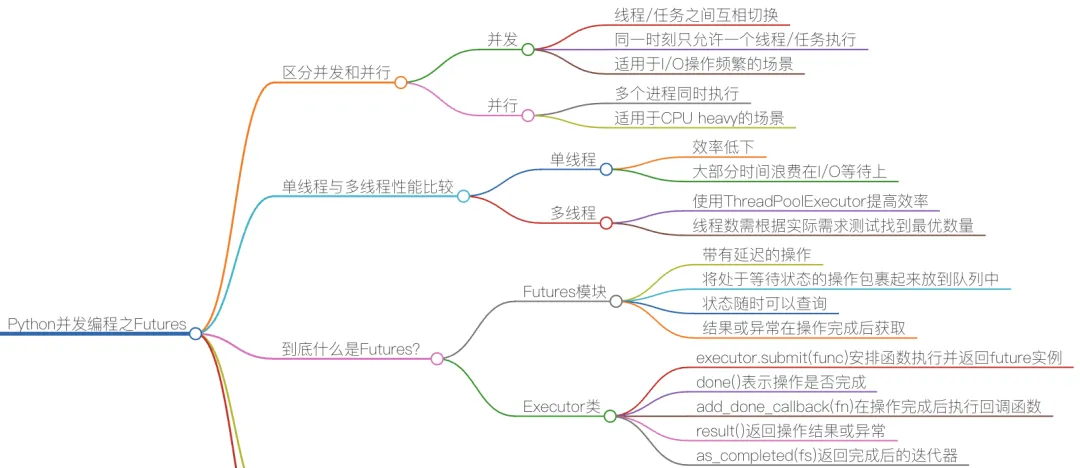
并发(Concurrency)并发并不是同一时刻有多个任务同时进行,相反,某个特定时刻,它只允许一个操作发生,只不过线程/任务之间会互相切换,直到完成.并行(Parallelism)指的是系统真正同时执行多个任务,需要多核CPU,GPU等硬件条件特性 | 并发(Concurrency) | 并行(Parallelism) |
目标 | 高效管理多任务 | 加速任务执行 |
执行方式 | 交替执行(逻辑同时) | 真正同时执行(物理同时) |
硬件依赖 | 单核即可实现 | 必须多核/多机 |
典型应用 | I/O密集型、高响应系统 | 计算密集型任务 |
在Python中,futures允许你提交任务(如函数调用)到线程池或进程池,并通过Future对象跟踪任务状态,获取结果或添加结果回调.类 | 作用 | 适用场景 |
ThreadPoolExecutor | 线程池(I/O密集型任务) | 网络请求、文件读写等 |
ProcessPoolExecutor | 进程池(CPU密集型任务) | 计算密集型任务(如数学计算) |
Future | 表示异步计算的结果(通过 submit() 返回) | 获取任务状态或结果 |
方法/属性 | 作用 |
future.result() | 阻塞直到任务完成并返回结果(可设置超时 timeout)。 |
future.done() | 返回 True 如果任务已完成(包括取消或异常)。 |
future.cancel() | 尝试取消任务(成功返回 True,否则 False)。 |
future.add_done_callback(fn) | 添加回调函数,任务完成时自动调用。 |
futures.as_completed | 接收一个 Future 对象的可迭代集合(如列表),返回一个迭代器,按照任务完成的顺序(谁先完成谁先返回)生成 Future 对象 |
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor# 使用线程池(默认线程数为 CPU 核心数 * 5)with ThreadPoolExecutor(max_workers=4) as executor: pass# 使用进程池(默认进程数等于 CPU 核心数)with ProcessPoolExecutor() as executor: pass
import requestsimport timeimport threadingimport concurrent.futuresdef download_one(url): resp=requests.get(url) print(f"read {len(resp.content)} from {url}")def download_all(sites): for site in sites: download_one(site)def main(): sites=[ 'https://www.baidu.com', 'https://www.ctrip.com', 'https://www.douban.com/', 'https://www.youku.com', 'https://www.deepseek.com/', 'https://time.geekbang.org/', 'https://leetcode.cn/' ] start_time=time.perf_counter() download_all(sites) end_time=time.perf_counter() print(f"download {len(sites)} in {end_time-start_time} seconds")if __name__=='__main__': main()
import requestsimport timeimport threadingimport concurrent.futuresdef download_one(url): resp=requests.get(url) print(f"read {len(resp.content)} from {url}")def download_all(sites): with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor: to_do = [] for site in sites: future = executor.submit(download_one, site) to_do.append(future) for future in concurrent.futures.as_completed(to_do): future.result()def main(): sites=[ 'https://www.baidu.com', 'https://www.ctrip.com', 'https://www.douban.com/', 'https://www.youku.com', 'https://www.deepseek.com/', 'https://time.geekbang.org/', 'https://leetcode.cn/' ] start_time=time.perf_counter() download_all(sites) end_time=time.perf_counter() print(f"download {len(sites)} in {end_time-start_time} seconds")if __name__=='__main__': main()
如果是I/O Bound(I/O密集型),并且I/O操作很慢,需要多任务/线程协同实现,这个时候使用Asyncio更适合如果是I/O Bound,但是I/O操作很快,只需要有限数量的任务/线程,那么使用多线程如果是CPU bound,则需要使用多进程来提高程序效率
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
