Linux内核立下AI写代码的铁规:CS的同学们,千万别被大模型废掉基本功
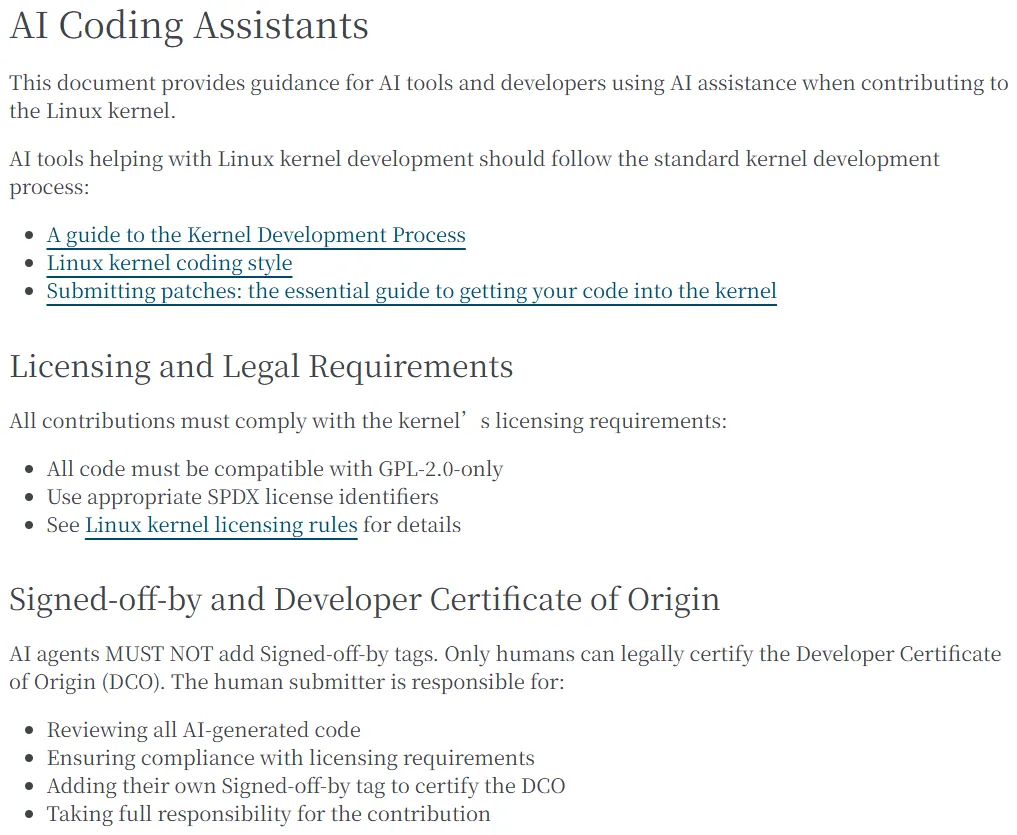
在2026年的当下,属于大语言模型(LLM)的时代正加速到来。只要敲几行自然语言提示词,Claude Code 或 Codex 就能在几秒钟内生成上百行看似优雅的代码。对于还在辛苦学习数据结构、操作系统和编译原理的计算机科学(CS)专业学生来说,这无疑是一个巨大的诱惑:既然AI写代码这么快,我们还有必要苦练编程基本功吗?如果你也有过这样的动摇,那么2026年4月发生在全球最大、最重要的开源社会基础设施——Linux内核社区的真实探讨,或许能给你带来一些启发。面对汹涌而来的AI代码,Linux之父林纳斯·托瓦兹(Linus Torvalds)和内核维护者们做出了决断,正式为AI参与编程立下了规矩。这场关乎责任、代码质量与工程直觉的争论告一段落,它提示每一位CS专业的学生:AI只是工具,如果你没有扎实的基本功去把关代码质量,就很容易被AI产出的低质量代码所拖累。在过去的几个月里,Linux内核社区经历了一场关于“是否该严格限制AI代码”的探讨。开源世界长期依赖一套被称为DCO(开发者来源证书)的机制,要求开发者在提交代码时用 Signed-off-by 标签承诺代码来源的合法性。但是,大模型的训练数据中包含着海量版权不明或受限制的代码,如果开发者直接复制AI生成的代码,很可能引发许可违规风险。面对这种情况,Linux社区并没有选择一刀切地封杀AI,而是回归到了传统的工程原则:责任到人。在最新发布的Linux内核AI代码使用规范中(点击“原文链接”查看),官方给出了明确的原话指导:“贡献者必须亲自添加他们自己的 Signed-off-by,并因此承担DCO的义务”,并且强调AI工具绝不能添加 Signed-off-by 行。相反,系统引入了一个新的标签 Assisted-by 来标明AI的参与。内核文档传达了一个核心精神:你可以使用AI,但你不能把机器伪装成作者。当你按下提交键的那一刻,你必须对这些代码承担全部责任。这就意味着,你必须像自己亲手敲出这些代码一样,完全理解它到底在做什么、为什么它是正确的、以及它在哪些边缘情况下可能会出错。在Linux这样支撑着全球服务器、手机和云计算的底层基础设施中,责任是无法外包给AI的。为什么Linux社区的顶级工程师们对大模型如此警惕?因为在涉及底层系统的关键任务中,AI生成的内容往往伴随着风险。随着AI编程工具的普及,内核维护者们的收件箱里出现了不少被社区戏称为“AI泔水(AI slop)”的低质量代码。这些代码不仅包含错误,有时还伴随着由AI生成的虚假漏洞报告,迫使一些开源项目不得不关闭漏洞悬赏机制。此前,一位名叫萨莎·莱文(Sasha Levin)的NVIDIA工程师兼内核维护者,曾遇到过一份完全由大模型生成且未做任何AI标记的补丁;尽管这份代码能跑通,但却引入了性能衰退问题,并在审查阶段误导了其他维护者。林纳斯指出,AI在编程时的一个主要问题在于它缺乏关键的上下文。内核工程需要深厚的领域知识,你必须理解硬件约束、CPU调度、驱动程序、内存模型以及系统交互。而AI并不真正理解这些,它更多是在预测文本。正因如此,AI常常会做出非常自信但却错误的假设——它们会捏造函数、调用不存在的API、误解内核的真实行为,甚至提出无法扩展的解决方案。在内核世界里,这些“自信的错误”会导致系统崩溃或引入安全漏洞。不可否认,AI在某些辅助场景下确实有用。例如, Linux 内核开发的“二号人物”格雷格·克罗阿-哈特曼(Greg Kroah-Hartman)最近就在测试一个名为“Clanker T1000”的AI辅助模糊测试工具,让AI成为了寻找内核漏洞的好帮手。但找Bug是一回事,让AI写底层生产代码则是另一回事。林纳斯本人表示,他对让计算机执行某些操作的“氛围编程(Vibe coding)”持开放态度,但如果是用于生产环境的内核开发,那将是难以维护的。在开发者的论坛上,关于如何应对低质量AI代码的讨论引发了共鸣。有人道破了AI辅助编程的一个悖论:要有效过滤掉糟糕的AI代码,唯一的办法就是让经验丰富的程序员来审查,因为只有他们才能分辨出好代码与坏代码。很多初学者容易产生一种错觉,认为只要有了LLM,自己即使不懂底层逻辑也能成为全栈工程师。但现实是,AI生成的代码往往看起来很完美,但实际上可能漏洞百出。对于那些没有扎实基本功的人来说,审核AI生成的代码比自己从头写还要困难。如果你自己都不懂并发竞争、内存屏障或RCU锁的底层原理,又该如何去审查一段涉及这些概念的复杂代码?内核安全专家们建议,开发者应当把AI的输出当作一个不值得完全信任的草稿来对待。你必须阅读它、质疑它,并假设它遗漏了边缘情况、写错了错误处理路径。特别是对于那些看似简单的辅助函数,往往隐藏着细微的锁机制错误或内存生命周期问题。如果你无法向资深工程师解释清楚这段代码的每一行原理,就不应该提交它。对于正在求学路上的CS专业学生来说,关于AI使用的核心建议是:过度依赖AI的开发者,可能会削弱自己的核心专业能力。如果新一代的开发者遇到任何问题都习惯性地向AI索要答案,他们将很难培养出真正的解决问题能力,也会逐渐生疏于调试系统、设计复杂架构以及编写优化代码的硬核技能。AI的捷径或许能让你在今天的作业中迅速拿到结果,但它可能会削弱你明天的专业壁垒。真正的软件工程不仅仅是让代码能够编译通过,它依赖于多年踩坑、调试和阅读优秀源码所积累的直觉与经验。AI目前尚缺乏这种基于现实反馈的工程直觉。因此,请依然保持对技术的敬畏,去认真手写数据结构,去耐心调试那些隐秘的内存泄漏。拥抱AI这个强大的工具,但一定要在建立起扎实的编程基本功之后。大模型带来的巨大生产力诱惑,使得诸多高校为了迎合业界需求,逐渐淡化了底层系统知识的教学比重。这种趋势造就了庞大的“黑盒一代”:他们能凭借直觉调用世界上最复杂的系统或一键部署云服务,却在系统失控时束手无策,甚至完全不理解背后的数学原理与工程代价。Stack Overflow的联合创始人乔尔·斯波尔斯基(Joel Spolsky)曾提出“抽象泄漏法则”(The Law of Leaky Abstractions),指出所有重要的抽象在某种程度上都是泄漏的。这意味着,无论底层细节被封装得多么完美,那些隐藏的复杂性总会在异常情况下喷涌而出。当常规的高层抽象失效、系统遭遇底层内存泄漏或极高并发下的性能瓶颈时,高度封装的AI工具将无能为力。面对这种不可逆的黑盒化趋势,现代计算机教育的真正挑战在于精准识别出那些“抽象必然会泄漏”的节点,并在课程和实验中这些节点上强行打开黑盒,人为地制造故障或构造受控的低层级场景,让学生通过“再发明轮子”来真正理解底层的原理和极限。压缩黑盒以获取生产力,打开黑盒以守住工程底线,从来不是非此即彼的选择。坚持要求学生掌握这些被视为透明的隐形基础设施,确保他们未来在关键时刻能够唤醒对底层的认知,从而打造计算机科班生最核心的专业壁垒与不可替代性。呼吁每一位CS同行:在将AI引入自己的课程教学内容的时候,请务必谨慎、再谨慎!

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
