虚拟内存深度剖析:页表、TLB 与 Linux 内核机制(卷四)
- 2026-07-02 07:51:46
大页与 TLB 效率
Alloca 改了哈希函数、降低负载因子,接受随机访问不可避免,但 TLB miss 仍太多。2 GB 表若按 4KB 页,约五十万页,没有 TLB 装得下。
Alloca:「2 GB 用 4KB 页要五十万条翻译,TLB 容量有限,我必 miss。除了缩小数据还能怎样?」Kernel:「改页大小。TLB 容量固定,但每条目覆盖的地址范围可变。x86-64 支持 2MB 大页,许多系统还支持 1GB。单条 2MB TLB 项覆盖内存是 4KB 项的 512 倍——2GB 表若用 2MB 大页映射,大约只需 1024 条 TLB 项而非五十万。」
Alloca:「页表层级怎么办?」Kernel:「大页有提前结束 walk 机制。PTE 低位标志里有 PS(页大小):置位表示『到此为止,本项直接指向物理帧,而非子表』。普通 4KB 映射时 PMD 项指向 PTE 子表继续走;若 PMD 项设 PS,则把该项当作 2MB 叶,跳过 PTE 级;虚拟地址低 21 位变成 2MB 大页内偏移。PUD 项设 PS 则映射 1GB,跳过 PMD 与 PTE。」
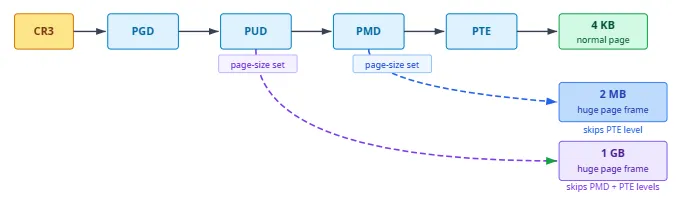
Alloca:「walk 级数少、TLB 项也少,代价?」Kernel:物理连续性。2MB 大页需要 512 个连续的 4KB 物理帧且起始 2MB 对齐。4KB 页可随便捡空闲帧;大页要在碎片化的物理内存里找大块连续空闲,运行越久越难。我可做 compaction 迁移页腾笼,但不保证成功。」Alloca:「新机器易拿大页,长跑后更难?」
Kernel:「通常如此。要稳定:启动前预留池,设
vm.nr_hugepages,在内存尚未严重碎片时 carve 出 HugeTLB 池——总对齐、总连续、随要随给;代价是池内内存在释放前不能当普通页用。」Alloca:「不想长期锁内存呢?」Kernel:透明大页(THP):无专用池也尝试给大页;fault 时直接分配,或后台khugepaged把对齐的 2MB 基础页合并成大页,应用无感升级。」
Alloca:「THP 不保证总有。」Kernel:机会主义;碎片同样限制。可能先 compaction 腾挪以拼出 2MB——延迟尖刺,故低延迟系统有人直接关 THP。数据库缓冲池等要可预期大页覆盖,多在启动显式预留池。」
Key Takeaway
x86-64 基础页 4KB,也支持 2MB(PMD 叶,跳过 PTE 表)与(硬件支持时)1GB(PUD 叶,跳过 PMD 与 PTE)。每条 TLB 覆盖更大范围,miss 时 walk 级数也更少。
关键约束:物理连续。2MB 需 512 个连续且对齐的 4KB 帧;随分配释放碎片化,越来越难满足。
Linux 两条路径:
显式大页( vm.nr_hugepages或启动参数):HugeTLB 池;启动预留最可靠;池大小可调回普通页(受碎片影响)。THP:对普通映射(尤其匿名) opportunistic 给大页;fault 时分配或 khugepaged事后折叠;失败则退回基础页;设置不当可能触发 compaction 抖动。
大页换更少翻译开销,但粒度更粗、可能浪费内存、也更难分配;延迟敏感的大块常驻区多用显式池;可接受抖动的工作负载可试 THP。
多核上的 TLB 击落(TLB shootdown)
Alloca 起很多 worker 线程并行跑,一切顺利,直到她 munmap 掉一大片早先 mmap 的共享区。
Alloca:「大块映射用完了怎么还?」Kernel:
munmap:传起始虚址与长度,我删 VMA、清 PTE,无引用物理页归还。」Alloca:「听起来简单。」
Kernel:「单核如此。你多核并行,每个核有私有 TLB。」Alloca:「不共享一个 TLB?」Kernel:「不。各核 MMU 只查本核 TLB;miss 才 walk,结果缓存在该核 TLB。别核访问同址会各自缓存翻译。」Alloca:「两线程同址各有一条 TLB 项?」
Kernel:「对。每核私有是可扩展性必需;几十核争一个 TLB 会瓶颈。但页表变更就有一致性问题。」Alloca:「什么问题?」Kernel:「你在 core0 上
munmap,我清 PTE;但 core1、2、3… 可能仍缓存该区翻译,而帧我已回收甚至再分配。」Alloca:「会用到陈旧翻译访问错误物理内存。」Kernel:「不允许。munmap完成前必须让所有相关核的 TLB 与页表一致。」Alloca:「怎么做?」
Kernel:发 IPI(处理器间中断) 给可能缓存该地址空间翻译的每个核;它们停下手头工作、执行短例程 flush 相关 TLB 项并回执;我收齐确认才让
munmap返回——这叫 TLB shootdown。」
Aside:什么是处理器间中断(IPI)?
现代 CPU 的 APIC 允许一核向另一核直接发中断即 IPI;与设备中断不同,由一核上软件刻意打断另一核。核收到 IPI 保存现场、进 handler;shootdown handler 刷 TLB、发 ack。内核还用 IPI 做跨核信号、调度抢占、panic 停核等。
Alloca:「每核都要停?」Kernel:「若它可能缓存你地址空间的翻译就要;从未跑过你线程的核可跳过。你等于在等跨核同步。」Alloca:「核越多越慢。」
Kernel:「大体如此。大机上单次大区间
munmap可打断许多核;成本随目标核数与 flush 策略(逐页 vs 大范围 flush)而变。」Alloca:「还有什么时候会这样?」Kernel:「凡是改 PTE 且其他核可能缓存旧翻译:mprotect、回收/迁移时的 unmap、多线程 CoW fault 等。热路径里频繁 invalidation 就付大量跨核协调税。」
Key Takeaway
多核机器每核私有 TLB,可扩展但带来一致性:修改页表时,别核可能仍缓存旧翻译。
munmap 释放 mmap 映射(分配器也可能 brk/munmap 还大块);仅清页表不够——若某核仍缓存指向已释放且可能再分配帧的翻译,会破坏隔离。
TLB shootdown:向可能持有陈旧项的 CPU 发 IPI,各核刷相关 TLB;同步路径须等全部确认。成本随目标核数与 flush 策略增长;多核上大区间 munmap/mprotect 可成瓶颈。
热路径减少页表失效;高性能分配器缓存释放块、批量归还 OS;优先复用大块长寿命映射,避免反复创建/改权/销毁小映射。
NUMA:内存的物理拓扑
_Alloca 尽量用大页、working set 也 fit TLB,并少 munmap。但一半线程明显慢且稳定:0–23 快,24–47 慢。
Alloca:「同样算力、同一块缓冲,为何一半像在等内存?」Kernel:「带你看虚拟地址之下真实机器。」
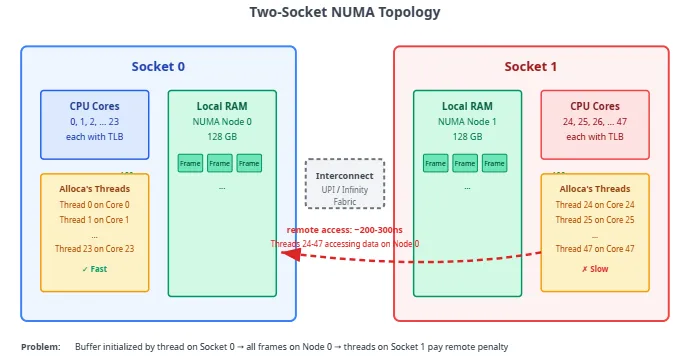
Kernel:「两 socket,各接本地内存。Socket0 读本地 RAM 短路径快。」Alloca:「读另一 socket 的内存?」Kernel:「要走互连,往返常 2–3 倍慢。」
Alloca:「虚拟地址平面一片,我怎知哪在后端哪颗 socket?」Kernel:「你不知道——这正是问题。
0x10000与0x20000对你无差别,背后可能一在 socket0 帧、一在 socket1。」
Alloca:「物理位置决定性能,我却无法控制?」Kernel:「间接可控。首次 touch 页 fault 分配帧时,我要选 NUMA node。」Alloca:「怎么选?」
Kernel:「默认 first-touch:谁触发 fault,帧常分配在该核本地 node。若 core5(在 socket0)先 touch,页就落 socket0 池。」Alloca:「谁先摸页,页就住谁家。」Kernel:「你缓冲多半被主线程在 socket0 顺序初始化,每页 fault 都在 socket0 处理→全落 Node0。再把缓冲交给跨两 socket 的 worker……」Alloca:「0–23 在 socket0 本地读;24–47 在 socket1,cache miss 变 DRAM 访问就要跨互连。」
Alloca:「初始化线程与计算线程要同 socket?」Kernel:「分片数据时,让将做热访问的线程在目标 socket 上 first-touch 自己的分区。」Alloca:「全线程读同一块共享缓冲呢?」Kernel:「更难:放哪都有一半边远程。可用
mbind/set_mempolicy:绑特定 node、设 preferred、或 interleave 让连续页在 node 间交替,分散带宽压力。」Alloca:「为何要 interleave?」
Kernel:「高带宽共享读时,全放一 socket 会打爆该侧内存控制器;交错让两路都承担一部分本地+远程混合流量,用局部性换聚合吞吐。」Alloca:「线程还会被调度迁到另一 socket?」Kernel:「会,精心的放置会白费。NUMA 敏感负载常用
taskset/pthread_setaffinity_np绑核。」
Aside:自动 NUMA 平衡
/proc/sys/kernel/numa_balancing 打开后,内核可采样访问(如暂时 unmap 或标记引发 hinting fault),据此迁移页或任务。无需改代码,但有采样 fault 与迁移开销,且事后反应;延迟一致性要求高的负载仍更信 mbind+绑核。
Key Takeaway
现代多路服务器是 NUMA:物理内存分 node,各挂接一 CPU socket。可访问任意 node,但本地明显快于经互连的远程(常 1.5–3×,依平台)。
虚拟地址空间完全隐藏拓扑:相邻虚拟页可背在不同 node 的帧上。帧所在 node 主要由分配时的内存策略决定。
匿名内存默认近似 first-touch:首次 fault 到物理帧时,通常由处理 fault 的 CPU 的本地 node 分配。初始化与热访问若跨 socket,多数访存付远程延迟。
策略摘要:在将访问数据的 socket 上初始化;绑线程;代码里 mbind/set_mempolicy;命令行 numactl;跨 socket 高带宽共享可读场景试 interleave;可开自动 NUMA 平衡作免手改备选。
多 socket 重共享数据没有完美解:局部性、带宽均衡、有时复制之间要权衡。在已优化 TLB 与 cache 后,NUMA 常仍是多路机上「说不清」内存延迟的主因。
在实践中观察虚拟内存
与 Alloca 的旅程到此结束; 下面罗列可观测与调试工具。机制懂了还要知道出问题时从哪层下手;进程 RSS 异常、明明 fit RAM 却钝、负载下渐慢——症状不同,对应 VM 栈不同层。可按下列顺序剥洋葱。
第一步:进程映射了哪些区间?
先看 /proc/<pid>/maps:每段 VMA 的起止地址、rwx/p|s、文件偏移与路径——堆、栈、共享库、mmap 区一览。
这是预约视图:只说明区间与权限,不说明物理驻留多少;大区可能几乎未 touch。pmap -x <pid> 表格化同一信息。
第二步:实际用了多少物理内存?
smaps 在 maps 基础上按 VMA 给出驻留细分:
Rss:该 VMA 当前在 RAM 的 KB 数;未 touch、已回收的干净文件页、已换出匿名页不计。 Pss:按比例分摊共享页(十进程共享 4KB 库页则各计 0.4KB)。 Private_Clean / Private_Dirty;Shared_Clean / Shared_Dirty(脏共享文件页要 writeback;脏 shmem/tmpfs 常走 swap)。 AnonHugePages:该 VMA 由 THP 支撑的字节数。
系统级看 /proc/meminfo:MemAvailable、Cached、Dirty/Writeback、AnonPages、SwapTotal/SwapFree 等。
第三步:是否在通过缺页打盘?
次缺页(getrusage 的 ru_minflt)无盘 I/O,启动期大量次缺页正常。
主缺页(ru_majflt 或 perf stat 的 major-faults)含真实存储 I/O:冷文件页或从 swap 读回。机械盘单次主缺页可毫秒级,NVMe 也常数百微秒;稳态热路径上持续主缺页多意味 swap 压力、未缓存 mmap/文件 I/O、或 working set 与系统争用 RAM/页缓存。
测量示例:
perf stat -e page-faults,major-faults ./your-program总 fault 与 major 之差近似次缺页。
第四步:整机是否在内存压力下?
vmstat 1:看 si/so(swap 换入换出 KiB/s);so 非零说明在写匿名页到 swap;si 非零在读回;二者同时持续高是典型抖动。b 为等 I/O 阻塞任务数。
PSI:/proc/pressure/memory 的 some/full 表示因内存等待停滞的时间比例;full 持续爬升表示内存已成硬瓶颈。
第五步:翻译本身是否瓶颈?
TLB miss 大多对内核不可见(MMU 硬件 walk);要看 perf 硬件计数器,例如:
perf stat -e dTLB-load-misses,dTLB-store-misses,iTLB-load-misses ./your-program事件名随 CPU 而变(perf list | grep -i tlb)。高 miss 要结合 walk 周期(如 Intel dtlb_load_misses.walk_active)判断是否昂贵 walk。高 TLB miss + 低主缺页(数据在 RAM 但翻译未缓存)→ working set 超出 TLB 层次容量→大页或更紧数据打包。
第六步:同工作量下是否部分线程稳定更慢?
稳定不对称→先查 NUMA:numactl --hardware 看拓扑与距离矩阵;numastat -p <pid> 看页落在哪些 node;/proc/<pid>/numa_maps 按 VMA 细查策略与分布。
综合排查顺序
真用内存还是只预约? maps区间 vssmapsRss。RSS 里多少是「自己的」? 比 Rss 与 Pss。 热路径主缺页? perf/getrusage。系统回收/换入换出? vmstat、PSI。RAM 足但翻译贵? TLB/walk 计数器。 同 work 线程速度不一? numastat、numa_maps,并排除温控、IRQ、锁竞争等。
我们学到了什么
通过内核与进程 Alloca 的对话,串起了虚拟内存的主要机制:地址空间、页表、TLB、按需分页、内存类型、页回收、写时复制、mmap、大页、TLB shootdown、NUMA、可观测性等。 要点如下:
提供内存级隔离是虚拟内存要解决的根本问题。每进程一套私有虚拟地址,MMU 强制执行边界,进程不能直接读写他进程内存。
给地址空间以结构:划分为 text、data、heap、stack 等段,权限与增长行为各异;代码只读可执行;栈向下按需增长;堆随分配器向上(或 mmap)扩展。
逐字节映射到物理位置不现实:扁平表覆盖 128 TiB 用户半空间会达数百 GiB 级元数据开销。解法是固定 页/帧 + 多级稀疏页表:4KB 粒度,任意帧可背任意页,只为实际使用区间分配各级表项。
若每次访存都四级 walk 会太慢。TLB 缓存近期虚拟→物理翻译,多数访问不再 walk;命中率取决于访问模式与 working set 相对 TLB 容量。
在 malloc 时立刻分配物理帧浪费内存。按需分页把承诺记在 VMA,首次访问才 fault 分配帧。
并非所有页逐出成本相同。内核区分匿名(堆、栈、MAP_ANONYMOUS)、文件后备(可执行、共享库、mmap 文件)与 tmpfs 等。干净文件页可立刻丢弃再从文件装入;脏文件页须先回写;匿名与 tmpfs 脏页常需 swap 才有处可回。
物理内存会满。页回收在压力下释放帧;用硬件 accessed 位估计冷热而无需每次访存 trap;rmap 从帧反查 PTE;active/inactive LRU(及 MGLRU)识别冷页。目标是逐冷保热;若逐出很快又需要的页则抖动。
fork 时拷贝全部地址空间太慢。写时复制让父子先共享物理帧,引用计数跟踪,真正写入时才拷贝单页,使 fork 近乎与地址空间大小无关地快。
经用户缓冲的文件 I/O 多一次拷贝。mmap 把页缓存帧直接映进进程地址空间,读文件不必再从内核缓冲拷到用户缓冲;多进程映射同一文件可共享同一物理帧。
随机访问模式会打散到过多页。顺序扫描在少量页上复用 TLB 项并受益于硬件预取;哈希探测、指针追逐等随机模式无同样保证,性能可能难以预测。
大 working set 会撑爆 TLB。大页(x86-64 上 2MB/1GB)让单条 TLB 覆盖远大于 4KB 的范围;约束是需要对齐的大块连续物理内存,随运行碎片化越来越难获得。
多核上 unmap 需要跨核协作。每核私有 TLB;内核删/改映射时,他核可能仍缓存旧翻译。TLB shootdown 用 IPI 迫使相关核 flush,操作才能安全完成——故多核上大区间 munmap/mprotect 可能很贵。
虚拟内存隐藏了内存的物理拓扑。多路 NUMA 上,跨 socket 访问远程 DRAM 常比本地慢 1.5–3×;虚拟地址对二者一视同仁。正确放置需要线程与数据共址、first-touch 初始化、绑核或显式 mbind 等策略。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【Python 教程】XGBoost + SHAP 一套代码讲清“模型为什么这么判”
- Python量化入门:一行代码回测10年数据
- Python100个必学习函数,吃透直接封神!
- 中南大学的大佬终于把Python做成了编程游戏
- python之selenium (1)
- Python写了一个PDF元数据清除工具,发出去的文件不想被人看出底细【元数据清除01】
- 还不会Python,这份指南帮你从零搭好环境
- 在人工智能深度伪造冒充攻击活动后,对 Python 后门威胁进行了分析
- 服务器异常实时感知:Python 监控日志 + 钉钉机器人告警实战
- 按着这个方法学python,一个月轻松学会!
