在虚拟现实(VR)与增强现实(AR)快速发展的今天,人们对于“真实三维显示”的需求越来越强烈。然而,目前主流的3D显示技术大多依赖双目视差,本质上仍属于视觉欺骗,并不能真正重建光场信息。因此,这类方法往往存在视觉疲劳、焦点冲突等问题。
相比之下,计算全息(Computer-Generated Holography, CGH)通过直接调制光波的相位信息,可以实现真正意义上的三维成像,被认为是下一代显示技术的重要方向。然而,传统CGH方法计算复杂度极高,很难实现实时运行。
本期复现2021年发表在Nature上的论文《Towards real-time photorealistic 3D holography with deep neural networks》,介绍一种利用深度学习实现实时三维全息生成的方法(我们用pytorch架构进行了代码重写)。该方法在保证高质量成像的同时,实现了接近视频帧率的实时性能,为全息显示的工程应用提供了新的可能。
一、引言
传统的三维显示方法虽然能够提供一定的空间感,但由于缺乏真实的光场信息,始终无法达到自然视觉的效果。而全息显示则通过记录和重建光波的振幅与相位,使得观察者可以从不同角度看到不同的视图,同时具备真实的焦点变化和遮挡关系。
然而,全息显示面临的核心问题在于计算复杂度。以Fresnel衍射为例,其计算过程通常涉及大规模傅里叶变换和复数运算,当分辨率达到百万级像素时,计算量会急剧增加。这使得传统方法难以满足实时性要求,限制了其在实际系统中的应用。
近年来,随着深度学习的发展,人们开始尝试用神经网络来逼近复杂的物理过程。这为解决全息计算中的效率问题提供了一条新的思路。
二、基本原理
该方法的核心思想是利用深度神经网络学习从二维图像到全息图的映射关系。具体而言,网络的输入为RGB图像及其对应的深度图,输出为相位型全息图。
在传统方法中,从图像生成全息图需要经过波动光学计算,即模拟光从物体传播到成像面的过程。而在本文方法中,这一复杂的计算过程被一个卷积神经网络所替代。网络通过大量训练数据学习这种映射关系,从而在推理阶段可以快速生成结果。
为了保证生成结果的物理正确性,作者在训练过程中引入了可微分的光传播模型。具体做法是:将网络输出的全息图输入到一个模拟光传播的模块中,得到重建图像,并与目标图像进行比较。通过这种方式,网络不仅学习数据分布,还受到物理规律的约束。
三、方法实现
在数据层面,作者构建了一个包含数千组样本的数据集。每一组数据包括RGB图像、深度信息以及通过传统方法计算得到的高质量全息图。这些数据为神经网络的训练提供了监督信号。
在网络结构方面,通常采用编码器-解码器(Encoder-Decoder)结构,通过逐层提取特征并重建输出,实现从图像到相位分布的转换。由于输入中包含深度信息,网络可以更好地理解场景的三维结构,从而生成更加准确的全息图。
在损失函数设计上,除了常规的图像重建误差之外,还引入了基于光传播的约束,使得输出结果在物理上具有一致性。此外,为了改善视觉质量,方法中还采用了抗混叠的相位编码策略,从而有效降低散斑噪声。
四、评价
实验结果表明,该方法在性能上具有显著优势。在全高清分辨率(1920×1080)下,系统可以实现约60帧每秒的实时运行速度,已经满足视频显示的需求。同时,模型参数量非常小,仅为数百KB级别,可以部署在移动设备上运行。
在图像质量方面,生成的全息图在重建后具有较高的清晰度和较低的噪声水平,相比传统方法具有更好的视觉效果。这表明深度学习方法不仅在速度上具有优势,同时在质量上也能够达到甚至超过部分传统算法。
传统CGH方法基于严格的物理模型,具有较高的精度,但计算复杂度高,难以实现实时处理。而基于深度学习的方法通过离线训练,将复杂计算转移到训练阶段,在推理时仅需一次前向传播即可得到结果,从而大幅提升速度。
当然,这种方法也存在一定局限性,例如依赖训练数据的质量与分布,以及在极端场景下的泛化能力问题。但总体来看,其在效率与效果之间取得了良好的平衡。
五、仿真结果
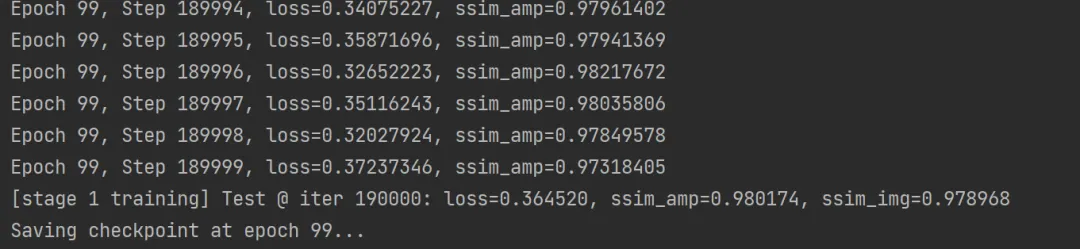
训练99轮结果
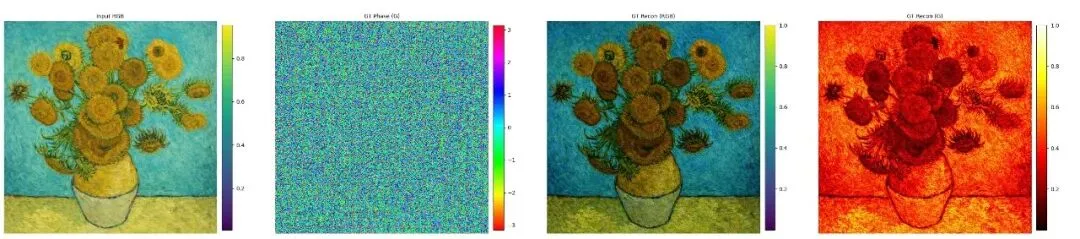
预测结果
自定义数据集预测结果
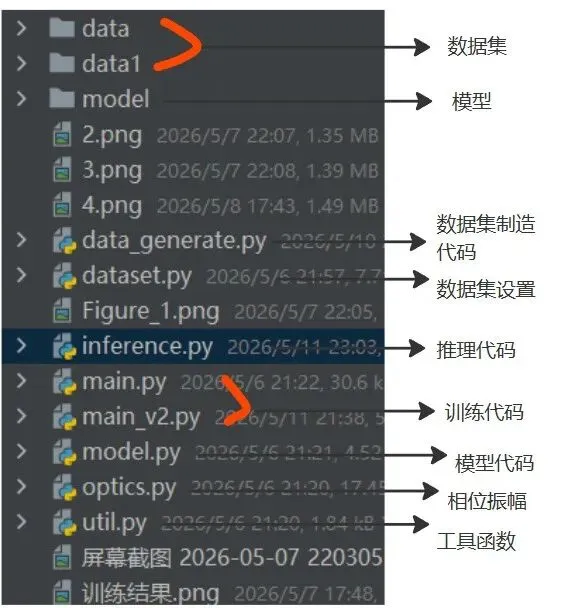
代码架构




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
