Linux 网络栈在 RDMA 场景下的角色
- 2026-06-27 11:45:46
这里是「算力网络架构手记」北京
专注 AI 集群网络架构与性能优化
深入 GPU×RoCE×NCCL×K8s 跨层瓶颈
只拆真实问题,不写概念科普
👇 试听内容
👉 AI 训练网络全路径拆解视频课 → 私信:AI网络
👉 AI 推理网络全路径拆解视频课 → 私信:推理
👉 AI 网络架构工程指南手册 → 私信:工程指南
👉 AI 算力网络架构系统视频课(真机实验环境) → 私信:系统
👉 日常工作1对1答疑 → 私信:答疑
00
给Linux 网络栈正名
凡是接触过 RDMA 的人,都会听到一句话:
RDMA 绕过 Linux 内核协议栈,直接在网卡和用户态之间搬数据。
这句话确实没错。
但如果只记住这一句,就很容易走向另一个误区:
既然 RDMA 绕过 Linux 网络栈,那 Linux 网络栈是不是就不重要了?
恰恰相反。
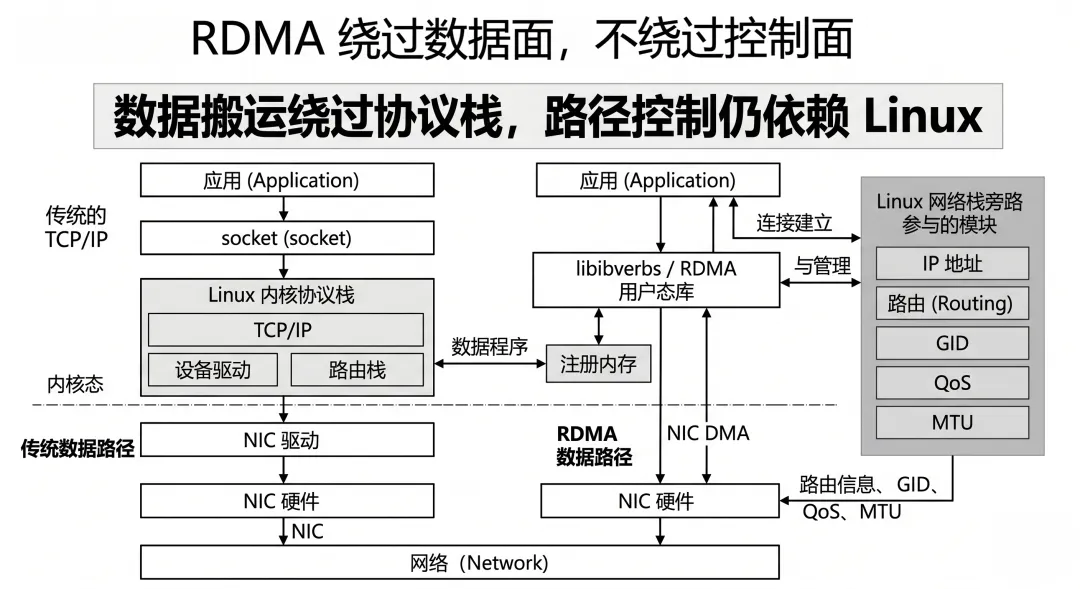
在真实 AI 集群里,尤其是 RoCE 场景下,Linux 网络栈虽然不再负责每一个数据包的传统 TCP/IP 转发路径,但它依然深度参与:
网卡设备识别 IP / 路由 / GID 选择 多网卡路径控制 DSCP / ECN 标记 MTU / VLAN / bonding / policy routing RDMA CM 建连 NCCL 选卡与路径推导 故障排查与可观测性
所以更准确的说法应该是:
RDMA 数据面可以绕过 Linux 网络栈。但 RDMA 控制面、路径选择、QoS 入口,离不开 Linux 网络栈。
01
不是“不要 Linux 网络栈”,而是“数据搬运绕过传统协议栈”
如果只把 RDMA 理解成:
数据不走内核,所以 Linux 网络栈没用了。
这肯定是不准确的。
RDMA 真正绕过的是传统数据搬运路径中的很多内核参与:
不需要应用把数据 copy 到内核 socket buffer 不需要内核逐包处理 TCP/IP 数据面 不需要 CPU 逐包参与协议栈收发 网卡可以通过 DMA 直接读写用户态注册内存
这就是 RDMA 高性能的关键。
但在 RoCE 里,数据包本身依然是以太网 / IP / UDP / RoCEv2 形式在网络里跑。它依然需要:
IP 地址 路由表 网卡接口 GID MTU QoS 标记 设备状态
这些东西从哪里来?
很多都来自 Linux 网络栈和 RDMA 子系统之间的配合。
所以一句话总结:
RDMA 绕过的是“传统数据路径”,不是绕过整台 Linux 主机的网络控制体系。
这个结论很重要。否则你会在排障时犯一个典型错误:
只盯 RDMA 工具,不看 Linux 网络配置。
结果发现:
ib_write_bw 跑不通 GID 选错 多网卡只用一张 DSCP 没打上 策略路由不生效 NCCL 选错接口
最后才发现,根因还在 Linux 网络侧。
02
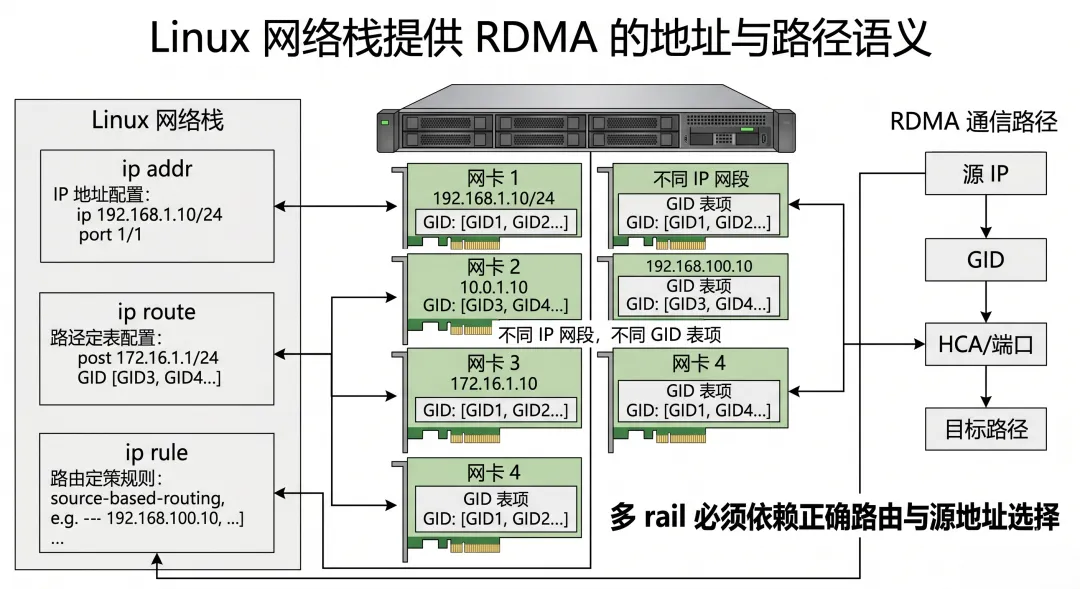
Linux 网络栈第一角色:提供“地址与路径语义”
RDMA 要通信,首先要知道:
对端是谁?从本机哪张网卡出去?走哪条路?
在 RoCE 场景下,这就绕不开 Linux 网络栈。
因为 RoCEv2 本质上跑在 UDP/IP 之上。它需要 IP 地址作为路径语义。
所以你配置的:
ip addrip linkip routeip ruleVLAN MTU
都会影响 RDMA 最终怎么走。
1)为什么 IP 地址对 RoCE 很关键?
很多人以为 RDMA 只认 HCA,不认 IP。这在 InfiniBand 场景里很好理解。
但 RoCEv2 不一样。
RoCEv2 的 GID 往往和 IP 地址存在对应关系。你在网卡上配置的 IP,会影响 GID 表项。
如果 IP 配错、接口没 up、VLAN 不对、GID index 选错,RDMA 通信就可能:
建连失败 走错接口 用错源地址 选错 GID 对端无法匹配
所以在 RoCE 里,Linux 网络配置不是装饰。
它直接参与 RDMA 地址选择。
2)为什么路由也很关键?
假设一台 GPU 服务器有 8 张 RoCE 网卡。
你希望:
172.16.1.x 走 NIC1 172.16.2.x 走 NIC2 172.16.3.x 走 NIC3 每条 rail 都独立
如果 Linux 路由没有写对,会发生什么?
最常见的结果是:8 张网卡,实际只从一张出去。
或者更麻烦:
请求从 NIC1 出去 回包从 NIC2 回来 RDMA CM 建连异常 perftest 行为不一致 NCCL 多轨用不起来
所以多轨 RoCE 里,Linux 路由和策略路由非常关键。
3)用一句话总结
RoCE 的数据面可以绕过内核搬数据,但“从哪张网卡出去、用哪个源 IP、匹配哪个 GID”,仍然离不开 Linux 网络栈。
03
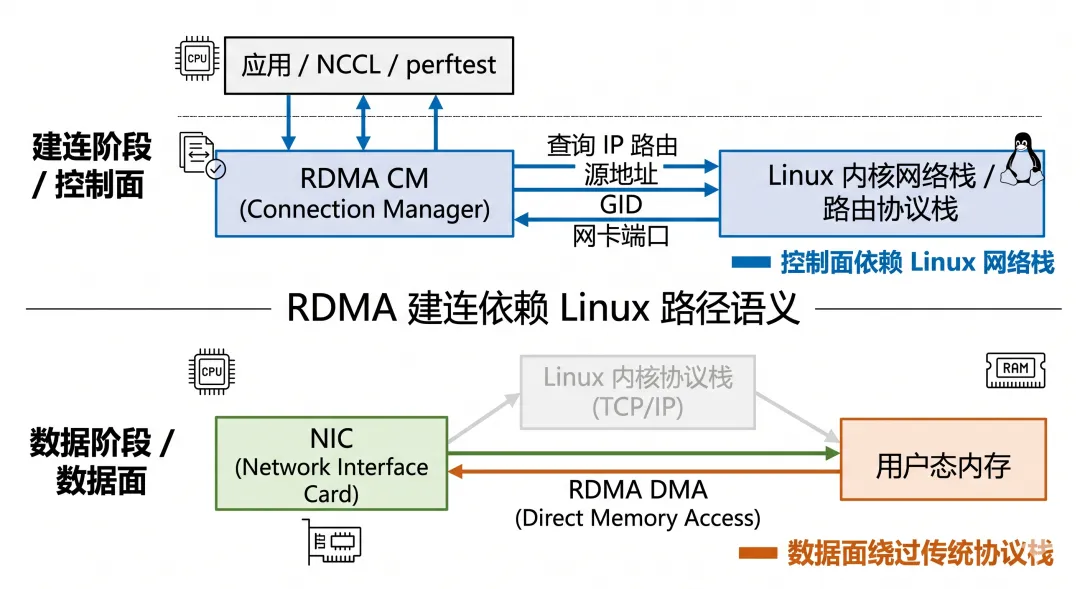
Linux 网络栈第二角色:帮助 RDMA 完成建连
RDMA 通信不是一开始就能直接把数据扔到对端内存里。
它要先建立连接关系。
典型信息包括:
QP number PSN GID / LID rkey virtual address MTU path 信息
在 RoCE 里,如果使用 RDMA CM 建连,它会用到 Linux 网络栈提供的 IP 路由能力来解析路径。
这就是很多人容易混淆的点:
RDMA 数据传输不走传统 socket 数据面。但 RDMA 建联和路径解析,可能仍然依赖 Linux 的 IP / 路由语义。
1)为什么 ib_write_bw 有时加 -R 行为会不同?
很多人在 perftest 里会遇到类似现象:
不加 -R可以加了 -R不行或反过来
这里的 -R 通常表示使用 RDMA CM。
一旦使用 RDMA CM,路径解析就更依赖 IP / 路由 / 源地址选择。
如果你的策略路由不对,或者源地址与目标路径不一致,现象就可能非常诡异。
这时候问题不一定在 RDMA 本身。可能在:
Linux 路由表 ip rule源地址选择 多网卡反向路径 GID index 对应关系
2)为什么这对 NCCL 也重要?
NCCL 在建立跨节点通信时,也需要发现和选择可用网络接口。
它会根据:
接口名 IP 地址 可达性 HCA 拓扑 环境变量
来决定最终使用哪些路径。
如果 Linux 网络层把接口、地址、路由搞乱,NCCL 看到的世界也会乱。
所以你会看到:
NCCL 只用了一张网卡 多轨不均衡 部分 rank 连接失败 Bootstrap 阶段卡住 IB / RoCE 路径不符合预期
这不是 NCCL “玄学”。
很多时候,是 Linux 网络语义没有对齐。
3)用一句话总结
RDMA 的数据传输可以不靠 Linux TCP/IP 数据面,但 RDMA 的建连、寻路、接口选择,仍然会被 Linux 网络栈深刻影响。
04
Linux 网络栈第三角色:决定 RoCE QoS 的入口标签
在 RoCE 网络里,QoS 非常关键。
尤其是 AI 训练和推理场景:
NCCL AllReduce 容易产生 Incast RoCE 对丢包敏感 ECN / DCQCN 需要提前反馈 PFC 作为最后兜底 DSCP / priority / TC 必须对齐
这时候,Linux 网络栈又开始扮演一个很重要的角色:
给流量打上正确的分类标签。
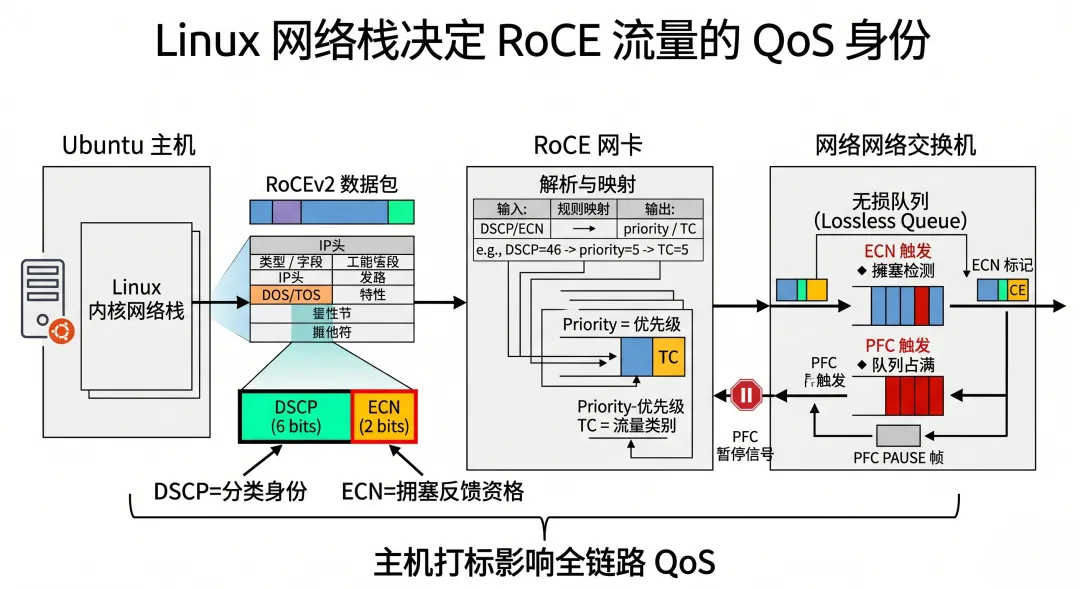
1)DSCP / ToS 从哪里来?
RoCEv2 是 IP 包。IP 头里有 ToS / Traffic Class 字段。
其中:
高 6 bit 是 DSCP 低 2 bit 是 ECN
如果主机侧没有设置 DSCP,交换机就很难知道:
这个包是不是 RDMA 业务?它该进哪个 priority / TC?它该不该进入 lossless / ECN 队列?
所以,Linux 主机侧是否正确设置 ToS / DSCP,会影响整个 RoCE QoS 链条。
2)为什么 ECN 位也重要?
如果包不是 ECT,交换机即使看到拥塞,也不能把它标成 CE。
那 DCQCN 这条链就断了:
交换机无法有效反馈拥塞 接收端不会产生对应 CNP 发送端不会按预期降速 最后更容易走到 PFC pause
所以 RoCE QoS 不是只靠交换机。
服务器侧发出去的包,必须具备正确的标签和 ECN 能力。
3)Linux 网络栈在这里的意义是什么?
它提供了这些入口:
应用设置 socket / traffic class 系统策略设置 DSCP tc/ iptables / nftables 做分类标记驱动 / RDMA 栈映射到对应 priority NIC 根据 trust / QoS 策略进入对应 TC
所以 Linux 网络栈不是在每个 RDMA 数据包上做传统转发,但它负责给这些包定义“身份”。
4)用一句话总结
在 RoCE QoS 里,Linux 网络栈不一定搬数据,但它经常决定这类数据包带着什么身份进入网络。
05
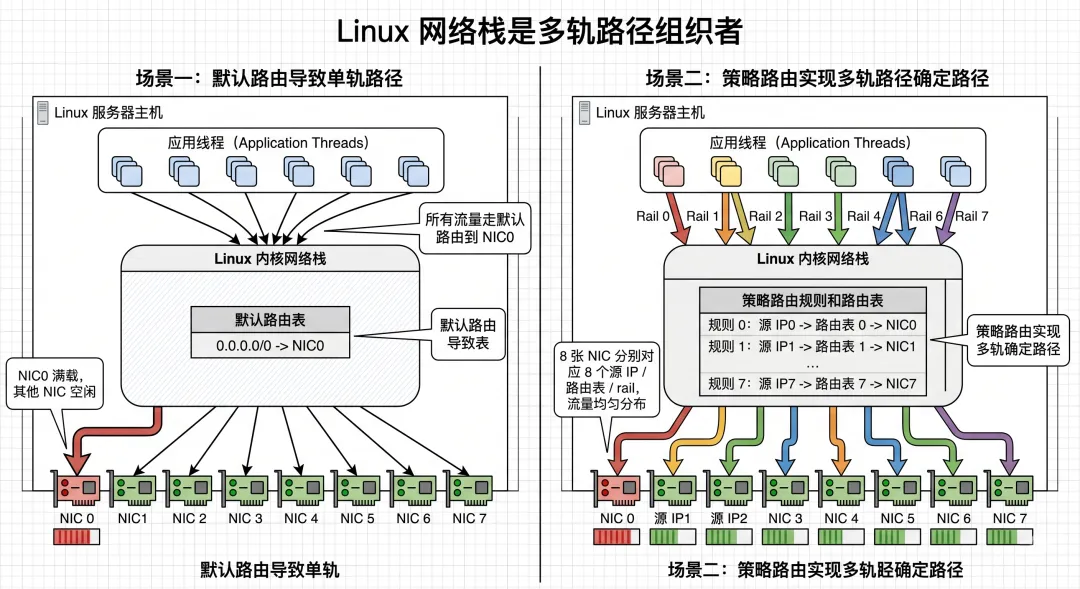
Linux 网络栈第四角色:多网卡 / 多轨网络的路径组织者
AI 训练服务器经常不是一张网卡。
而是:
4 张 NIC 8 张 NIC 甚至 8 rail 多轨网络
这时候,Linux 网络栈的角色就更明显了。
因为多网卡不是“插上就自动均衡”。
你必须解决几个问题:
每个接口的 IP 怎么规划 每个网段从哪个接口出去 回包从哪条路回来 多个 rail 是否真正独立 NCCL 是否能看到并使用这些接口
如果这一步没做好,结果很典型:
物理上是多轨,逻辑上是单轨。
1)默认路由为什么会害你?
如果一台服务器有 8 张网卡,但只有一条默认路由,Linux 可能会把大量流量都导向同一个出口。
你看到的是:
8 张网卡都 up IP 都配置了 但流量只走一张 NCCL 带宽叠不上去
这不是多轨网络没用。
是 Linux 路由没有把多轨组织起来。
2)策略路由为什么重要?
在多 rail RoCE 中,经常需要:
根据源 IP 选路 每个接口独立路由表 保证请求和响应路径一致 避免流量跨接口乱跑
这就是 ip rule 和多路由表的重要性。
它的目标不是“炫技”,而是让系统明确知道:
从这个源地址发出的流,就应该走这张网卡。
3)为什么这会影响 RDMA?
因为 RoCE 通信中源地址、GID、接口、路径是强相关的。
一旦源地址选错,可能导致:
GID 不匹配 对端不可达 RDMA CM 路径错误 NCCL bootstrap 异常 多轨不均衡
所以多轨 RoCE 不是只配交换机。
Linux 服务器侧同样是核心。
4)用一句话总结
多轨网络能不能用起来,很大一部分取决于 Linux 是否把“多张网卡”组织成“多条确定路径”。
06
Linux 网络栈第五角色:可观测性入口
RDMA 性能问题,最后常常表现为:
带宽跑不满 延迟抖动 NCCL 慢 GPU 利用率上不去 某些 rank 拖后腿
很多人第一反应是看 RDMA 工具。
这是对的,但不够。
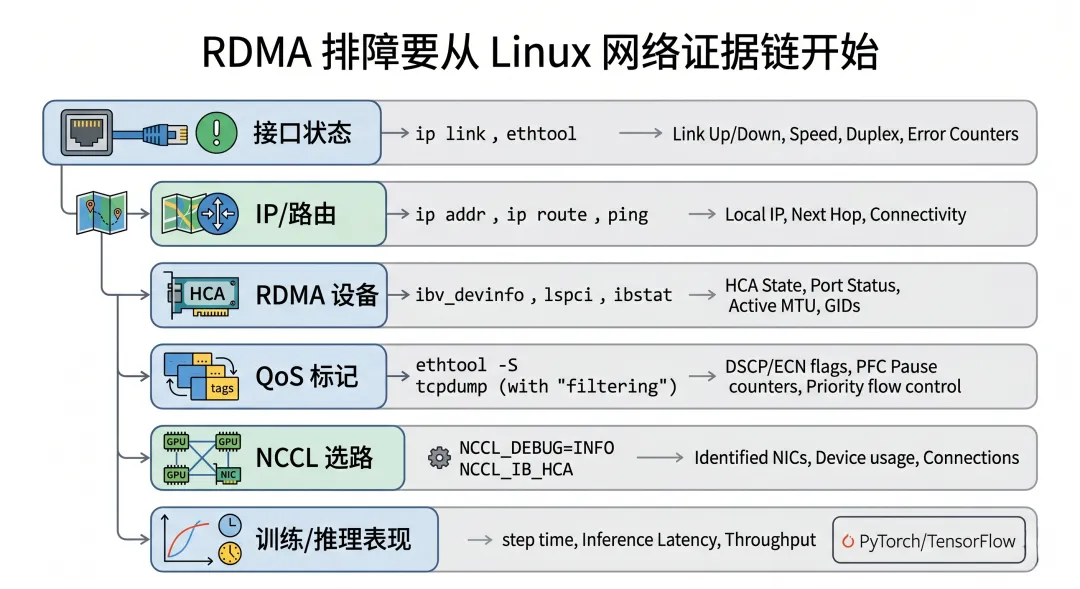
因为你还要看 Linux 网络侧的基础状态:
接口是否 up 速率是否正确 MTU 是否一致 IP / 路由是否正确 队列统计是否异常 丢包 / error / pause 计数 DSCP / ECN 是否真的出现在包头 多接口是否流量均衡
这些都是 Linux 网络栈和驱动提供的可观测性入口。
1)为什么不能只看 ib_write_bw?
ib_write_bw 能告诉你:
某条 RDMA 路径能不能跑 带宽大概多少 延迟是否异常
但它不一定告诉你:
NCCL 是否选了同一条路径 多轨是否均衡 业务包是否打了 DSCP Linux 路由是否和测试路径一致 真实训练是否形成 Incast
所以工具要分层看。
2)常见排查链路应该怎么组织?
可以按这个顺序:
Linux 接口状态 ip link,ethtool, MTU, speedIP / 路由 / 策略路由 ip addr,ip route,ip ruleRDMA 设备状态 ibv_devinfo,rdma link, GID tableQoS 状态DSCP / ECN / priority / TC / pause / CNP NCCL 层 NCCL_DEBUG=INFO, HCA 选择, rail 利用率训练 / 推理业务层step time, TTFT, token latency, GPU wait
这条链路很重要。
因为 RDMA 问题很少只属于某一层。
3)用一句话总结
RDMA 排障不能只看 RDMA。Linux 网络栈提供了地址、路径、QoS、接口状态这些关键证据。
07
为什么说 RDMA 数据面“绕过内核”,但不是“绕过 CPU 和操作系统的一切”?
RDMA 确实可以减少 CPU 在数据搬运中的参与。
但这不代表 CPU 和 OS 完全没关系。
原因有几个。
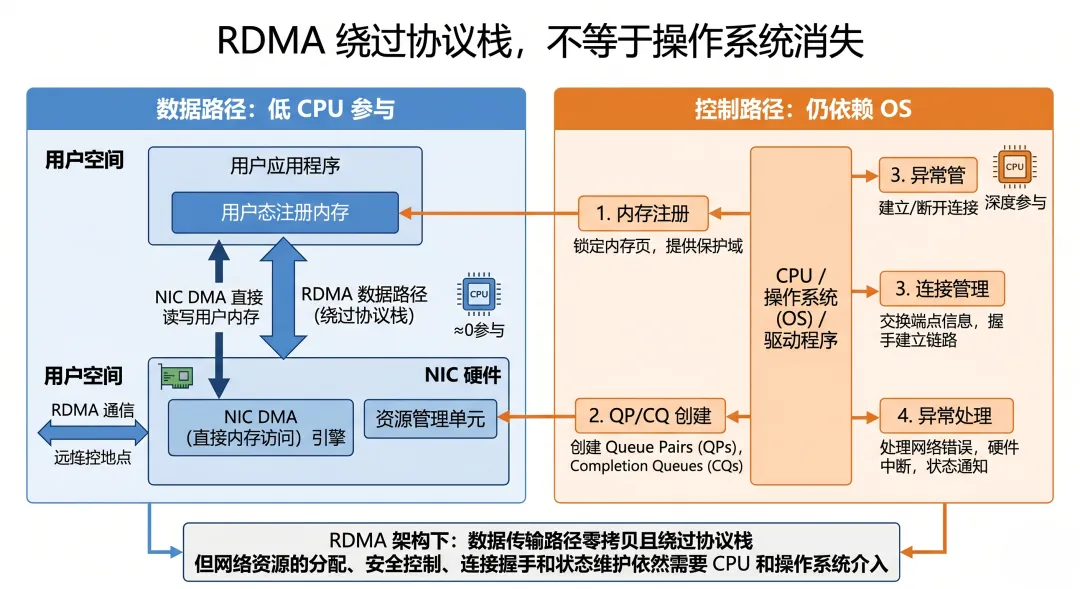
1)内存注册需要操作系统参与
RDMA 需要使用注册内存。
注册过程涉及:
pin memory memory region lkey / rkey 地址权限 IOMMU / DMA 映射
这些都离不开操作系统和驱动。
2)控制路径仍然需要 CPU
QP 创建、CQ 轮询、事件处理、连接管理,这些仍然需要 CPU 参与。
只是数据 payload 的搬运不再走传统协议栈 copy 路径。
3)异常处理也离不开系统
比如:
CQE 异常 QP 状态变化 link down path migration device reset error counter
这些都需要系统侧参与观测和处理。
4)用一句话总结
RDMA 减少的是数据搬运路径上的 CPU 和内核协议栈开销,不是让操作系统从通信系统里消失。
这很重要,否则你会误以为:
RDMA 慢了,一定是网卡或交换机问题。
不一定。
可能是:
内存注册方式不合理 CPU 亲和差 NUMA 不对 CQ 轮询线程被抢占 IRQ / softirq 干扰 用户态库和驱动版本不匹配
这些仍然和 Linux 系统强相关。
08
在 AI 训练场景里,Linux 网络栈为什么会影响 NCCL 和 AllReduce?
AI 训练网络里,最终真正使用 RDMA 的往往是 NCCL。
NCCL 做的是 collective 通信,比如:
AllReduce ReduceScatter AllGather
这些通信对网络非常敏感。
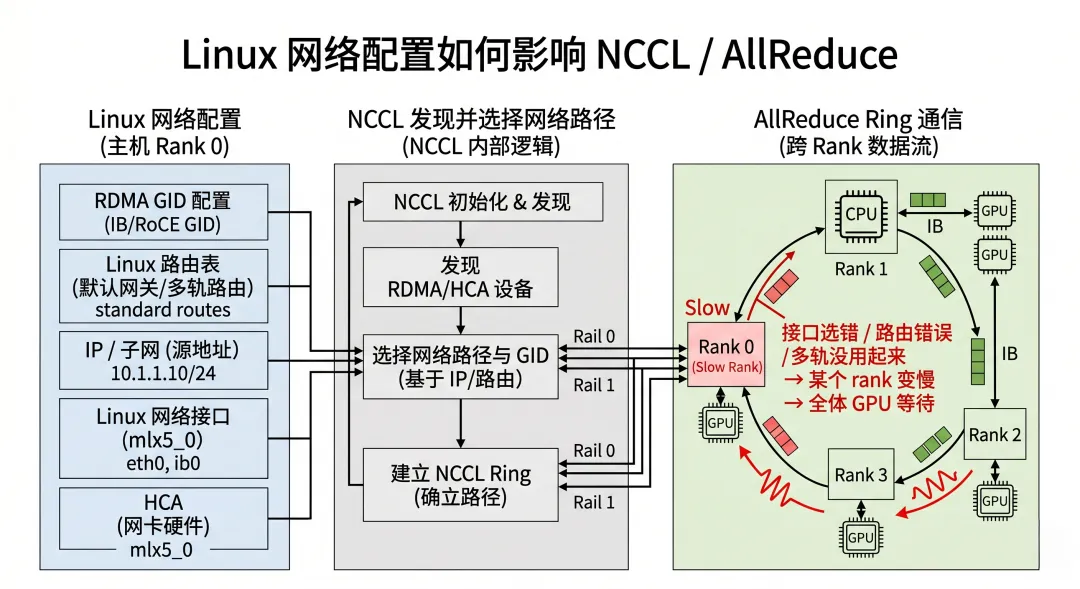
而 NCCL 的路径选择,会受到 Linux 网络环境影响。
1)NCCL 需要先发现接口
它会看到:
哪些网卡接口存在 哪些 IP 地址可用 哪些 HCA 可用 哪些路径可达 哪些接口名匹配环境变量
如果 Linux 网络接口命名混乱、IP 配置不一致、路由不可达,NCCL 的发现结果就会变差。
2)NCCL 多轨需要 Linux 配合
多轨不是 NCCL 单方面就能完成。
它需要:
多个 HCA / NIC 可用 多个 IP / GID 路径正确 Linux 路由不把流量导偏 网卡与 GPU 拓扑合理 交换机多 rail 对应正确
如果 Linux 只给了一个可用路径,NCCL 不可能凭空变出 8 rail。
3)AllReduce 放大也会放大 Linux 配置问题
单流测试里,一个路由错误可能只是某条链路慢一点。
但 AllReduce 里:一个 rank 慢,所有 rank 等。
所以 Linux 网络层的小错误会被放大成:
step time 变长 GPU 等待 MFU 下降 训练吞吐波动
4)用一句话总结
Linux 网络栈的地址、路由、接口、QoS 配置,最终会通过 NCCL 被放大到 AllReduce 的整体性能里。
09
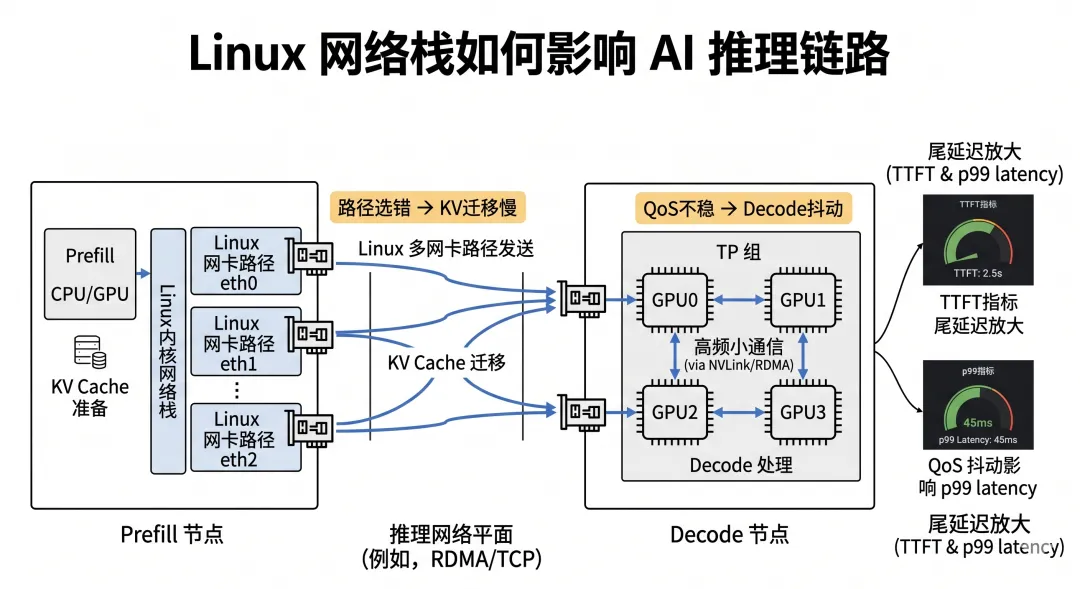
在 AI 推理场景里,Linux 网络栈为什么同样重要?
推理场景看起来不像训练那样重通信。
但在 P/D 分离、KV Cache 迁移、多副本 Decode、TP 推理中,Linux 网络栈仍然很关键。
1)P/D 分离下,KV 迁移依赖路径选择
Prefill 节点生成 KV Cache,Decode 节点继续使用。
如果 Linux 多网卡路由没配好,KV 迁移可能:
走错 NIC 跨错误路径 汇聚到单一接口 造成 TTFT 抖动
这不是单纯“推理引擎”的问题。
它可能是 Linux 网络路径没组织好。
2)Decode TP 通信依赖低时延稳定路径
Decode 阶段每个 token 都要走模型。如果用了 TP,每一步仍然可能有 NCCL / RDMA 通信。
这类通信不一定流量大,但非常怕:
抖动 尾延迟 队列尖峰 路由绕行
Linux 侧接口选择、QoS 打标、路径稳定性都会影响 Decode 的 p99。
3)推理服务的尾延迟会放大网络小问题
推理是用户在线体验。
一个小的网络抖动,可能变成:
首 token 慢 中间 token 停顿 p99 变差 用户感觉卡
所以推理场景下,Linux 网络栈不是“不重要”。
而是更需要稳定。
4)用一句话总结
训练把 Linux 网络问题放大成 step time,推理把 Linux 网络问题放大成 TTFT 和 p99。
10
总结
RDMA 并不是让 Linux 网络栈消失。
它只是把数据搬运从传统内核协议栈路径中拿出来,而地址、路由、QoS、建连、可观测性仍然深度依赖 Linux。
所以,Linux 网络栈在 RDMA 场景下至少扮演六个角色:
- 地址语义提供者
IP、GID、接口状态 - 路径组织者
路由、策略路由、多 rail - 建连辅助者
RDMA CM、源地址选择、路径解析 - QoS 入口控制者
DSCP、ECN、priority / TC 映射 - 系统资源协作者
内存注册、NUMA、CPU 亲和、驱动 - 可观测性入口
接口、路由、统计、错误计数、NCCL 选路证据
所以真不能再简单地说:
RDMA 不走 Linux 网络栈,所以 Linux 网络配置不重要。
更准确的说法应该是:
RDMA 的数据搬运绕过传统协议栈。但 RDMA 的路径选择、QoS、控制面和排障证据,仍然离不开 Linux 网络栈。
很多 RDMA 问题,表面看起来是网卡问题、交换机问题、NCCL 问题。但往下挖,经常会回到 Linux:- IP 配错了- GID 不对- 路由不对- 策略路由没生效- MTU 不一致- DSCP 没打上- ECN 没准备好- NCCL 没看到正确接口- GPU 和 NIC 跨 NUMA所以,真正成熟的 RDMA 排障,不是跳过 Linux。恰恰相反。你要先把 Linux 这层看清楚。因为它虽然不一定在每个数据包上“搬砖”,但它决定了这些数据包:- 从哪里出发- 走哪条路- 带什么标签- 被谁接住- 出问题时你能在哪里看到证据这就是 Linux 网络栈在 RDMA 场景下真正的角色。
👉 AI 训练网络全路径拆解视频课 → 私信:AI网络
👉 AI 推理网络全路径拆解视频课 → 私信:推理
👉 AI 网络架构工程指南手册 → 私信:工程指南
👉 AI 算力网络架构系统视频课(真机实验环境) → 私信:系统
👉 日常工作1对1答疑 → 私信:答疑
如果你也在做 AI 集群架构
欢迎关注「算力网络架构手记」
长期拆解真实算力网络问题
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python实战:一键切换有线/WiFi网络的桌面神器
- 【课程报名截止提醒】Python气象数据分析实战
- PHP 跨平台 UI 抽象与代码生成框架 Perry
- 黑客最爱的配置,为什么你的 PHP 网站总是被挂马?
- 《还在用HDMI线投屏?Python一键局域网无线投屏,太方便了!》
- PHP 面试必问核心知识点,基础 / 框架 / MySQL 一次性讲透
- Python期中考试
- 如何在 AlmaLinux、Rocky Linux、Ubuntu 和 Debian 上修补 CVE-2026-31431(Copy Fail)——完整服务器指南
- 嵌入式 Linux 工程师 AI 实战:让 Claude 直连你的板子
- 【已复现】漏洞通告 | Linux 内核 Fragnesia 权限提升漏洞(CVE-2026-46300)
