从 10 分钟到 10 秒:利用 Linux Page Cache 预热实现模型加载 60 倍加速
- 2026-06-24 10:59:44
一、 痛点分析:被忽视的磁盘 I/O 瓶颈
大家好,最近在帮客户部署MiniMax-M2.5等大模型时,我们往往关注显存(VRAM)和算力(TFLOPS),却忽略了磁盘 I/O。发现第一次启动因为系统没有缓存,导致加载模型非常慢,系统无缓存,必须从磁盘读取数十 GB 的模型文件。 当模型异常需重启或容器迁移时,Page Cache 被清理,模型重新从磁盘加载到显存的过程极其缓慢,导致长达数分钟的服务不可用。
于是就想每次模型要重启前,都先预热下,把模型先放到Page Cache,这样每次模型加载都会查看Page Cache是否存在,不存在再去磁盘加载到显存,存在就直接内存到显存,先看结论,直接快了60倍。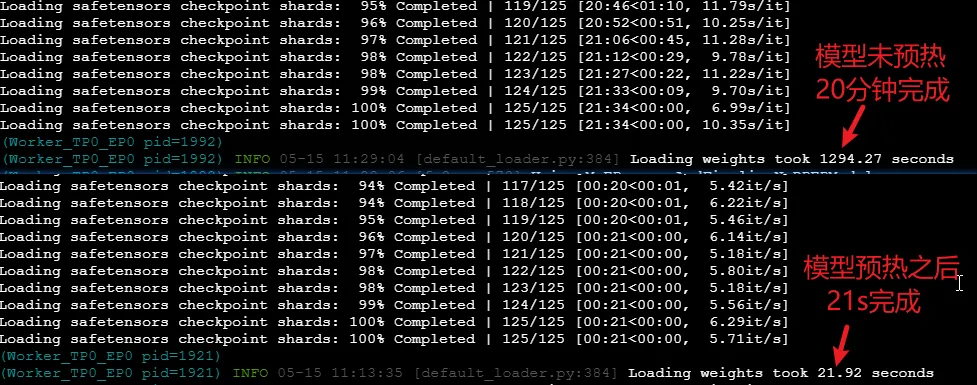 二、 核心原理:Page Cache 的“跳板”作用
二、 核心原理:Page Cache 的“跳板”作用
Linux 内核通过 Page Cache(页缓存) 来优化磁盘读写。我们的优化思路是:在模型正式加载前,手动干预内核,将模型权重文件提前“拽”入内存。
常规路径(冷启动): 磁盘 -> CPU 内存(Page Cache)-> GPU 显存(VRAM)。此时受限于磁盘随机读写速度。
优化路径(热加载): Page Cache(已存在)-> GPU 显存(VRAM)。此时受限于内存带宽,速度提升量级巨大。
三、 优化方案:手动预热(Pre-warming)
在启动模型之前增加预热逻辑,确保在推理框架(如 vLLM 或 TGI)调用模型文件前,文件已驻留内存。
apt install parallelfind MiniMax-M2.5 -name "*.safetensors" | parallel -j 8 --bar --tag 'cat {} > /dev/null'四、 性能对比数据
经过实测,预热机制对 MiniMax-M2.5 的启动速度提升如下:
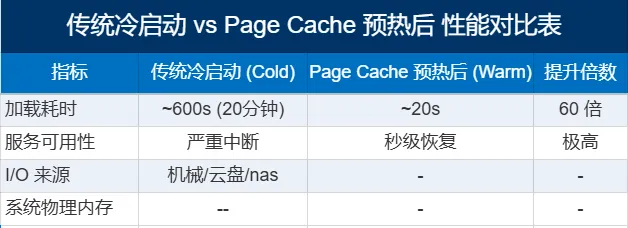
五、 专家提示(Deep Dive)
内存容量校验: 确保你的宿主机物理内存(RAM)大于模型权重文件的大小,否则 Page Cache 会发生置换(Eviction),预热效果打折扣。
搭配 mmap 使用: 大多数推理框架(如 PyTorch/SafeTensors)默认使用
mmap加载模型,这与 Page Cache 机制完美契合。持久化策略: 在 K8s 环境下,可以将预热逻辑放在
initContainers中,确保主容器启动时,底层宿主机的 Page Cache 已经就绪。
六、 推理命令
vllm serve \ MiniMax-M2.5 --trust-remote-code --gpu-memory-utilization 0.92 \ --enable_expert_parallel --tensor-parallel-size 8 \ --enable-auto-tool-choice --tool-call-parser minimax_m2 \ --reasoning-parser minimax_m2_append_think --trust-remote-code七、8卡H系列80G性能报告
vllm bench serve \--model MiniMax-M2.5 --served-model-name \ MiniMax-M2.5 --host localhost --port 8000 \--dataset-name random \--random-input-len 10240 --random-output-len 256 \--num-prompts 320 --max-concurrency 80 --trust-remote-code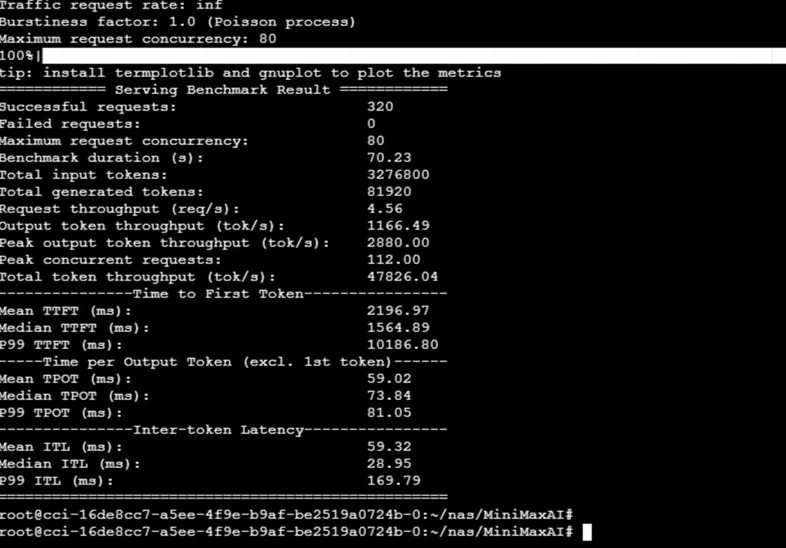
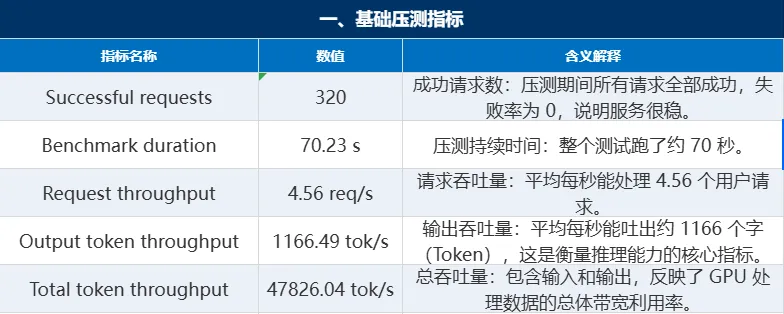
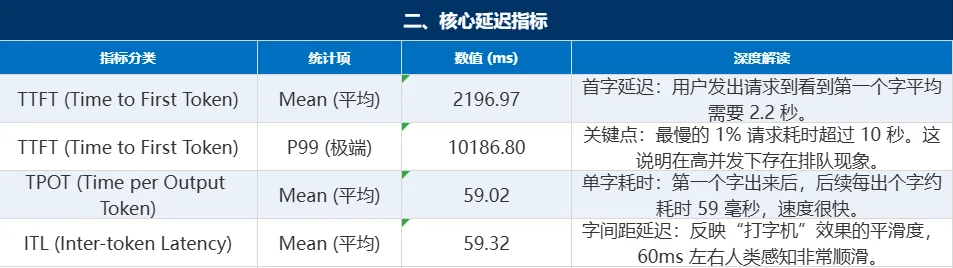
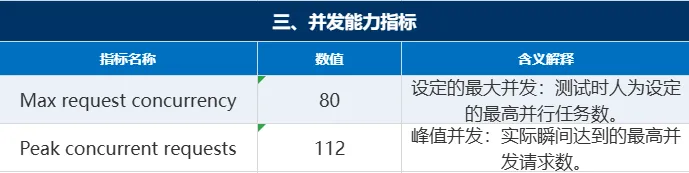
总结
在大模型运维中,“空间换时间”是永恒的真理。通过简单的 Page Cache 预热操作,我们成功将 MiniMax-M2.5 的启动耗时从“分钟级”压低到了“秒级”,极大提升了生产环境的容灾能力。后面给大家做PD分离部署。

往期内容
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- livekit-agents:用 Python 构建低延迟实时语音 AI Agent 的工业级框架
- python 学习记录(14)
- 一文看懂Python二维列表!新手也能轻松掌握
- 【第39期】21天养成编程习惯:Python刷题第14天
- 从前端到AI:Python如何重塑全栈开发的边界
- Python枚举法|盈亏问题,新手也能看懂的解题笔记
- Python 爬虫被封?2026 年最全反爬应对手册
- 不用 Python 也能做闭环控制?COMSOL 多组件耦合超实用教程
- python零基础,7天每日练习题+示例代码
- "表格處理全能手"——python中panda入門查的幾個方法
