开头
很多模型项目都停在同一个阶段:
这篇教程只做一件事:把 XGBoost 的预测能力和 SHAP 的可解释能力放在同一个流程里,既给你结果,也给你机制。
一、这篇教程要解决什么问题?
我们不只关心“预测准不准”,还关心:
对应的方法结构:
- • SHAP:负责全局解释 + 个体解释 + 方向解释。
二、完整流程
- 7. SHAP 重要性条形图(mean |SHAP|)
三、关键代码
model = XGBClassifier( n_estimators=700, max_depth=4, learning_rate=0.04, subsample=0.85, colsample_bytree=0.85, reg_alpha=0.2, reg_lambda=1.0, objective="binary:logistic", eval_metric="auc", random_state=42, n_jobs=1,)model.fit(X_train, y_train, eval_set=[(X_test, y_test)], verbose=False)explainer = shap.TreeExplainer(model)shap_values = explainer.shap_values(X_test)
四、实跑结果
说明:这是教程演示数据上的真实运行结果,目的是展示方法链路与解释逻辑。用于论文/业务时应替换为你的真实样本。
五、运行结果图
图1:模型性能(ROC)
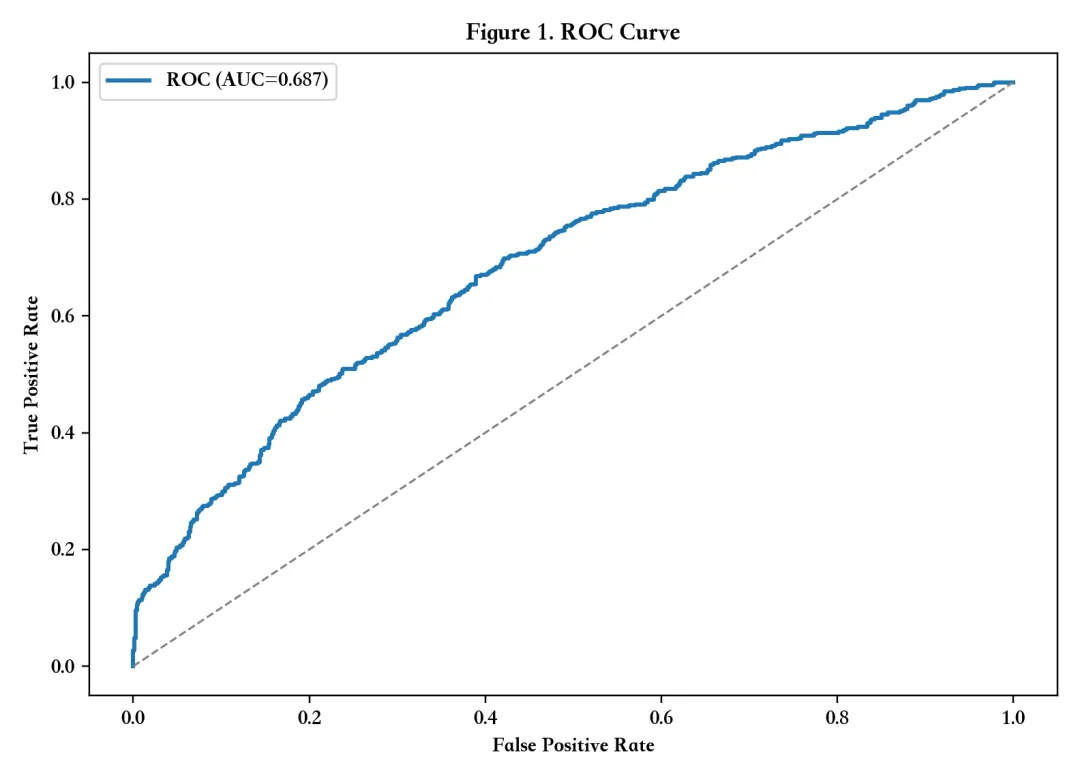
解读:先确认模型有基本预测能力,再进入解释阶段。
图2:SHAP 全局解释(Summary Plot)
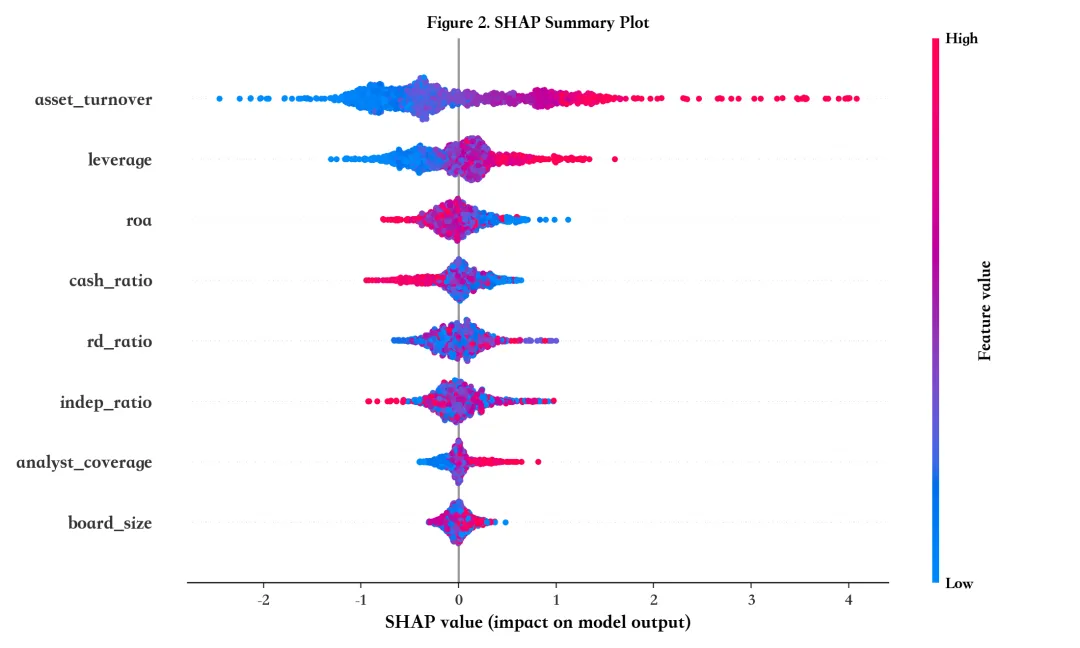
解读:一张图同时告诉你“谁最重要”和“高低取值如何推动预测变化”。
图3:SHAP 依赖图(Dependence Plot)
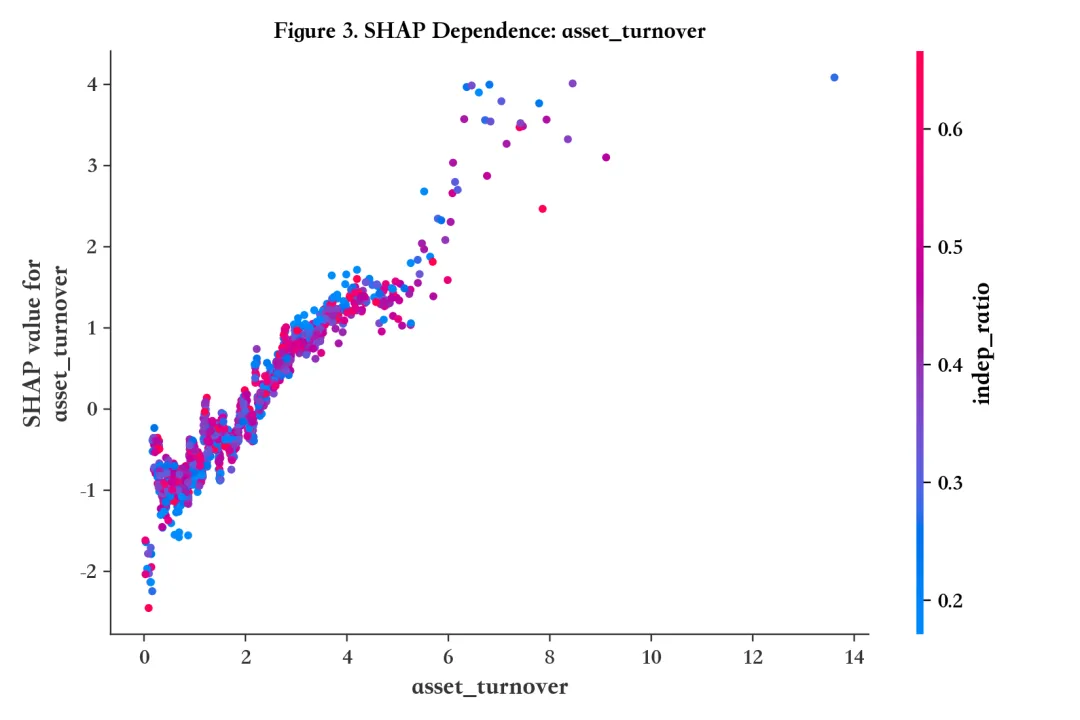
解读:看单变量的非线性影响与交互迹象,避免“线性想象”。
图4:特征贡献度排名
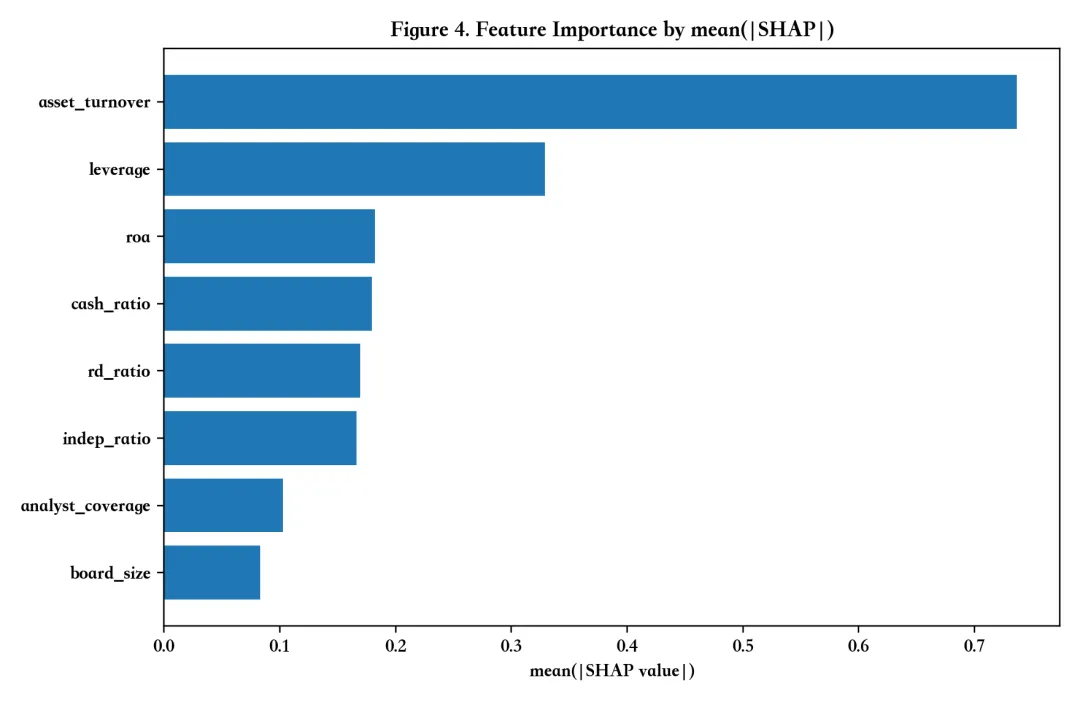
解读:给管理层或读者最友好的“贡献度排序”视图。
六、这套方法为什么有价值?
- 1. 它把“准确率”和“可解释性”放在同一个闭环。
- 3. 它能直接服务业务沟通:为什么判高风险、风险来自哪里。
七、常见误区
八、学术边界
XGBoost + SHAP 回答的是“预测与解释”问题,不是自动因果识别。如果你的问题是因果推断,需要结合 DID / DML / IV 等识别策略。
结语
真正高级的建模,不是把模型做黑,而是把黑箱打开。当你能同时交付“预测性能 + 解释证据”,模型才真正进入可发表、可汇报、可决策的阶段。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
