990 年代开始就以 .tar.gz 格式发布。整个生态的工具链(包管理器、构建系统、CI/CD)都围绕 tar.gz 构建。改变这种惯性需要的成本远超收益。
理解了 tar.gz 的设计思路,我们再来看看压缩格式的进化——gzip 之后的 30 年里,压缩算法取得了哪些进步?
九、压缩格式的进化——从 gzip 到 zstd
9.1 bzip2:更好的压缩率
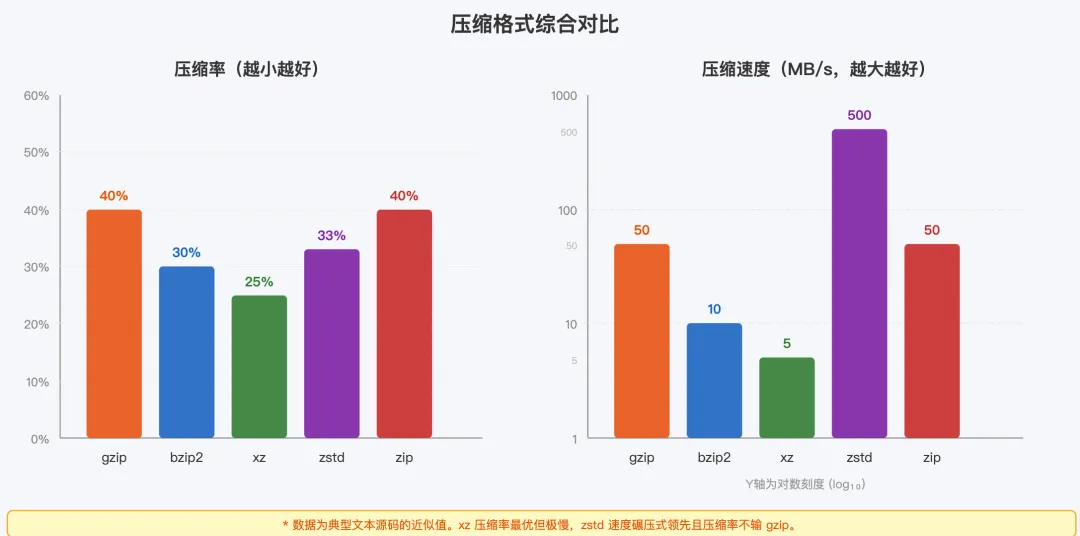
1996 年,Julian Seward 发布了 bzip2,使用 Burrows-Wheeler Transform(BWT)算法。bzip2 的压缩率比 gzip 高 10%-15%,但压缩速度慢了 5-10 倍。Linux 内核源码一度使用 .tar.bz2 格式发布,以节省带宽。
bzip2 的缺点是解压速度也较慢,且内存占用较高。随着网络带宽的提升,bzip2 的压缩率优势逐渐被速度劣势所抵消。
9.2 xz:极致的压缩率
2009 年,Lasse Collin 发布了 xz,使用 LZMA2 算法(Lempel-Ziv-Markov chain Algorithm 的改进版)。xz 的压缩率比 gzip 高约 30%,是目前常见格式中压缩率最高的。Linux 内核源码从 2014 年起改用 .tar.xz 格式发布。
xz 的代价是极慢的压缩速度(比 gzip 慢 10 倍以上)和较高的内存占用(压缩时可达数百 MB)。但对于发布后下载量巨大的项目来说,一次慢速压缩换来大量用户的下载时间节省,是划算的。
9.3 zstd:新时代的王者
2015 年,Facebook 的 Yann Collet 发布了 Zstandard(zstd),这个算法的出现堪称压缩领域的一次革命:
• 压缩速度:500 MB/s 以上,比 gzip 快 10 倍 • 压缩率:与 gzip 相当,在高速压缩模式下甚至更好 • 解压速度:超过 1 GB/s,是 gzip 的 2-3 倍 • 可调压缩级别:1-22 级,从极速压缩到极限压缩一应俱全 • 字典训练:可以对特定类型的数据(如 JSON 日志)训练字典,进一步提高压缩率
zstd 正在快速取代 gzip 成为新的默认压缩工具。Linux 内核从 2017 年开始支持 zstd 压缩的内核镜像和 initramfs,Arch Linux 的包格式已从 .tar.xz 迁移到 .tar.zst。
9.4 格式选择指南
.tar.gz | ||
.tar.xz | ||
.tar.zst | ||
.zip | ||
.tar | ||
十、tar.gz 的解压细节——你可能不知道的事
10.1 为什么是 -xzf?
tar -xzf archive.tar.gz这个命令的每个字母都有含义:
• -x:extract,解压(与-ccreate 对应)• -z:通过 gzip 解压(与-jbzip2、-Jxz 对应)• -f:指定文件名(必须放在最后,下一个参数是文件路径)
很多人不知道的是,-z 选项并不是 tar 的内置功能,而是 tar 自动调用系统的 gzip 程序来解压。等价于:
gzip -dc archive.tar.gz | tar -xf -10.2 为什么解压 tar.gz 比 zip 慢?
因为 tar.gz 必须从头解压整个 gzip 流,才能访问其中任何一个文件。而 zip 可以通过 Central Directory 直接跳转到目标文件的压缩数据。
这意味着,如果你只需要 zip 包中的一个文件,解压速度会快得多;但如果你需要解压整个包,tar.gz 的整体吞吐率可能更高(因为整体压缩减少了总数据量)。
10.3 tar.gz 的安全性问题
tar.gz 有几个值得注意的安全问题:
符号链接攻击:tar 保留符号链接,恶意构造的 tar 包可能包含指向系统敏感文件的符号链接。解压时如果使用 --preserve-permissions(默认行为),可能导致权限提升。应该使用 --no-same-permissions 或在不受信任的来源时先检查内容。
路径穿越:恶意构造的文件名可能包含 ../../etc/passwd 这样的路径,解压时文件会被写到预期目录之外。现代版本的 tar 默认会拒绝这种路径,但旧版本可能不会。
Zip 炸弹:虽然更常见于 zip 格式,但 tar.gz 也可以构造极端压缩的炸弹文件——一个几 KB 的压缩文件解压后可能膨胀到数 TB,耗尽磁盘空间。
10.4 tar.gz 与管道的组合妙用
tar.gz 的管道特性使得它非常适合组合使用:
# 通过 SSH 远程备份tar -czf - /data | ssh user@remote 'cat > backup.tar.gz'# 直接在远程解压ssh user@remote 'tar -czf - /remote/data' | tar -xzf -# 增量备份(只打包今天修改的文件)find /data -mtime -1 -print0 | tar -czf backup.tar.gz --null -T -# 查看压缩包内容不解压tar -tzf archive.tar.gz# 解压到指定目录tar -xzf archive.tar.gz -C /target/dir/# 只解压特定文件tar -xzf archive.tar.gz --wildcards '*.c'# 并行压缩(利用多核)tar -cf - /data | pigz > backup.tar.gz10.5 pigz:并行 gzip
gzip 的一个主要缺点是单线程——它只能使用一个 CPU 核心进行压缩。在多核时代,这严重浪费了计算资源。
pigz(Parallel Implementation of GZip)由 Mark Adler(zlib 的作者)开发,通过将数据分块并行压缩来利用多核。它的输出格式与 gzip 完全兼容,生成的 .tar.gz 文件可以用标准的 gunzip 解压。
对于大型数据备份,pigz 可以带来 4-8 倍的速度提升(取决于 CPU 核心数),而压缩率几乎不受影响。
十一、tar.gz 的替代格式——何时该换?
11.1 .tar.xz——极致压缩
适合场景:大文件分发,带宽昂贵,下载次数多。Linux 内核、大型软件的源码包常用此格式。
优点:压缩率最高,比 gzip 小 20%-30%。
缺点:压缩极慢(比 gzip 慢 10+ 倍),解压也较慢,内存占用高。
11.2 .tar.zst——未来的默认选择
适合场景:高频备份、CI/CD 产物、需要快速压缩/解压的场景。Arch Linux 已全面转向此格式。
优点:压缩速度比 gzip 快 10 倍,压缩率相当,解压速度更快。
缺点:较新的格式,老旧系统可能没有预装 zstd。
11.3 .tar.bz2——逐渐退出历史舞台
bzip2 曾经是 gzip 的主要替代者,但与 xz 和 zstd 相比,它在压缩率和速度上都没有优势。除了维护已有的 .tar.bz2 格式外,不推荐用于新项目。
11.4 .zip——跨平台的首选
如果你的文件需要在 Windows 和 Linux 之间共享,zip 是最安全的选择。但要注意:
• zip 对 Unix 文件权限的保留不完整 • 符号链接在 zip 中可能被解析为实际文件 • 压缩率略低于 tar.gz(无法利用跨文件冗余)
前面都在讲用户空间的工具和格式,那内核呢?Linux 内核是怎么看待 tar.gz 的?
十二、从内核视角看 tar.gz——一切都是字节流
12.1 VFS 与文件系统抽象
Linux 内核通过 VFS(Virtual File System)为用户空间提供了统一的文件操作接口。从内核的视角看,.tar.gz 文件只是一个普通的常规文件(regular file),它没有任何特殊的内核支持。
这意味着 tar 和 gzip 完全是用户空间的工具。内核不"知道"什么是 tar.gz,它只提供 read/write/mmap 等系统调用。这种设计符合 Unix 的核心哲学——内核提供最小化的机制,用户空间构建策略。
12.2 FUSE 与透明压缩
虽然内核不直接支持 tar.gz,但通过 FUSE(Filesystem in Userspace),我们可以实现透明压缩。例如 archivemount 工具可以将 tar.gz 挂载为文件系统,像普通目录一样浏览和访问:
archivemount archive.tar.gz /mnt/archivels /mnt/archive/src/main.ccat /mnt/archive/README.mdarchivemount 在用户空间处理解压和重压缩,内核不需要做任何修改。
12.3 内核中的压缩——initramfs
Linux 内核在启动时需要加载 initramfs(初始内存文件系统),这个文件系统通常以 gzip 压缩的 cpio 归档格式存在(cpio 是 tar 的替代归档格式)。内核内置了 gzip 解压代码,可以在启动时直接解压 initramfs 到内存中。
从 2017 年开始,Linux 内核也支持 zstd 压缩的 initramfs,启动速度更快。
十三、编程实践——在代码中处理 tar.gz
13.1 使用 libarchive
libarchive 是处理各种归档和压缩格式的最佳选择。它支持 tar、zip、cpio、gzip、bzip2、xz、zstd 等几乎所有常见格式,API 统一:
#include<archive.h>#include<archive_entry.h>// 读取 tar.gzstructarchive *a = archive_read_new();archive_read_support_format_tar(a);archive_read_support_filter_gzip(a);archive_read_open_filename(a, "backup.tar.gz", 10240);structarchive_entry *entry;while (archive_read_next_header(a, &entry) == ARCHIVE_OK) {printf("%s\n", archive_entry_pathname(entry)); archive_read_data_skip(a);}archive_read_free(a);13.2 使用 zlib + 手动解析 tar Header
如果不想引入 libarchive 依赖,可以直接使用 zlib 解压 gzip 流,然后手动解析 tar Header。虽然更底层,但可以更精细地控制内存和行为:
#include<zlib.h>gzFile f = gzopen("backup.tar.gz", "rb");char header[512];while (gzread(f, header, 512) == 512) {// 解析 tar headerchar filename[101];memcpy(filename, header, 100); filename[100] = '\0';long size = strtol(header + 124, NULL, 8); // 八进制 sizelong blocks = (size + 511) / 512;// 跳过文件数据for (long i = 0; i < blocks; i++) { gzread(f, header, 512); }}gzclose(f);13.3 Python 标准库
Python 的标准库 tarfile 模块原生支持 tar.gz:
import tarfile# 读取with tarfile.open('backup.tar.gz', 'r:gz') as tar: tar.list() tar.extractall(path='/target/dir')# 创建with tarfile.open('backup.tar.gz', 'w:gz') as tar: tar.add('src/')13.4 Go 标准库
Go 的标准库 archive/tar + compress/gzip 组合也很方便:
f, _ := os.Open("backup.tar.gz")gr, _ := gzip.NewReader(f)tr := tar.NewReader(gr)for { hdr, err := tr.Next()if err == io.EOF { break } fmt.Println(hdr.Name)}十四、tar.gz 的未来——会消失吗?
14.1 zstd 的崛起
zstd 正在快速侵蚀 gzip 的市场份额。Facebook/Meta、Google、Cloudflare 等大厂已经在内部全面转向 zstd。Linux 发行版(Arch、Fedora)也在迁移包格式。
zstd 的优势太明显了:同等压缩率下速度快 10 倍,同等速度下压缩率好 30%。对于新项目,没有理由不使用 zstd。
14.2 但 tar.gz 不会消失
尽管 zstd 在技术上全面超越 gzip,但 tar.gz 不会在短期内消失:
• 兼容性:每个 Unix 系统都有 gzip,但不一定有 zstd。在嵌入式系统、老旧服务器、最小化容器镜像中,gzip 是唯一可靠的压缩工具 • 标准惯性:HTTP 协议、邮件协议、包管理器、构建系统都内置了对 gzip 的支持 • 零成本依赖:gzip 和 zlib 是 C 标准库之外的"准标准库",几乎所有平台都预装 • 简单可靠:gzip 的代码已经稳定运行了 30 年,经过了几十亿次实际使用的验证
14.3 tar 的未来:与压缩算法解耦
tar 的设计哲学——归档与压缩解耦——正在被证明是极其明智的。随着压缩算法的不断进化,tar 只需要换一个后缀就能支持新算法:
.tar.gz → gzip (1992).tar.bz2 → bzip2 (1996).tar.lzma → lzma (2000).tar.xz → xz (2009).tar.lz4 → lz4 (2011).tar.zst → zstd (2015)如果当初 tar 内置了 gzip,我们可能还在用着 1992 年的压缩算法。
十五、总结
回到最初的问题:为什么 Linux 的压缩文件都是 tar.gz,而不是 .tar 或 .gz?
答案很明确:
1. .tar只归档不压缩,文件太大,不适合网络传输和长期存储2. .gz只压缩不归档,无法处理多文件和目录结构,丢失元数据3. .tar.gz结合了两者优势——tar 保留完整的文件系统和元数据,gzip 提供高效的压缩
更深层的答案是:tar.gz 是 Unix 哲学的完美体现。
每个工具只做一件事,通过管道组合完成复杂任务。这种设计看似"麻烦",实则提供了最大的灵活性——你可以自由选择归档工具(tar、cpio)和压缩工具(gzip、bzip2、xz、zstd),而不必等待某个"一体化"工具的更新。
当你下次敲下 tar -xzf 的时候,不妨想一想:这个看似平常的命令背后,是 50 年的 Unix 设计哲学、专利战争的余波、算法演进的智慧,以及无数工程师对简洁与优雅的执着追求。
交流方式:

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 一文吃透 Linux 和 Windows 虚拟内存:从页表到换页,真正在生产里怎么跑
- Linux 最新资讯 20260510——Debian Release Team: Debian必须提供Reproducible Packages
- ARM Linux Core Dump高阶调试:gdb分析内存映射与异常访问
- Ruff:打造无错误、高可维护性Python代码的现代化代码检查工具
- Quasar Linux RAT(QLNX):一种用于隐蔽和持久化的无文件 Linux 植入工具
- Python10个高频脚本:上班摸鱼,效率直接拉满!
- 程序员必备!Python 常用库完整大盘点
- 针对Linux的隐形杀手:QLNX无文件化RAT,七种持久化机制直击企业服务器
- Linux超高危漏洞!网络安全一周新闻速看(20260510期)
- 手把手教你学Linux内存管理
