大家好,我是木木。
今天给大家分享一个持久的 Python 库,mem0。
mem0
AI Agent 用一次很好玩,但真正进入工作流后,用户往往希望它“记得我”:记得偏好、历史、上下文、长期目标和之前踩过的坑。mem0 做的就是这层记忆能力。
它不是简单把聊天记录拼回 Prompt,而是把记忆抽取、存储、检索和用户维度组织起来。对于连续使用的 Agent,这个概念非常好讲,也很容易落到真实产品里。
项目地址:https://github.com/mem0ai/mem0
官方文档:https://docs.mem0.ai
三大特点
长期记忆
可以围绕用户、会话、Agent 或应用保存长期上下文,让智能体不必每次从零开始。
检索可用
记忆通常会进入向量检索或混合检索流程,按当前任务召回相关片段,而不是把所有历史都塞进上下文。
产品友好
用户偏好、行为历史、业务状态和个性化配置都可以作为记忆层的一部分,适合做连续体验。
最佳实践
安装方式:python -m pip install mem0ai==2.0.2
下面的 Demo 不连接 Mem0 云服务,也不调用外部 LLM。它用配置类和 Mock Embedding 展示记忆层的核心结构。
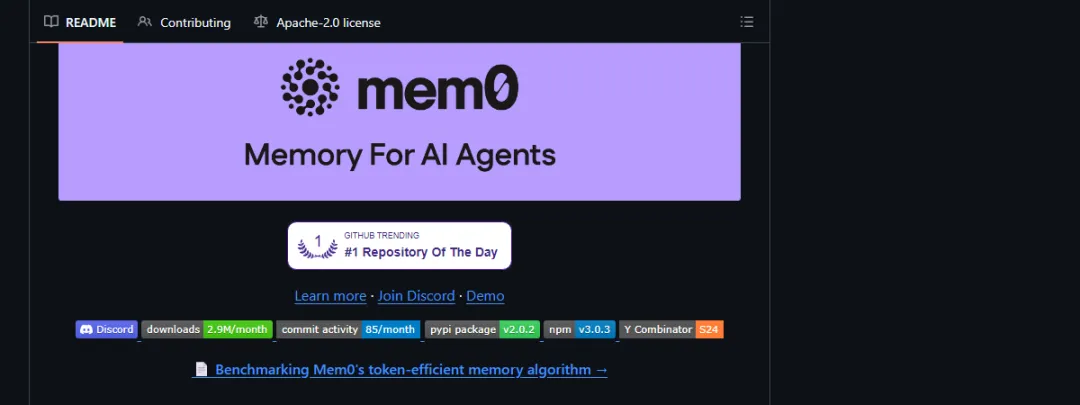
功能一:定义记忆层配置
这段代码解决什么问题:先把向量库、embedding、LLM 和历史数据库位置描述清楚。真实项目里,这些配置应该放在本地配置文件或密钥系统里,不要硬塞进 Prompt。
importwarningswarnings.filterwarnings('ignore')frommem0.configs.baseimportMemoryConfigfrommem0.vector_stores.configsimportVectorStoreConfigfrommem0.embeddings.configsimportEmbedderConfigfrommem0.llms.configsimportLlmConfigconfig=MemoryConfig(vector_store=VectorStoreConfig(provider='qdrant',config={'collection_name':'agent_memory','embedding_model_dims':1536}),embedder=EmbedderConfig(provider='openai',config={'model':'text-embedding-3-small'}),llm=LlmConfig(provider='openai',config={'model':'gpt-4o-mini'}),history_db_path='data/mem0-history.db',)print('vector store:',config.vector_store.provider)print('embedder:',config.embedder.provider)print('llm provider:',config.llm.provider)print('history db:',config.history_db_path)
记忆层最怕“先跑起来再说”。上线前要先想清楚哪些内容能记、记多久、谁能读、用户如何删除,以及哪些内容绝对不能进入记忆。
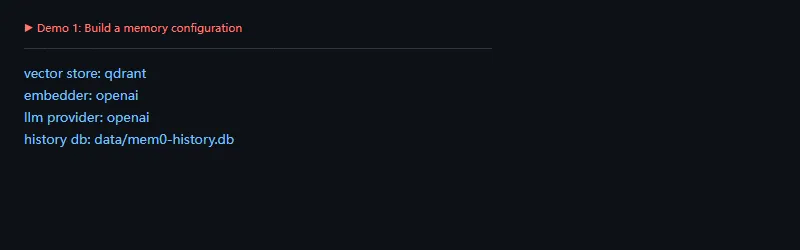
功能二:把记忆文本转成向量
这段代码解决什么问题:记忆要被检索,通常需要先变成向量。这里用 Mock Embedding 演示形状,不访问任何外部 API。
importwarningswarnings.filterwarnings('ignore')frommem0.embeddings.mockimportMockEmbeddingsembedder=MockEmbeddings()texts=['用户喜欢简洁的文章开头','用户正在写 Python 库日更']fortextintexts:vector=embedder.embed(text)print(text[:12],'-> dim',len(vector),'head',vector[:3])print('embedder:',type(embedder).__name__)print('no external api:',True)
真实使用时,embedding 模型会影响记忆召回效果。中文场景尤其要测试相似表达、同义词、简称和跨轮对话里的召回质量。
环境与版本信息
- Demo 环境:Windows 11,Python 3.11
- 当前包要求 Python:
>=3.10,<4.0 - 关键依赖版本:
qdrant-client 1.17.1、openai 2.35.1 - 官方定位:Long-term memory for AI Agents
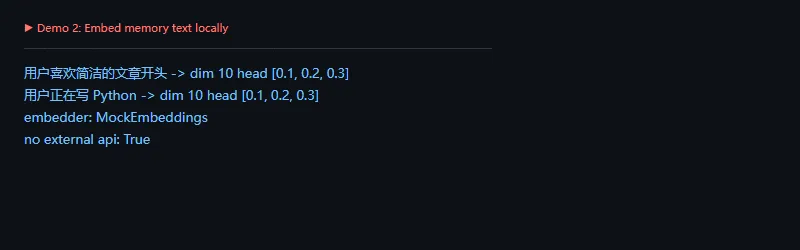
高级功能
这段代码解决什么问题:记忆不能只按“相似”召回,还要有用户、应用、租户、权限等过滤条件。否则很容易把别人的记忆或不相关业务上下文带进回答。
importwarningswarnings.filterwarnings('ignore')memories=[{'user_id':'u-1','app':'writer','text':'喜欢文章开头不要太长','score':0.92},{'user_id':'u-1','app':'agent','text':'需要记录工具调用权限','score':0.81},{'user_id':'u-2','app':'writer','text':'偏好英文标题','score':0.77},]query_user='u-1'query_app='writer'matched=[mforminmemoriesifm['user_id']==query_userandm['app']==query_app]matched.sort(key=lambdaitem:item['score'],reverse=True)print('matched:',len(matched))foriteminmatched:print(item['user_id'],item['app'],item['score'],item['text'])print('memory keys:',', '.join(memories[0].keys()))
记忆层是强能力,也有强风险。越是个性化,越要重视权限、删除、审计和用户可见性。
适用场景
- 你在做长期使用的 Agent,希望它记住用户偏好和历史上下文
- 你想把聊天记录、偏好、事实和业务状态整理成可检索的长期记忆
不适用场景
上线检查
- 提供记忆查看、删除、过期和审计机制,避免黑盒记忆。
总结
mem0 适合给 AI Agent 补长期记忆层。它让智能体从“一次性聊天”走向“连续协作”,但也要求我们认真设计权限、隐私和召回边界。记得住很重要,记得安全更重要。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
