Python写了一个PDF元数据清除工具,发出去的文件不想被人看出底细【元数据清除01】
- 2026-07-01 12:41:47
工作中经常要把PDF文件发给别人,内部报告、方案文档、标书……发之前都会检查一遍内容,但很少注意到元数据这件事。
有一次发出去之后,别人问:"这文档是你们谁写的?电脑名怎么还带着呢?"
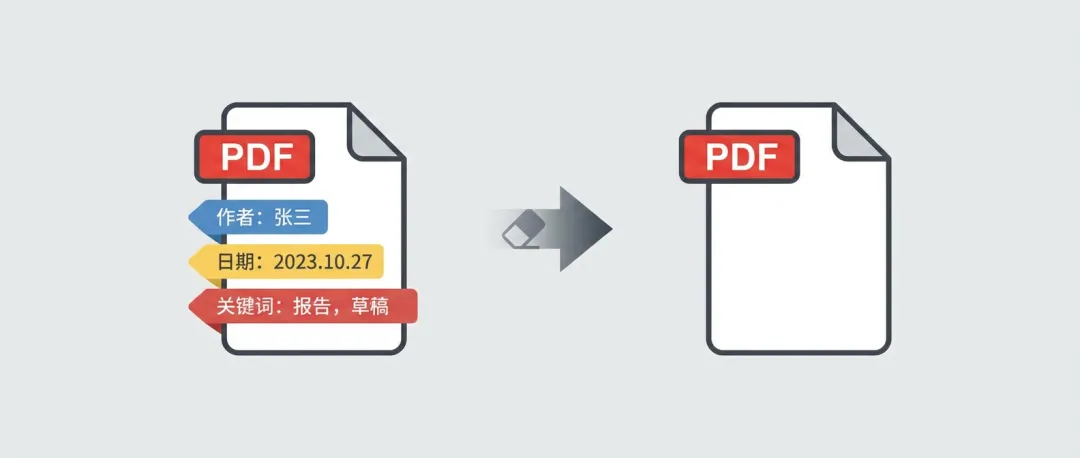
当时愣了一下,打开PDF属性一看,作者一栏写的是我电脑的登录名,创建时间精确到秒,制作工具显示的是我装的Adobe版本——这些信息PDF转换工具根本不会处理,自己也从来没想过要清掉。
利用周末,用Python写了这个PDF元数据清除工具,只依赖pikepdf,不到300行代码,导入就能用。
PDF元数据到底包含什么
很多人不知道,PDF文件不只是内容,还有一堆隐藏的"身份信息":
- /Author
:作者姓名 - /Creator
:创建工具,比如"Microsoft Word"或者"Adobe Acrobat" - /Producer
:制作工具,PDF生成软件信息 - /CreationDate
:创建时间,精确到秒 - /ModDate
:最后修改时间 - /Title / Subject / Keywords
:标题、主题、关键字
这些字段在PDF标准里叫DocInfo,大部分PDF阅读器右键"属性"里都能看到。有些商业场景下,这些信息暴露出去会带来麻烦——内部文档被看出是谁创建的,或者通过创建时间推断出工作流程。
一个免费的PDF软件应该把这个功能做进去,而不是让用户去找专门的工具。
为什么选pikepdf而不是其他库
Python处理PDF的库有好几个,最终选了pikepdf,有三个原因:
不改内容只改元数据。有些库在处理过程中会改变PDF的渲染效果,pikepdf是底层操作,只动元数据不动内容,文件不会"变样"。
对中文兼容好。pikepdf内部用UTF-8处理字符串,中文文档不会出现乱码。
API设计清晰。读元数据用open_metadata(),写用with块自动保存,逻辑很干净。
pip安装一行搞定:
pip install pikepdf元数据分两层:XMP和DocInfo
这是踩完坑才明白的一件事。
PDF的元数据存在两个地方:XMP(XML元数据)和DocInfo(文档信息字典)。大部分PDF两个地方都有,而且pikepdf的save()方法在保存时会重新写入DocInfo——所以单清一次不够,要清两次。
第一次在with块里清XMP,同时清DocInfo;第二次重新打开文件再清一遍XMP残留和pikepdf自动写入的字段:
# 第一次:清XMP + 清DocInfowith pdf.open_metadata() as xmp:for k in list(xmp.keys()):del xmp[k]if pdf.docinfo:for key in list(pdf.docinfo.keys()):del pdf.docinfo[key]pdf.save(_save, compress_streams=True)# 第二次:清残留_p2 = pikepdf.open(_save, allow_overwriting_input=True)with _p2.open_metadata() as _x2:for _k in list(_x2.keys()):del _x2[_k]_p2.save(_save, compress_streams=True)这个两次清理的逻辑是踩了"第一次没清干净"的坑才写出来的,后来发现pikepdf的官方文档里也提到了这个问题。
指定保留某些字段
有时候不需要全清——比如标题想留着,其他的全清掉。
preserve_keys参数解决了这个需求:
result = tool.remove_metadata("报告.pdf","报告_干净版.pdf", preserve_keys=["/Title"] # 只保留标题)内部会保留DocInfo里指定的key,只删其他的。对于需要保留文档标题的业务场景,这个功能很实用。
批量处理:normalize_path处理拖放路径
批量处理时有个容易忽略的问题:Windows上拖放文件到命令行,路径会带引号,有时候路径分隔符也会变。
normalize_path静态方法统一处理这种情况:
normalized = PDFRemoveMetadata.normalize_path(raw_path)# 去掉首尾空白和引号# Windows反斜杠转成正斜杠再转回正确路径这个方法是给自己用的,写完库之后顺手加的,后来发现处理同事发过来的路径时确实省了不少麻烦。
完整代码结构
整个Python项目的结构很清晰:
classPDFRemoveMetadata:defget_metadata(path)# 读取全部元数据defprint_metadata(path)# 打印可读摘要defremove_metadata(...)# 清除元数据defbatch_remove(...)# 批量处理 @staticmethod normalize_path(raw) # 路径规范化METADATA_KEYS_ZH = { # 中文对照表"/Author": "作者","/CreationDate": "创建日期", ...}不到300行代码,导入方式:
from pdf_remove_metadata import PDFRemoveMetadatatool = PDFRemoveMetadata(verbose=True)tool.print_metadata("文件.pdf")success, out = tool.remove_metadata("文件.pdf")这个Python小项目也是pyqt5教程的一部分——Python从入门到实践,最好的方式就是动手解决一个真实的痛点。元数据清除这件事不大,但做完了对PDF标准的理解也更深了一层。
下篇说说怎么把这个库做成一个完整的免费PDF软件界面,拖入文件、选设置、点清除,一气呵成。
📌 今日话题
你发PDF给别人之前,会检查元数据吗?
是从来不管,还是会专门清理一遍?
A.从来不管,不知道还有这回事
B.偶尔想起来会看一下
C.每次都会清理
D.用什么工具清理的?
评论区说说👇
往期小工具
本地离线翻译工具来了!我用Python写了个离线翻译工具,断网也能翻28国语言
Python 多格式文件转 PDF:从三引擎库到 PyQt5 桌面工具开发全记录【02】
PyQt5实战:把PDF转换库做成普通人都能用的桌面应用【02】
喜欢小居的文章,点赞、关注、转发,点个“在看”不迷路~
有问题找小居,小居看到马上回!
工具获取:公众号回复「元数据删除」即可
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- ICode Python 五级训练场 综合练习(7)
- 【本周开课】最新Python机器学习、深度学习核心技术
- Python 3个宝藏项目,新手也能上手!(附解析)
- Python集成飞书webhook配置
- Python & MATLAB 到多先验物理增强神经网络实现光镊微粒沿任意轨迹运动
- Python+OSM迅速获取全球矢量要素
- Skills之Scrapling:Python网络爬虫框架,支持反机器人绕过、JS渲染和Cloudflare保护网站抓取 GitHub Stars 13.9万+
- 启航指南——Linux安装软件的方式有哪些
- 别让Python独美:这6款Java AI Agent神器,正在撕开企业级AI的大门
- Linux 性能调优工具的 9 张图
