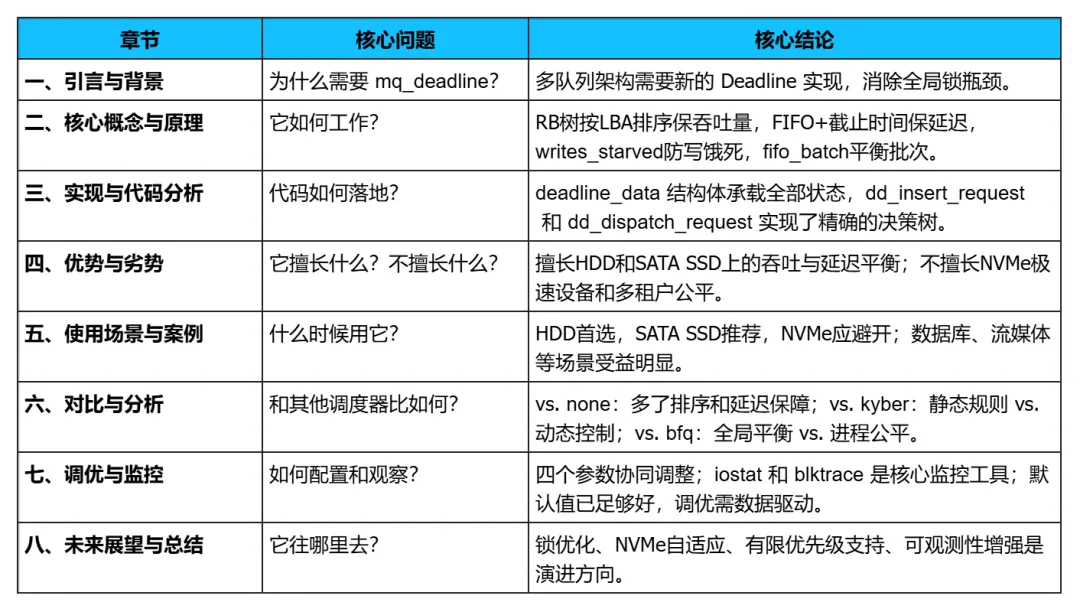
一、引言与背景
这一部分的目标是让读者在进入技术细节之前,先建立起三个关键认知:- Linux块层架构的演进(单队列 → 多队列),以及为什么 mq_deadline 是这种演进的产物
- mq_deadline 的设计初衷和它要解决的核心矛盾
1.1 IO调度器的角色
IO调度器是操作系统块层(Block Layer)中的核心组件。它的位置在文件系统之下、设备驱动之上。当一个进程发起磁盘读写请求时,这些请求不会立刻发给硬件,而是先在调度器里“排队”。调度器的工作是决定:- 机械硬盘(HDD):磁头寻道是机械运动,成本极高。按物理位置(LBA,逻辑块地址)排序可以大幅减少寻道时间,提升吞吐量。
- 固态硬盘(SSD):没有机械部件,但对NAND闪存的并发读写也需要调度来平衡吞吐量和延迟。
除了排序,调度器还负责防饿死——不能因为持续有新请求到来,就让某些请求永远得不到服务。
1.2 单队列时代与Deadline调度器
在传统的Linux单队列块层中,所有请求都塞进一个全局队列,配一个全局锁。经典Deadline调度器在单队列时代表现优异,其核心策略就是——在吞吐量和延迟之间找到一个平衡点:- 两个红黑树:读请求RB树、写请求RB树,都按LBA排序,用于实现批量顺序服务,最大化吞吐量。
- 两个FIFO链表:读请求FIFO、写请求FIFO,所有请求按到达时间排序。
- 截止时间:每个请求都有一个过期时间(读500ms、写5秒,默认值)。调度逻辑优先服务FIFO中已经到期的请求,以防饿死。
这套机制既保证了吞吐量(大部分时间按LBA顺序),又控制住了延迟(超时请求会被强制提升优先级)。
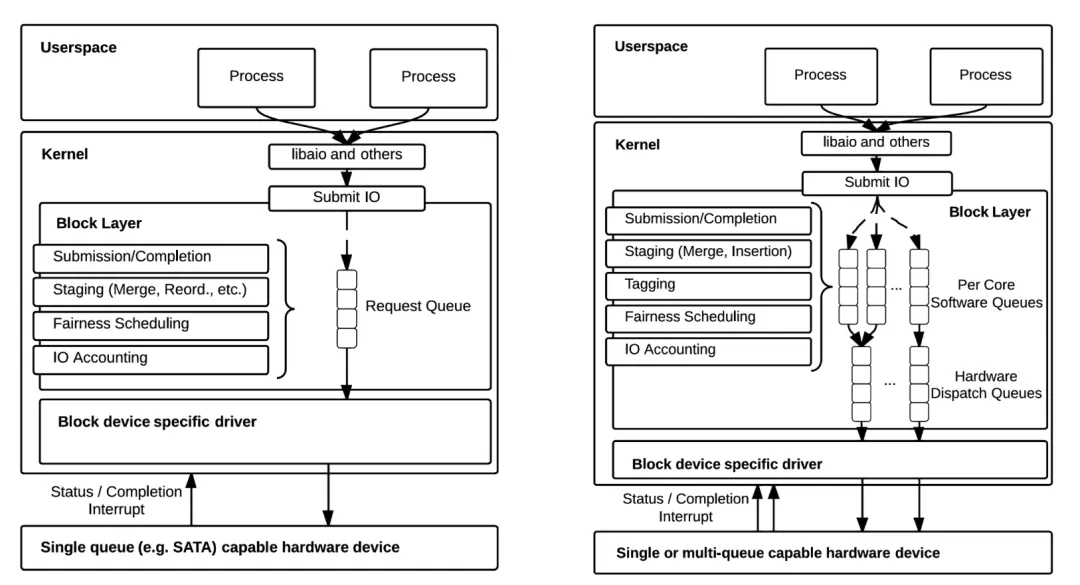
1.3 多队列架构的到来:为什么需要 mq_deadline
- 多核CPU:多个核并发提交IO,争抢同一个全局锁,锁竞争成为瓶颈。
- 高速SSD(尤其是NVMe):一个设备有多个硬件队列,可以并行处理命令。单队列架构无法充分利用这种并行性。
Linux内核因此在块层引入了blk-mq(多队列)框架。其核心变化是:在多队列架构下,每个CPU核心或每个硬件队列可以有自己独立的软件队列,大大减少了锁竞争。但这也带来了一个新问题:经典的Deadline调度器是基于单队列设计的,需要全局排序,无法直接运行在多队列架构上。mq_deadline 就是为了解决这个问题而诞生的——它把Deadline调度器的核心算法,适配到了blk-mq的多队列框架上。
1.4 mq_deadline 的设计定位
mq_deadline 不是简单地把老代码移植过来。它在设计上做了关键调整:- 每个硬件队列独立调度:mq_deadline 在每个硬件队列(blk_mq_hw_ctx)上维护独立的调度数据结构(RB树和FIFO),各队列之间独立调度,没有全局锁。
- 保持核心算法:每个队列内部的调度逻辑和经典Deadline完全一致——排序、批处理、截止时间、防饿死。
- 可扩展性:多核可以并行地向不同硬件队列提交请求,没有全局锁竞争。
- 算法成熟度:Deadline的算法经过了多年验证,稳定可靠。
但同时也带来了一个天然的局限性:调度是per-queue的,全局的请求顺序不再被保证。不同硬件队列之间的请求没有排序。不过这在实践中通常不是问题,因为现代设备(尤其是NVMe SSD)的硬件队列本身就是独立并行处理的。
二、核心概念与原理
2.1 根本矛盾:吞吐量 vs. 延迟
任何磁盘 IO 调度器都需要回答一个问题:下一个派发什么请求?如果只追求吞吐量,就应该始终按 LBA(逻辑块地址)顺序服务——机械硬盘的磁头可以一路走下去,SSD 也能更好地利用内部并行性和预读。但这样会产生严重的不公平:一个离磁头很远的请求,可能因为一直有近处的新请求加入,而被无限期推迟——这就是饥饿。如果只追求延迟,就应该严格按 FIFO(先入先出)顺序服务——谁先来谁先走,绝对公平。但这样吞吐量会崩溃,因为磁头会疯狂来回寻道。mq_deadline 的目标是:在不饿死任何请求的前提下,最大化吞吐量。它用一组精心设计的数据结构和调度策略,把这两者拧在了一起。
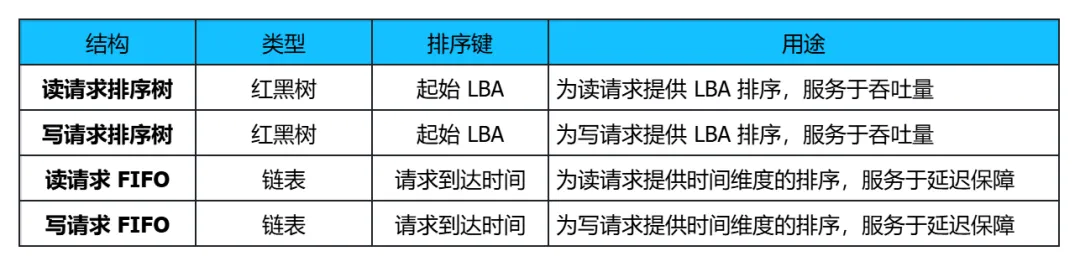
2.2 核心数据结构:四棵树(其实是两棵树 + 两个链表)
mq_deadline 为每个IO优先级维护独立的数据集。它管理着四个核心数据结构:enum dd_prio { DD_RT_PRIO = 0, DD_BE_PRIO = 1, DD_IDLE_PRIO = 2, DD_PRIO_MAX = 2,};
红黑树保证插入、查找、删除的时间复杂度都是 O(log n)。当硬件队列里堆积了大量请求时,能快速找到下一个“LBA 最小”或“LBA 最大”的请求,从而实现高效排序。- 读:通常由进程同步触发,对延迟极度敏感(用户等着呢)。
- 写:通常可以异步回写,对延迟相对不敏感,但吞吐量大。
分开管理可以给读请求更高的优先级,同时防止写请求被饿死。一个请求被插入时,会同时加入对应类型的 RB 树和 FIFO 链表。这意味着每个请求在“空间”和“时间”两个维度上都建立了索引。
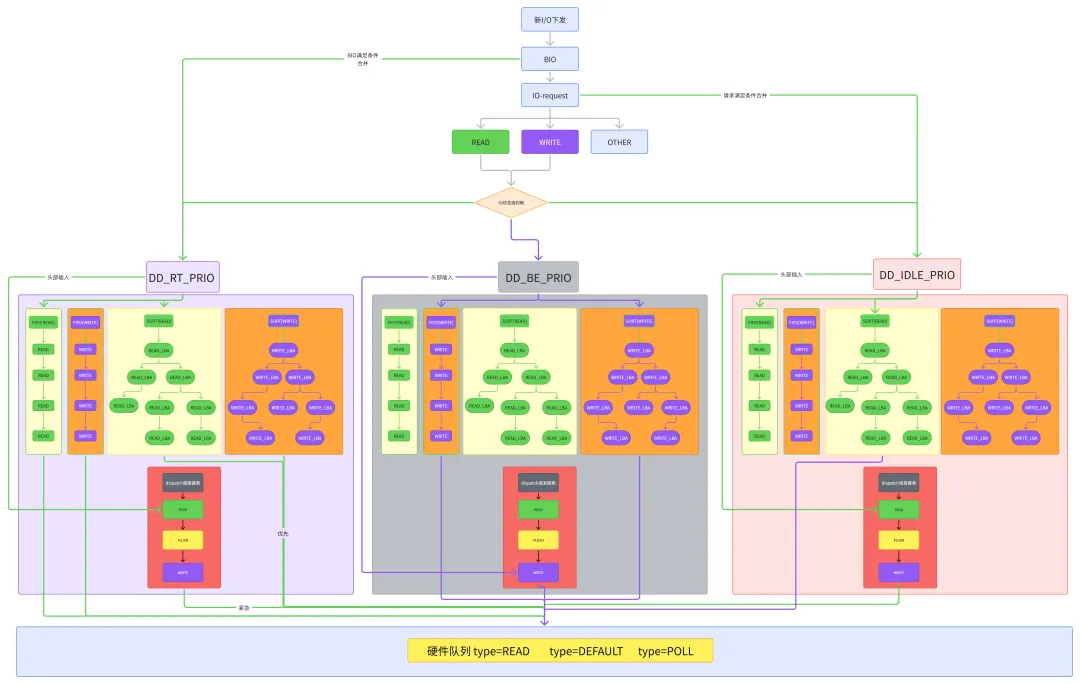
2.3 调度决策流程:三个核心步骤
调度器在派发下一个请求时,按以下优先级顺序做决策:每个请求在进入 FIFO 时,都会被标记一个截止时间:- 读请求截止时间= 到达时间 + read_expire(默认 500 ms)
- 写请求截止时间= 到达时间 + write_expire(默认 5000 ms)
/* * See Documentation/block/deadline-iosched.rst */static const int read_expire = HZ / 2; /* max time before a read is submitted. */static const int write_expire = 5 * HZ; /* ditto for writes, these limits are SOFT! */
调度器每次派发前,先查看读/写 FIFO 的队首,如果队首请求已经过了截止时间,就认为它“过期了”。如果存在过期请求,无条件优先派发 FIFO 方向——即从到期批次中,按 FIFO 顺序取出一批请求派发。这样做是为了强制保证延迟上限:只要你的读写截止时间设置合理,任何请求都不会被无限期推迟。如果没有任何请求过期,调度器就进入吞吐量优化模式:按LBA顺序服务。但这里有一个讲究:调度器不是一次只派发一个请求,而是按批次(batch)派发。一个批次是一次连续的、按 LBA 方向(递增或递减)的扫描。- 一次读批次可以派发 fifo_batch 个请求(默认16)。
- 一次写批次可以派发 fifo_batch 个请求(被写请求“写饥饿”逻辑覆盖,见下文)。
做完一个方向的批次后,调度器会换到下一个方向(读→写或写→读),避免读写之间互相饿死。/* * Time after which to dispatch lower priority requests even if higher * priority requests are pending. */static const int prio_aging_expire = 10 * HZ;static const int writes_starved = 2; /* max times reads can starve a write */static const int fifo_batch = 16; /* # of sequential requests treated as one
当确定了当前要服务哪个类型(读/写)以及方向(LBA升序或降序)后,调度器从对应的RB 树中取出 LBA 合适的一批请求进行派发。
2.4 截止时间(Deadline)的防饿死机制详解
上面我们提到“检查过期请求”。这背后的设计意图非常清晰:正常模式下,请求按照 LBA 顺序服务,读请求和写请求轮流获得批次。异常情况下(某个请求等太久了),调度器立即中断当前的顺序服务,强制切到 FIFO 模式去派发那个老请求。- 读FIFO队首过期→ 立即派发一个读批次(按 FIFO 顺序取),无视当前是否在写批次。
- 写FIFO队首过期→ 立即派发一个写批次(按 FIFO 顺序取)。
注意读的到期时间(500ms)远比写(5s)短。这体现了读优先策略——毕竟用户直接感知读延迟。但写也有5秒的硬保底,不会永饿。
2.5 写饥饿与 writes_starved 计数器
尽管读写各有 FIFO 保底,但“批次切换”还存在另一个维度的公平性问题。假设一直有读请求到来,调度器会不断启动读批次,写批次根本没机会被执行——即使写请求还没到5秒过期线。mq_deadline 引入了一个writes_starved计数器(默认值为2)。其工作方式为:- 每次调度器完成一个写批次后,将 writes_starved 重置为默认值。
- 每次调度器被迫派发一个读批次,并且这个读批次不是因为写过期而触发的(即正常吞吐量优化模式下的读批次),就将计数器减1。
- 当计数器减到0时,强制切换到一个写批次,即使写请求没有过期,读请求也还有不少。
这意味着:写请求最多被读批次“插队” writes_starved 次,之后必定轮到写批次。这个参数避免了读流持续压制写流。
2.6 批处理 (fifo_batch) 的作用
fifo_batch(默认16)控制一个批次内的请求数量。它的设计考量:- 不能太小:太小会导致频繁的批次切换,LBA 排序的优势无法充分发挥。
- 不能太大:太大意味着一次批次占用设备太长时间,会增大其他请求(尤其是另一类型的请求)的尾部延迟。
- 对 FIFO 过期也有影响:即使一个请求过期了,调度器也只会从它的 FIFO 中取出至多fifo_batch个请求,而不是一次性清空整个 FIFO。这是为了避免一次过期请求引发雪崩式的 LBA 无序派发,从而急剧拉低吞吐量。
2.7 章节小结:一次完整的调度决策树
将上面的逻辑串联起来,调度器每派发一个请求,大致经历以下决策过程:- 读 FIFO 队首过期? → 是 → 派发读批次(FIFO方向,最多 fifo_batch 个)
- 写 FIFO 队首过期? → 是 → 派发写批次(FIFO方向,最多 fifo_batch 个)
- 当前处在“写饥饿”状态(writes_starved 计数器归零)? → 是 → 强制切换到写批次(按 RB 树顺序)
- 否则,按正常批次轮转逻辑,派发一个读或写批次(按 RB 树顺序,LBA 升/降序扫描)
这就是 mq_deadline 在单硬件队列内部的全部调度智慧:靠 RB 树保吞吐量,靠 FIFO 截止时间保延迟上限,靠writes_starved防止写饿死,靠fifo_batch平衡批次大小。三、实现与代码分析(kernel6.18)
四、优势与劣势
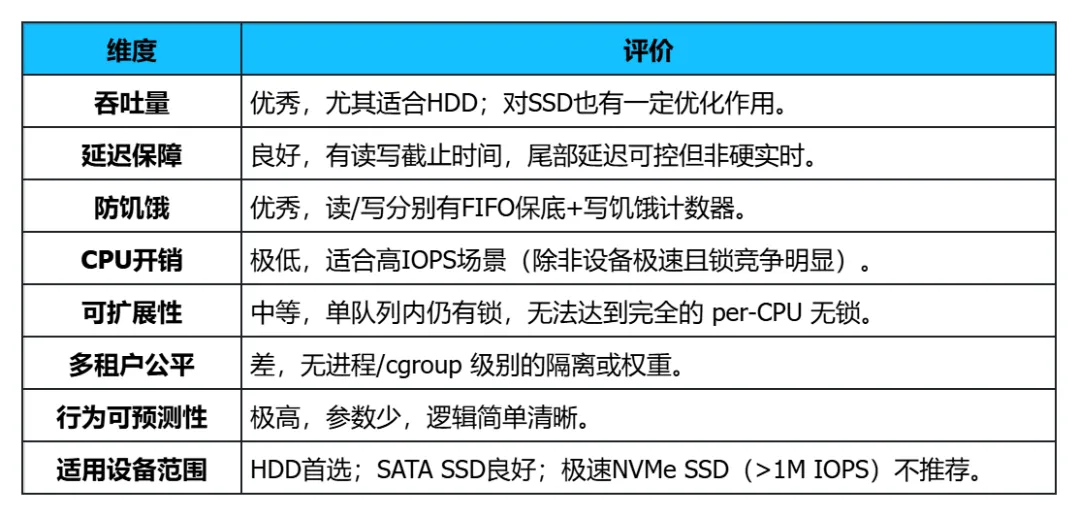
4.1 优势
mq_deadline 最核心的竞争力在于,它通过极简的机制(RB树+LBA排序 + FIFO+截止时间)同时做到了:- 高吞吐量:在正常无过期请求的情况下,始终按LBA顺序批量派发,最大化机械硬盘的连续读写能力,也能很好地利用SSD的内部并行性。
- 延迟上限保障:硬性的截止时间机制保证任何请求的等待时间不会超过预设值(默认读500ms、写5s),避免了传统纯LBA排序算法(如 noop 或早期电梯算法)可能导致的严重饥饿。
这是一个经过长期生产验证的算法,在HDD上几乎没有对手。除了读写截止时间,writes_starved 计数器是一个非常精巧的设计。它用一个简单的计数器,解决了“读流持续压制写流”的经典难题,确保即使读负载极高,写请求也能周期性获得服务,不会无限期推迟。这种机制比许多复杂的启发式公平调度更简单、更可靠。- 每次插入/派发主要是红黑树的 O(log n) 操作和链表追加/移除操作。
- 在多队列架构下,每个硬件队列独立调度,无全局锁竞争,完美贴合 blk-mq 的设计哲学。
相比 BFQ(预算公平排队)这类需要进行复杂会计统计、权值计算的调度器,mq_deadline 对CPU的占用可以忽略不计,因此即使在极高 IOPS 的场景下,它也不会成为瓶颈。整个调度器只有几个参数(read_expire、write_expire、fifo_batch、writes_starved),且每个参数的作用都非常直观。管理员可以根据业务延迟敏感度进行精细调整,而不需要理解复杂的加权公平模型。这使得它在运维侧的接受度很高。
4.2 劣势
虽然 mq_deadline 适配了多队列框架,每个硬件队列独立调度,但在单个硬件队列内部,它仍然是全局排序。这意味着:- 单个硬件队列上的所有请求仍然要争抢该队列的锁(hctx 锁),在多核并发访问同一硬件队列时(某些中断分配策略会导致),仍存在一定的锁竞争。
- 它没有实现真正的“per-CPU软件队列无锁化”,只是把原来全局的大锁拆分成了多个硬件队列的小锁。
在极高 IOPS 的 NVMe SSD 上(例如百万级 IOPS),这种小锁竞争和排序操作的开销可能仍然不被接受。因此对于极速设备,内核社区推荐直接使用 none 调度器。对于高端 NVMe SSD,其内部控制器已经非常擅长命令调度、并发处理和磨损均衡。在内核侧再增加一层 LBA 排序,不仅不会带来吞吐量提升,反而可能引入不必要的延迟。此时 mq_deadline 的“排序 + 批处理”逻辑其实是在帮倒忙。mq_deadline 是面向请求的调度,完全不关心请求来自哪个进程(或 cgroup)。在多个租户共享同一块磁盘时,一个恶意或异常的进程可以无限制地提交请求,占满调度器的队列,导致其他进程的I/O延迟大幅升高。它无法提供像 BFQ 那样的进程级带宽隔离或权重分配。尽管有截止时间,但 mq_deadline 的保障是“尽力而为”式的:- 如果到达过期请求时,设备正在忙于处理之前派发的一批请求(不可抢占),实际的完成延迟可能会超过截止时间。
- 即使触发了 FIFO 派发,它也只派发一个有限批次的过期请求,后续的过期请求可能要等下一个批次。在极端负载下,尾部延迟仍可能飙升。
因此它仅适合“软实时”或“交互式延迟敏感”场景,不适用于硬实时系统。
4.3 优劣总结表
有了前面四章的理论基础,现在可以回答最关键的实际问题:在什么情况下应该选用mq_deadline?什么情况下应该避开它?
五、使用场景与案例
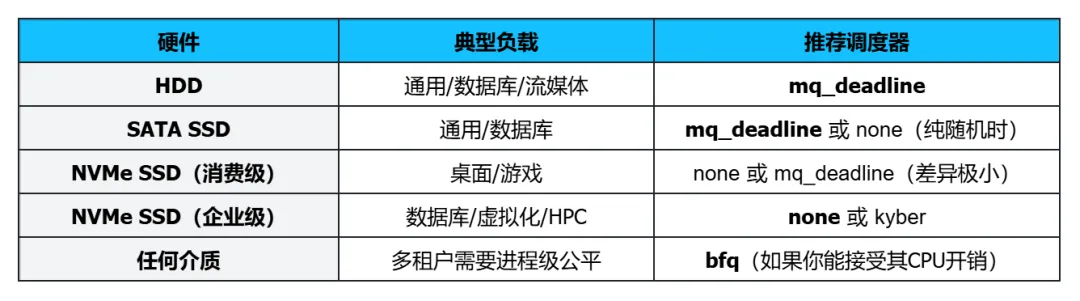
5.1 硬件维度:设备类型决定选型方向
磁盘调度器的效果与底层硬件特性强相关。选型的第一原则是看设备。
5.1.1 机械硬盘(HDD)——最佳战场
对于任何形式的机械硬盘(包括SATA HDD和SAS HDD),mq_deadline 几乎总是最佳选择。- HDD的寻道时间在毫秒级(通常2-10ms),LBA排序带来的吞吐量提升是巨大的(可达数倍)。
- 截止时间机制能防止个别请求在排序过程中被饿死,兼顾了交互式应用的延迟体验。
- mq_deadline 的CPU开销极低,绝不会成为HDD的性能瓶颈——HDD本身的IOPS上限(通常100-200)远低于调度器可处理的范围。
5.1.2 SATA/SAS SSD —— 依然合适
对于SATA或SAS接口的固态硬盘,mq_deadline 仍然是一个很好的默认选择。- SATA SSD虽然没有机械寻道,但其命令队列深度有限(通常32),接口带宽有限(6Gbps)。在这种情况下,块层做适量的排序和批处理,可以帮助聚合请求、减少协议开销,对整体性能仍有正面影响。
- 对于混合负载(既有顺序读写也有随机读写),mq_deadline 的批次处理能保证顺序流不会被随机流完全淹没。
如果确认工作负载是纯随机I/O(例如虚拟机镜像、数据库随机读写),切换为 none 有时能进一步降低1%-3%的CPU开销。但除非IOPS极高,否则差异微乎其微。
5.1.3 高端 NVMe SSD —— 不推荐
对于企业级NVMe SSD(尤其是支持数百万IOPS的型号),mq_deadline 往往会成为性能的阻碍。- NVMe设备内部有强大的控制器进行命令调度,块层再做LBA排序纯属冗余。
- NVMe协议的硬件队列深度极深(可达64K甚至更高),设备可以充分并行处理命令。mq_deadline 的批处理实际上降低了派发的并行度。
- 在百万级IOPS下,mq_deadline 的红黑树操作和锁开销开始变得肉眼可见。
- none(noop):绝大多数情况下的最优解。零调度开销,完全依赖设备内调度。
- kyber:如果需要对读/写延迟进行精细的目标控制(例如设定读延迟目标),kyber 比 mq_deadline 更适合高速SSD。
5.1.4 高性能计算(HPC)与 AI 训练数据加载
任何额外的调度层都只会增加延迟抖动。none 是最干净的选择。
5.2 案例说明:一个常见的故障场景
假设你有一台数据库服务器,数据盘是SATA HDD,业务高峰期用户频繁投诉“查询变慢”。你用 iostat 观察到,读请求的 await(平均等待时间)偶尔飙升至数秒。- 数据库后台有大量脏页正在回写,这些写请求铺满了磁盘队列。
- 如果没有截止时间保护(如使用 none),读请求会被排在这些写请求后面,等待所有写完成后才被服务,导致读延迟爆炸。
- 当有读请求在 FIFO 中等待超过 500ms(默认)时,调度器强行中断当前的写批次,切换到读 FIFO 模式优先服务读请求。
- 读延迟被强制约束在亚秒级,即使后台正在疯狂刷脏页。
- 写请求因为有 writes_starved 保护,也不会完全停滞——最多连续错过2次后,强制执行一个写批次。
结论:mq_deadline 的截止时间机制,直接命中了这个场景的核心痛点。
5.3 选型决策速查表
六、对比与分析
6.1 为什么需要对比?
Linux 内核在 blk-mq 框架下提供了多种 IO 调度器,它们并非简单的“谁更好”的关系,而是代表了在不同场景下对吞吐量、延迟、公平性和 CPU 开销的不同权衡。没有银弹,选型就是找最符合你需求的那个权衡点。
6.2 各调度器核心机制速览
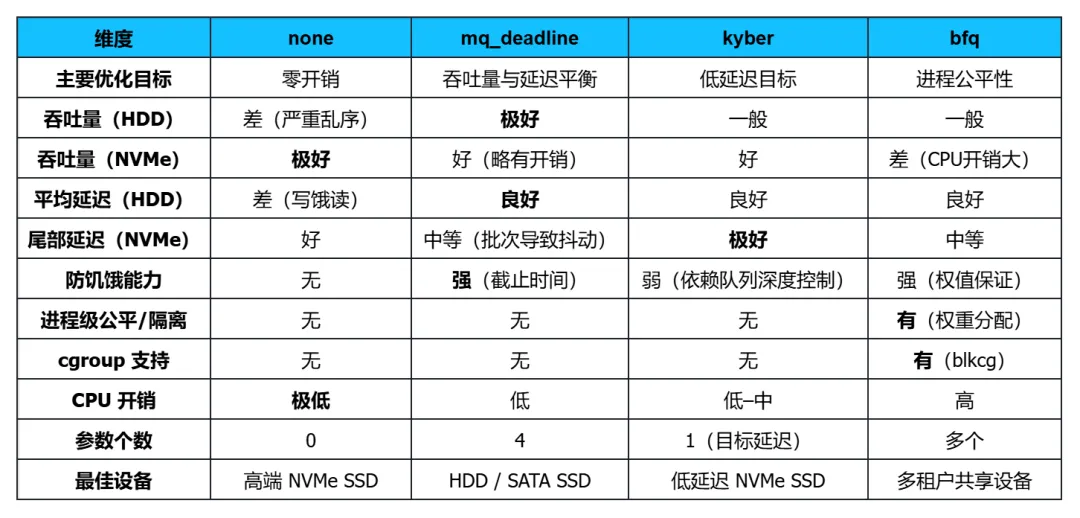
为了进行有意义的对比,先简要回顾一下它们的工作原理:6.2.1 none(No-op)
策略:几乎不做任何调度。只维护一个简单的 FIFO 队列,可能进行请求合并,然后直接派发。设计哲学:相信硬件设备自身的调度能力已经足够,内核层不应增加任何延迟或计算开销。6.2.2 mq_deadline
策略:每个硬件队列内维护 LBA 排序红黑树 + 截止时间 FIFO。按批次服务,兼顾吞吐与延迟。设计哲学:软件层需要主动排序来优化机械寻道,同时用硬截止时间防止饥饿,但尽量避免复杂的统计和预测。6.2.3 kyber
策略:通过动态调整派发队列的深度来实现延迟目标。它维护读写请求的独立队列,根据观测到的完成延迟与目标延迟的差值,自动限制同时派发到设备的请求数量。设计哲学:对于高速 SSD,控制队列深度是影响延迟的关键,而不是 LBA 排序。用自适应算法实现低延迟,无需静态参数。6.2.4 bfq(Budget Fair Queuing)
策略:为每个进程(或 cgroup)分配独立的调度队列和权重。调度器根据权值按比例分配服务时间片(budget),并支持 I/O 优先级继承。设计哲学:IO 调度应该像 CPU 调度一样实现进程级的公平共享和高优先级任务的低延迟,哪怕牺牲一部分整体吞吐量。
6.3 多维度横向对比
6.4 关键差异深度解析
6.4.1 none vs. mq_deadline:排序的意义
- none的逻辑:“设备自己会排序,我的任何插手都是添乱。” 这在设备非常智能(NVMe)时完全正确,但在 HDD 上是灾难性的,因为磁头真的会疯狂寻道。
- mq_deadline的逻辑:“设备不够聪明(或根本不知道 LBA 分布),我必须帮忙排序,同时设定一个延迟底线。”
一句话总结:none是为快速随机访问设备设计的,mq_deadline是为慢速顺序优序设备设计的。6.4.2 mq_deadline vs. kyber:延迟控制的方式
- mq_deadline:静态被动式。给每个请求设死线,到期了强行切 FIFO。这是一个“后知后觉”的兜底机制,平时不管,等问题发生了再干预。简单可靠,但可能造成延迟抖动(过期触发时突然切换顺序)。
- kyber:动态主动式。通过持续监控完成延迟,主动控制派发到设备的请求数量(队列深度)。队列深度低 = 排队时间短 = 延迟低。这是一种“防患于未然”的方式,延迟分布更平滑,但依赖准确的延迟采样和反馈调整。
对于低延迟 SSD,kyber通常能提供比mq_deadline更稳定、更低的延迟分布。但在 HDD 上,kyber 的深度控制会严重影响吞吐量,且无法补偿寻道。6.4.3 mq_deadline vs. bfq:公平性 vs. 全局平衡
- mq_deadline是无状态的、全局视角的:“我只管请求本身,不管谁发的。只要保证整体上不饿死请求就行。”
- bfq是带状态的、进程视角的:“我要保证每个进程都得到公平的磁盘时间片,即使一个进程疯狂发请求,也不能挤占其他进程的份额。”
- 在单用户/单一应用的服务器上,mq_deadline 的吞吐量会优于 bfq,因为省去了大量的进程会计开销。
- 在多用户桌面或共享存储系统上,bfq 能提供显著更好的交互体验。比如一个后台编译任务不会把桌面拖到卡死,因为 bfq 限制了它的 I/O 占比。
注意:bfq 的进程公平性在极高 IOPS 下会带来很大的 CPU 开销(需要维护和服务大量 per-进程队列),因此在高速 NVMe 设备上往往得不偿失。
6.5 本章小结
mq_deadline 在调度器谱系中占据一个非常经典的位置:它比 none 多了智能排序和延迟保障,比 bfq 少了复杂的进程公平会计,比 kyber 更依赖静态规则而非动态反馈。这使它成为了“通用磁盘调度器”的最佳平衡点——在绝大多数使用 HDD 或 SATA SSD 的通用服务器场景下,它都是最安全、最可靠、性能表现最稳定的默认选择。
七、调优与监控
7.1 查看与切换 IO 调度器
Linux 通过 sysfs 暴露了每个块设备的调度器接口。cat /sys/block/<设备名>/queue/scheduler
$ cat /sys/block/sda/queue/scheduler[none] mq-deadline kyber bfq
方括号 [...] 括起来的是当前激活的调度器。这里显示 sda 当前使用 none,同时内核编译了 mq-deadline、kyber、bfq 可供切换。直接向该文件写入调度器名称即可,无需重启,立即生效:echo mq-deadline > /sys/block/sda/queue/scheduler切换后再次查看确认:$ cat /sys/block/sda/queue/schedulernone [mq-deadline] kyber bfq
- 切换调度器不会丢失或中断正在进行的 I/O 请求,因为切换操作会等待当前调度器队列清空后才应用新调度器。
- 建议在业务低峰期操作,避免切换过程中短暂的 I/O 暂停感。
7.2 mq_deadline 的四个可调参数
mq_deadline 在 sysfs 中为每个设备暴露了以下参数(路径为 /sys/block/<设备>/queue/iosched/):$ ls /sys/block/sda/queue/iosched/fifo_batch read_expire write_expire writes_starved front_merges
7.2.1 read_expire(读请求截止时间)
# 将 sda 的读截止时间设为 200msecho 200 > /sys/block/sda/queue/iosched/read_expire
7.2.2 write_expire(写请求截止时间)
7.2.3 writes_starved(写饥饿阈值)
7.2.4 fifo_batch(批次大小)
7.2.5 front_merges(前向合并开关)
7.3 调优案例:调整数据库服务器延迟
场景:一台运行 MySQL 的服务器,数据盘是 SATA SSD,使用 mq_deadline。应用频繁投诉查询偶发性延迟很高(>1秒)。iostat 显示 w_await 稳定在 10ms 左右,r_await 平均 5ms 但偶尔峰值 2000ms。- 平均写延迟不高,但读有巨大抖动,典型“读被写批次阻塞”现象。
- 检查 writes_starved=2,意味着最多连续 2 个读批次后会有写批次。写批次可能包含大量聚集的写请求,导致后续读等待。
- 读截止时间 read_expire=500ms 应该能触发,但 fifo_batch 默认 16,可能到期时仍被大批次内的其他请求拖累。
- 降低fifo_batch到 8:减小批次大小,使调度器切换更频繁,读请求能更快得到服务。
- 降低read_expire到 200ms:让读请求更早被标记为过期,更快触发 FIFO 干预。
- 保持writes_starved=2不变,但如果观察到写吞吐下降严重,可适当提高到 3 或 4。
效果验证:重新运行 iostat -x 1 观察 r_await 的 max 值是否回落,应用侧反馈是否改善。
7.4 本章小结
mq_deadline 的调优核心就在于四个参数,它们形成了两组平衡:- 吞吐量 vs. 延迟:通过 fifo_batch 和 read_expire/write_expire 权衡。
- 读优先 vs. 写保障:通过 writes_starved 和 write_expire 权衡。
绝大多数场景默认值已经足够好。只有当你的业务特征非常明确(例如极端读敏感或极端顺序写),并且有可重复的监控数据支撑时,才需要微调这些参数。
这一章将跳出具体的技术实现,从一个更宏观的视角审视 mq_deadline:它在 Linux 内核社区中的演进方向是什么?它的核心设计思想将如何影响未来的 IO 调度?最后,我们对整个文档做一个系统性的总结。
八、未来展望与总结
8.1 mq_deadline 的演进方向
mq_deadline 本身是一个非常成熟的调度器,其核心算法(LBA排序 + 截止时间)已经经过了近二十年的生产验证。因此,社区对它的改动通常不是颠覆性的算法革新,而是围绕多队列架构的持续适配和局部优化。以下是几个值得关注的方向:
8.1.1 锁竞争优化与扩展性增强
如我们在劣势分析中所指出的,mq_deadline 在单个硬件队列内部仍然存在锁竞争问题。当多个 CPU 核心的中断被路由到同一个硬件队列时,它们会对该队列的 deadline_data 结构体产生争抢。- 更细粒度的锁机制:目前通常使用一个自旋锁保护整个 deadline_data。未来可能将读/写红黑树和 FIFO 链表分别保护,减少无关操作之间的阻塞。
- 更好地利用 blk-mq 的多队列映射:通过调整硬件队列与 CPU 的亲和性分配策略,让队列锁竞争在系统层面最小化。这更多是块层框架层面的优化,但会直接惠及 mq_deadline。
- per-CPU 插入缓冲区:请求可以先缓冲在 per-CPU 的无锁链表中,再批量插入到硬件队列的调度器中。这可以减少锁的获取频率,提升并发性能。这个思路已经在某些场景下讨论,但尚未成为主线。
8.1.2 与 NVMe 时代共存的策略
尽管我们在第五章明确指出 mq_deadline 不推荐用于高端 NVMe SSD,但现实是:- 很多系统管理员会不加区分地将所有块设备都设置为同一个调度器。
- 在混合设备环境下(既有 HDD 又有 NVMe SSD),统一的调度器配置可能带来管理便利。
因此,社区需要让 mq_deadline 在 NVMe 设备上“至少不帮倒忙”。一个可能的优化方向是自适应地检测设备特性:- 如果检测到设备是 NVMe 且队列深度极高,可以自动减少甚至禁用 LBA 排序操作,退化为类似 none 的行为。
- 这种“自适应调度器”的思想已经被讨论过,但实现起来需要在不引入过多启发式逻辑的前提下进行,这与 mq_deadline 简洁设计的理念存在张力。
目前主流的观点仍然是:在 NVMe 上直接使用 none 或 kyber,而非期望 mq_deadline 去适应所有硬件。
8.1.3 与 cgroup 和 IO 优先级框架的整合
mq_deadline 目前完全不支持 cgroup 的 blkcg(Block IO Controller),也不感知进程 I/O 优先级(ionice)。未来一个可能的演进是:在保持核心算法不变的前提下,有限地支持优先级。例如:- 高优先级进程(ionice -c1,实时 I/O 类)的请求可以获得更短的截止时间。
- 低优先级进程(ionice -c3,空闲 I/O 类)的请求可以被降低调度频次。
这种改动不会像 bfq 那样需要完整的进程队列和预算会计,但可以在一定程度上满足多租户场景的隔离需求,同时保持 mq_deadline 的低开销优势。目前这方面的讨论仍在社区进行中,尚未有确定的实现方案。
8.1.4 可观测性和调优工具的增强
与 bfq 和 kyber 相比,mq_deadline 目前暴露的统计信息非常有限。管理员很难回答类似这样的问题:- writes_starved 计数器实际触发了多少次?
社区未来可能会通过 tracepoint 或 sysfs 统计文件暴露更多内部状态,使运维人员能够基于数据而非经验去调整参数。这属于“开发者体验”和“可运维性”的改进,不是算法本身的变革,但对于实际使用非常有价值。
8.2 文档总结
8.2.1 为什么 mq_deadline 值得深入学习
mq_deadline 是 Linux IO 调度器家族中设计最优雅、实现最精简的成员之一。它的全部智慧可以用一句话概括:按物理位置排序以最大化吞吐量,按截止时间兜底以防止饥饿。
没有复杂的预测模型,没有启发式阈值,没有进程队列的维护开销。它用“两个维度(空间 + 时间)索引同一组请求”这个简单的数据结构设计,巧妙地平衡了 IO 调度中最核心的矛盾。这种“用正确的数据结构解决本质问题”的设计哲学,是 Linux 内核中非常经典的案例,值得每一位系统工程师深入学习。
8.2.2 文档核心脉络回顾
8.2.3 写在最后
在技术的演进浪潮中,新的硬件层出不穷,更快的 NVMe SSD、持久内存、计算型存储……每一种新介质都在挑战传统 IO 调度的假设。mq_deadline 代表的是一种经典的、面向旋转磁盘的设计思想。它的核心——按物理位置排序——在纯闪存时代的意义正在淡化。但是,它的另一个核心——用简洁的机制保障延迟上限、防止饥饿——是一个永恒的调度原则,无论底层介质如何变化。理解 mq_deadline,不仅仅是学会使用一个调度器,更是理解操作系统如何在“效率”与“公平”之间寻找那个精妙的平衡点。这种平衡的艺术,正是系统软件设计的精髓所在。