前言
本文是一份个人实践笔记,记录了我使用 Python 为 aCRF 创建 TOC的过程中,逐渐形成的关于“AI 时代如何编程”的一些思考。
文中观点源于近期实际项目经历,无官方标准参考,不代表任何机构立场。行文浅薄,如有不同见解或更好的技术落地方式,欢迎同行友好交流、探讨指正。
首次发布:2026-05-17
业务场景
根据 SDTM-MSG v2.0 ( SDTM Metadata Submission Guidelines v2.0 ) 中的 3.3 节:
In the annotated CRF, the bookmarks essentially comprise a table of contents (TOC) for the reviewer. To facilitate a more efficient review process, a printable TOC may be included at the beginning of the annotated CRF (see following example).
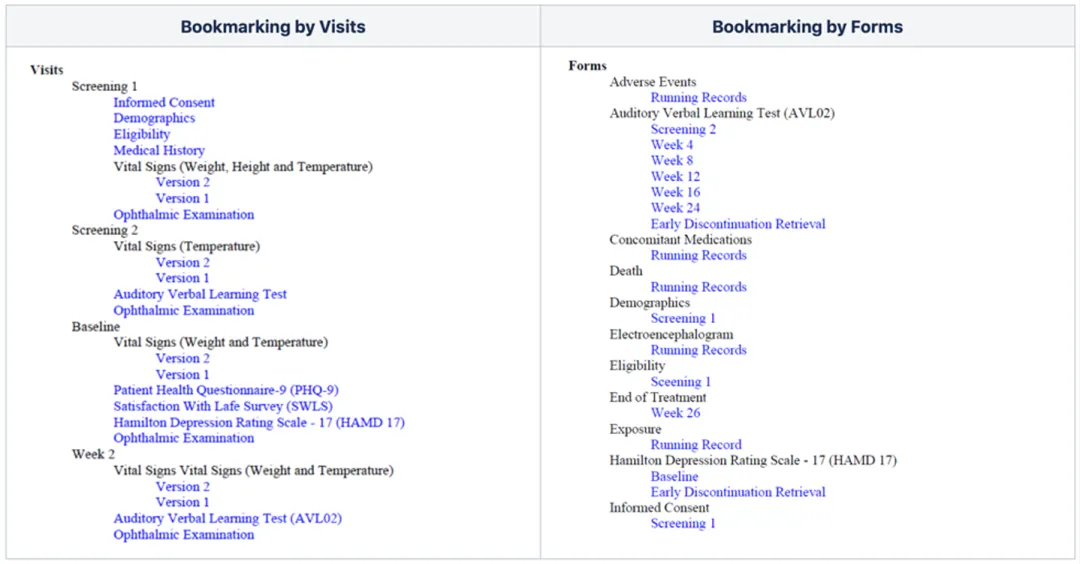
从便于审查的角度考虑,需要在 aCRF 的最前面生成 Table of Content。 之前部门的同事用 C# 开发了类似的程序,参考的是 2019 PharmaSUG 的这一篇文章:https://lexjansen.com/pharmasug-cn/2019/DS/Pharmasug-China-2019-DS24.pdf
但是运行这个程序要下载 Visual Studio。 程序是基于 .net framework 4.7.2 , 似乎不支持独立打包。意思是,部门的任何一个员工运行程序都必须下载 .net framework 4.7.2, 使用 clickonce 打包的 .exe 程序如果在未安装 .net 的电脑上是运行不了的。
我查到要独立打包就必须将项目的目标框架升级到 .net 6 或者 .net 8。但是升级之后,程序的某些代码又不适配,而我又不擅长 C# 编程。
于是,我帮公司开发了一个 Python 脚本完成上述工作,然后用 Pyinstaller 打包成应用程序。这样没有安装 Python 的同事也可以使用这个工具。
思考与任务的结构化拆分
我思考的步骤如下:
首先要读取 aCRF 现有的3级书签。我打算在 TOC 展示的只有3级书签的名称,不包括页码。然后,要确保相关的 Python 函数能够读到书签的内容,比如 PyMuPDF 库中的 get_toc (simple=True)。
要明确新增空白页的数量,这些空白页是用来展示 TOC 的内容。那么需要一个变量控制每一页展示的行数,所以新增的空白页的数量= 书签总行数/每一页的行数 再向上取整。
下一步,需要一行一行的把书签内容打印在空白页上,思路大概是使用循环。那么根据呈现的内容还需要考虑什么呢?需要控制每一页第一行和顶端之间的上边距(y值),每两行之间的间距,第1级书签距离纸张左侧的边距,1级和2级,2级和3级之间的层级缩进(设计为固定值)。
考虑添加超链接的问题。这个3级书签的第3级,也就是 level 3, 对应着 aCRF 具体的表单。所以第3级可以添加链接。点击 TOC 中第3级的内容,可以自动链接到相应的表单页面。
考虑字体。临床试验项目 CRF 可能是中文的,也有可能是英文的。那么需要让人工选择相应的FONT,就要设置一个选择框。中文用什么字体,英文用什么字体,字号是多少(设置对应的变量)。
整体的输入与输出。这一套程序最终实现的是,输入一个 PDF, 输出一个加了 TOC 的 PDF 文件。
以上是进行拆解后的任务,那么上面的每一个步骤都需要有对应的代码来实现。
关于 AI 时代编程的一些思考
随着各个 AI 工具的快速发展,一个残酷的事实已经出现了: 如果一个人的价值仅仅是“写出能运行的代码”,那么他的价值正在迅速贬值。
事实上,只要写出了上面拆解的结构,剩下的内容都可以交给 LLM 去实现,然后编程员再去审查 LLM 生成的代码,判断是否体现了需求。这是一套人机协作编程的框架:
拆解任务 → 明确需求边界 → 借助AI生成代码 → 重点审查AI代码如何体现需求 → 理解并集成
很可能未来各个行业的编程工作都会按照这个框架实施。AI 会成为“能够快速生成草稿的初级工程师”,而人类承担架构师+代码审查员的角色。
可能有的人用 AI编程不会重视“审查”,他们往往会进行“抄作业式”编程:把 LLM 生成的代码直接复制到编译器上,跑跑看,简单观察一下是否能输出相应的结果。
但真正落地的工具,其复杂性往往不在“主功能”,而在“边界条件处理”。 拿上面开发的小工具举例:输入的PDF没有书签怎么办?书签层级超过3级怎么办?中文和英文混排时字体回退怎么处理?新增空白页后原有的页码标注是否需要更新?这些边界条件,AI很容易忽视,而这是人类必须要考虑的。
AI 可能会生成 “看起来合理” 的代码,但实际上包含错误的业务逻辑。人类(编程员)需要根据业务逻辑审查 AI 输出的内容。审查包含两方面:一方面是审查代码逻辑(仍然需要掌握基础的编程知识),另一方面是通过各种类型的测试检验输出的内容。
如果未来临床试验需要开发更复杂的工具来提高效率,从合规的角度必然需要追求可追溯性与可复现性。当被问道,为什么这样 derive ? 不能只说 “这是 Deepseek 或者 ChatGPT 生成的”,而是应该理解代码背后的业务逻辑(规则)、处理的数据结构以及边界条件。按照趋势,行业内更欣赏的肯定是 Robustness 强、可复用、可配置的工具包或内部R包 / Python库。
✍️ 文 / Yuang 临研数据人: 用数字讲述药物故事
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
