写在前面的话
童话里。昨天在外面抽烟,碰到一哥们,他说:我小时候有很长一段时间不理解,为什么没理我。我说:展开说说。他说:小时候,看一档全国性的节目,有个环节,看客户留言,说一个女孩,身患绝症,不想活了,当时已经是晚上十点多,节目组紧急协调当地人员,冒着大雨,千方百计找到女孩,对她进行心理疏导,最后捐款,给女孩治疗,赢得现场阵阵掌声。又过了两天,节目组举办同样的活动,他也现场留言,说我是一个贫困山区孤儿,感觉生活没希望,饥寒交迫,准备结束自己。结果等了一夜,节目组都没来找他。后来他想着,自己可能是撒谎,被节目组识破,再后来长大了,他才知道,节目组中的很多环节都是提前设计好的,撒谎的不只是他。是的,小时候我们活在童话里,长大了明白后,不要失落,因为很多事等着我们去做,加油!
[226+100]--------底部有张生活照 (头条号运营:大家想全托管上号的联系我哦,每天让你得个早餐钱,wx: qhz198607)
(头条号运营:大家想全托管上号的联系我哦,每天让你得个早餐钱,wx: qhz198607)
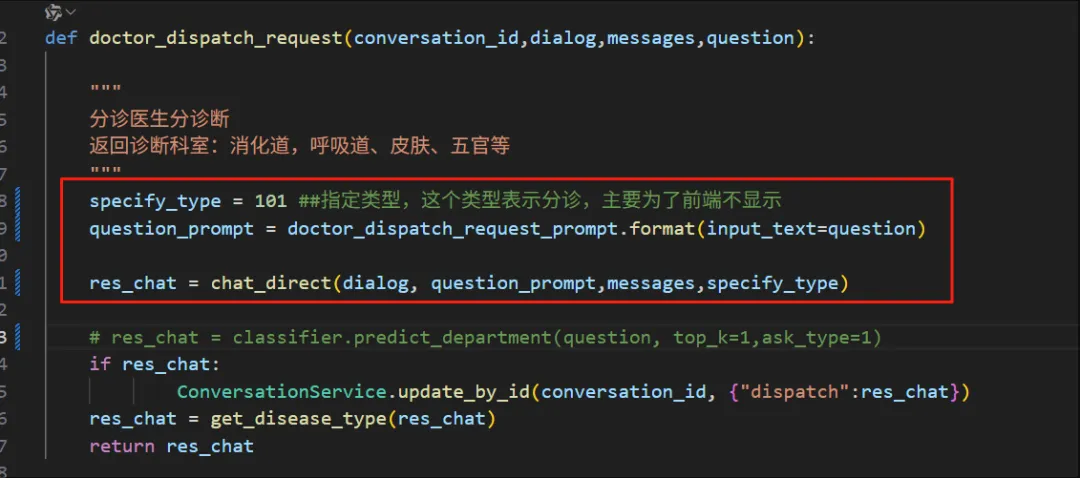
【关键词】python、ragflow、es脚本传参、索引数据分类
一、es同步脚本传参(三级)
描述:运行时 python es_sync0.py,运行脚本时,怎么传一个参数shard_id进去,以同步不同片上的数据,搞一下。
开工:
第一步:脚本传参数(四级)
20250411周五时间段:11:31-12:00
查询如下:
要为脚本添加 shard_id 参数输入功能,可以通过以下几种方式实现:
方法1:使用命令行参数(推荐)
# 在es_sync0.py开头添加
import os
import argparse
from typing import Optional
os.environ["OPENBLAS_NUM_THREADS"] = "4"
os.environ["OMP_NUM_THREADS"] = "4"
def migrate_data(shard_id: int = 0):
# 原有函数内容保持不变,将开头的 shard_id = 0 删除
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--shard-id", type=int,
default=int(os.getenv("SHARD_ID", "0")),
help="Elasticsearch shard ID (0-N)")
args = parser.parse_args()
app = Flask(__name__)
with app.app_context():
migrate_data(args.shard_id)
if __name__ == "__main__":
main()
注:对比着改一下。改完之后,运行如下:
图1a-1
注:一下子起了两个,应该会快一点。接下来,把数据进行分析下,看看分片就剩一个时,怎么做二次划分。
第二步:测试
测试还可以
二、es同步索引数据分类(三级)
描述:把索引数据进行分类,以便同步进行处理。
开工:
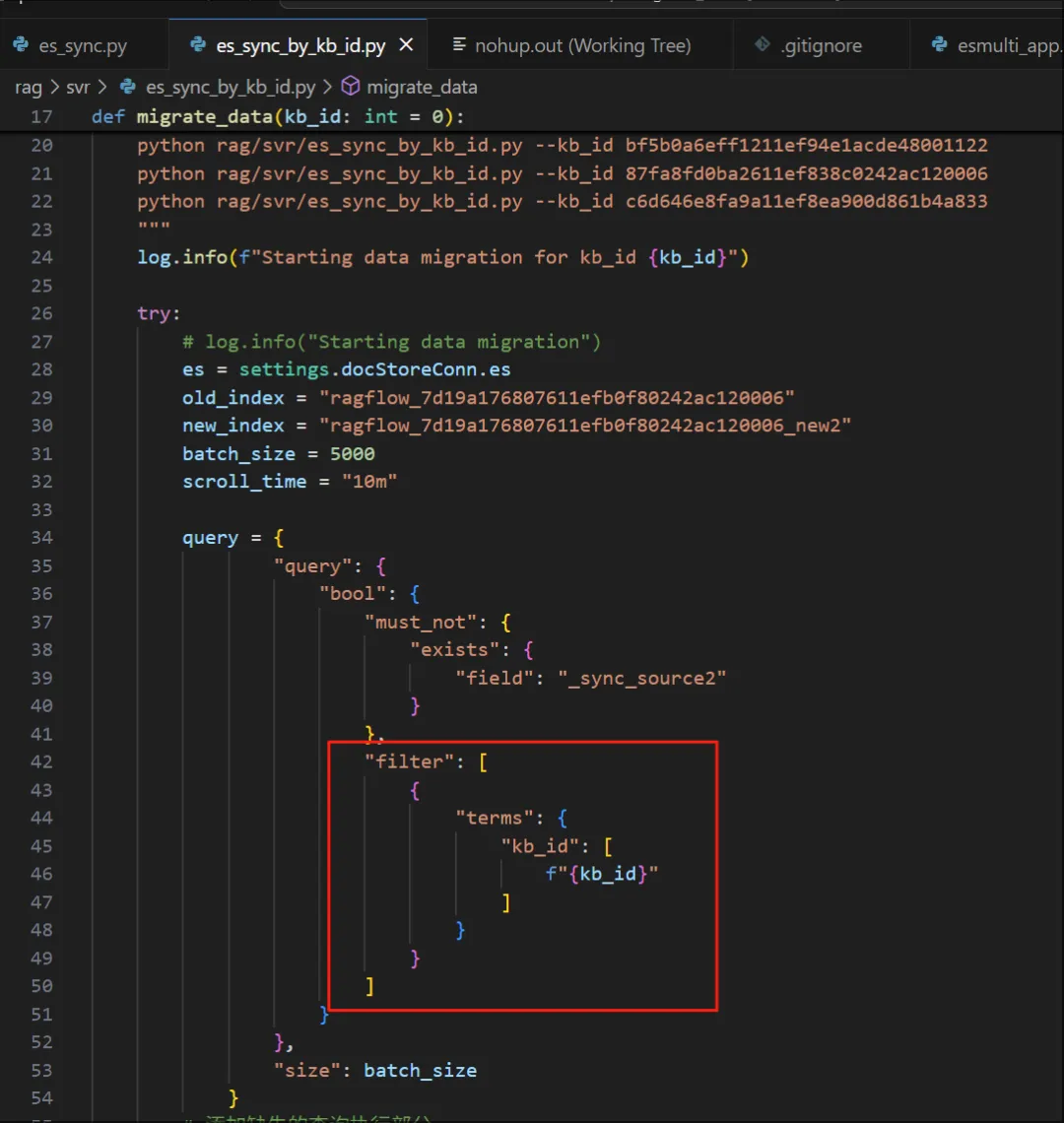
第一步:分析索引字段(四级)
20250411周五时间段:14:49-15:00
先看下有多少字段,如下:
[{
"_index": "ragflow_7d19a176807611efb0f80242ac120006",
"_id": "70ee948d87b71d13f2e01478695aaae6",
"_score": 1,
"_source": {
"weight_int": 1,
"create_time": "2025-01-03 02:39:59",
"content_with_weight": "{\"name\": \"BACTEROIDES-NODOSUS(节瘤抑杆菌)\", \"entity_type\": \"BACTERIA(细菌)\", \"description\": \"一种革兰氏阴性菌,主要引起绵羊腐蹄病。\", \"source_id\": \"验诊断/01组织细胞学/兽医病理学原色图谱.pdf-\", \"weight\": 1, \"rank\": 1}",
"_sync_source2": 1,
"create_timestamp_flt": 1735843199.190665,
"knowledge_graph_kwd": "entity",
"content_ltks": "一种 革兰氏 阴性菌 , 主要 引起 绵羊 腐 蹄 病 。 ",
"content_sm_ltks": "一种 革兰氏 阴性 菌 , 主要 引起 绵羊 腐 蹄 病 。 ",
"doc_id": "94b9fc4eba3011ef947700d861b4a833",
"title_tks": " bacteroides-nodosu ( 节 瘤 抑 杆菌 ) ",
"important_kwd": [
"BACTEROIDES-NODOSUS(节瘤抑杆菌)"
],
"kb_id": [
"87fa8fd0ba2611ef838c0242ac120006"
],
"rank_int": 1,
"docnm_kwd": "验诊断/01组织细胞学/兽医病理学原色图谱.pdf",
"_sync_source": 1,
"name_kwd": "BACTEROIDES-NODOSUS(节瘤抑杆菌)",
"q_4096_vec": [0.6]
}
}]注:看了下,知道了,可以按知识库kb_id进行分类同步数据,还可以按knowledge_graph_kwd进行同步,这里面有实体entity,也有关系relation。分别查一下。
第二步:按知识库(四级)
20250411周五时间段:15:37-16:00
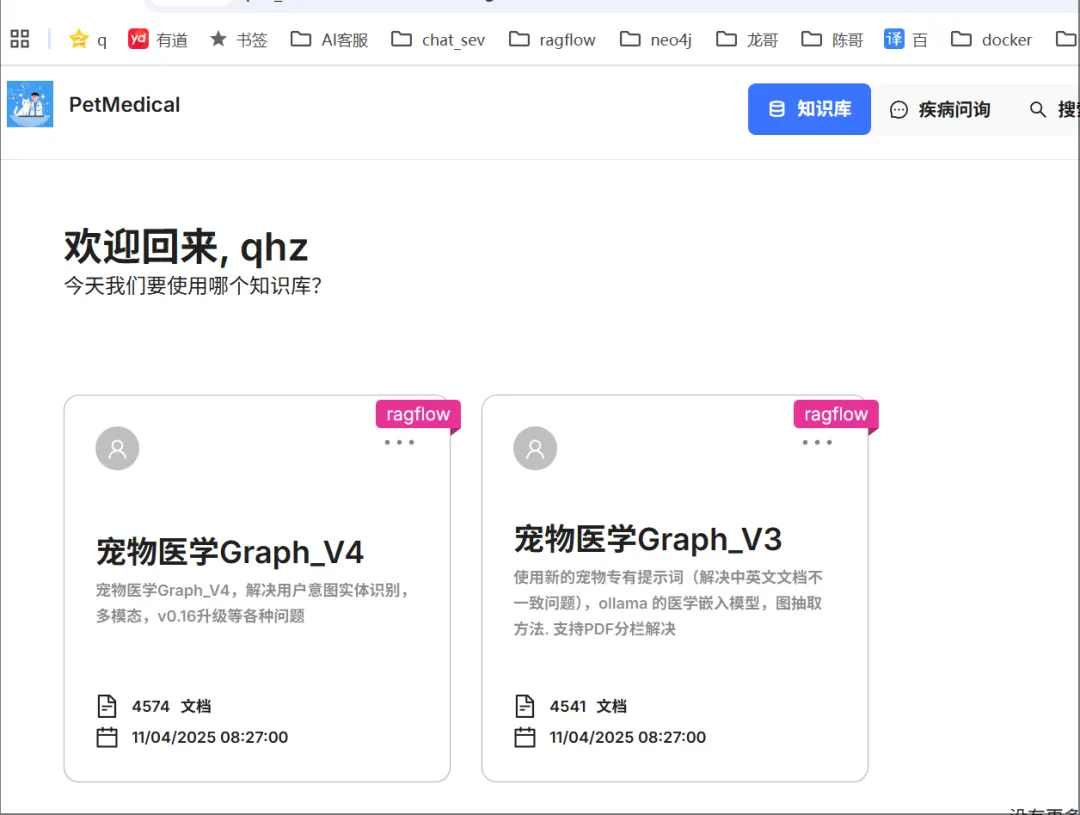
现在有两个知识库,分别是:
bf5b0a6eff1211ef94e1acde48001122 宠物医学Graph_V4
及
87fa8fd0ba2611ef838c0242ac120006 宠物医学Graph_V3
注:截图如下:
图2b-1
注:接知识库搜索一下。接下来,有一个问题,就是字段group by,看有多少值,是不是只有这两个知识库。
第三步:索引字段不同值(四级)
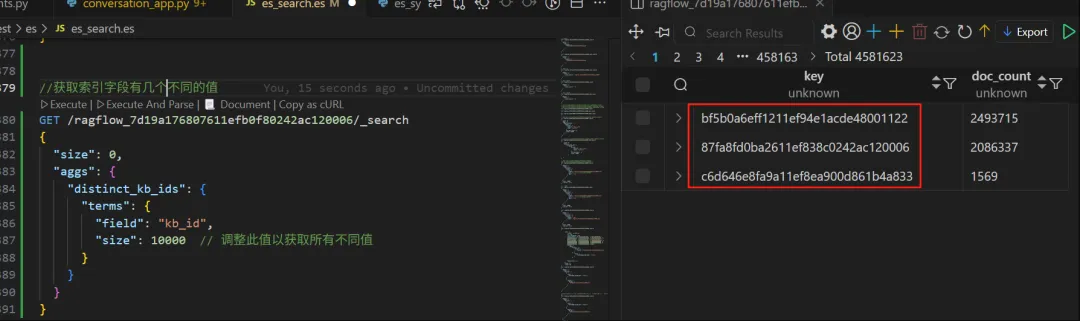
20250411周五时间段:15:37-16:00
查询语句如下:
GET /ragflow_7d19a176807611efb0f80242ac120006/_search
{
"size": 0,
"aggs": {
"distinct_kb_ids": {
"terms": {
"field": "kb_id",
"size": 10000 // 调整此值以获取所有不同值
}
}
}
}
注:获取结果截图如下:
图2b-2
注:一共有三个知识库,写个函数分一下。完成如下:
图2b-3
注:接下来,看下进程的执行情况。
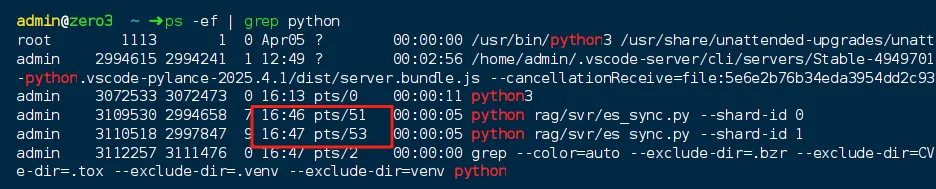
第四步:进程执行(四级)
20250411周五时间段:22:59-23:00
20250411周五时间段:23:00-00:00
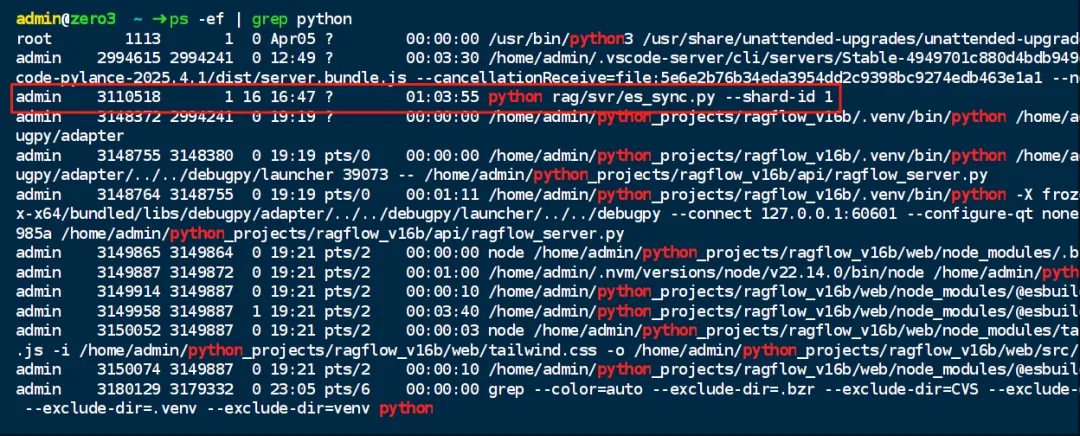
按进程id查下进程,进程id截图如下:
图2b-4
注:现在进程找不到了,截图如下:
图2b-5
注:还是存在的,只是说shard 0跑完了,接下来,要换一种打法,就是按知识库id来同步,程序写好了,运行一下。
先把旧进程id删除了。启动新的,截图如下:
图2b-6
注:接下来,把小模型换成通义千问。
三、意图识别通义千问(三级)
描述:意图识别小模型虽快,但不准确,需要把小模型换成通义千问。搞一下。
开工:
第一步:本地启动(四级)
20250411周五时间段:23:27-00:00
本地先把ragflow和web跑起来,其实也不用,跑个测试用例就可以了。
先把代码备份一下吧,接下来,跑下测试用例。
第二步:跑测试用例(四级)
20250411周五时间段:23:50-00:00
测试用例如下:
def test_multi_chat(client):
log.info("test_multi_chat0034")
'''
测试多轮对话-包括三轮对话场景
'''
json_data = {
"conversation_id": 'fff19f22fc0111efa7f900e003c42347',
"question": '呕吐内容物是食物,呕吐的动作是剧烈呕吐,每天五次,呕吐只在饭后发生。'
}
url = f"/v1/conversation/multi_chat"
resp = client.post(
url,
json=json_data,
headers={
"Content-type": "application/json",
"Authorization": "Bearer ragflow-UxOGYzZjUwYjMwOTExZWZiODc0MDI0Mm"
}
)
if not 200 <= resp.status_code < 300:
raise Exception(f"GET {url} status_code {resp.status_code}.")
# received_data = []
for chunk in resp.iter_encoded():
answer = chunk.decode('utf-8').strip()
log.info(f"\n\n answer: {answer} \n\n")
注:接下来,跑下测试用例,看看效果。
第三步:改测试用例(四级)
20250411周五时间段:23:52-00:00
把测试用例跑一下,修改成通义千问,跑起来如下:
图3c-1
注:报错了,看下为啥。
第四步:报错(四级)
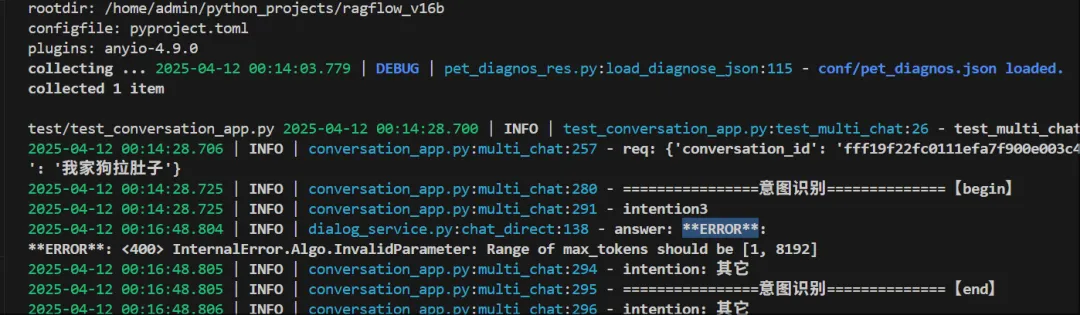
20250412周六时间段:00:19-01:00
看下为啥报错,看能不能把具体的错误打出来,如下:
图3c-2
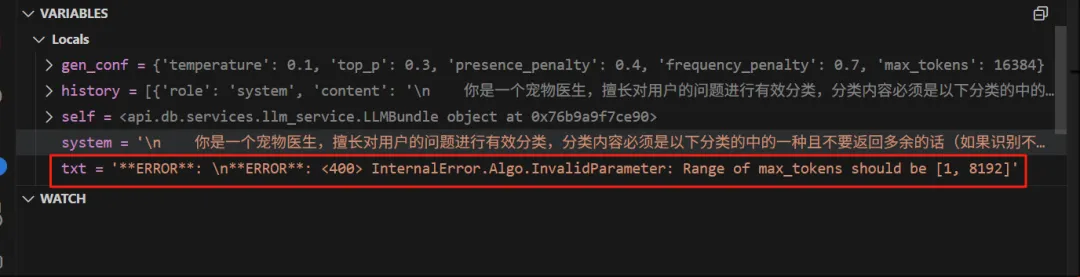
注:错误文字版本如下:
**ERROR**:
**ERROR**: <400> InternalError.Algo.InvalidParameter: Range of max_tokens should be [1, 8192]
注:修改一下max_tokens,修改如下:
图3c-3
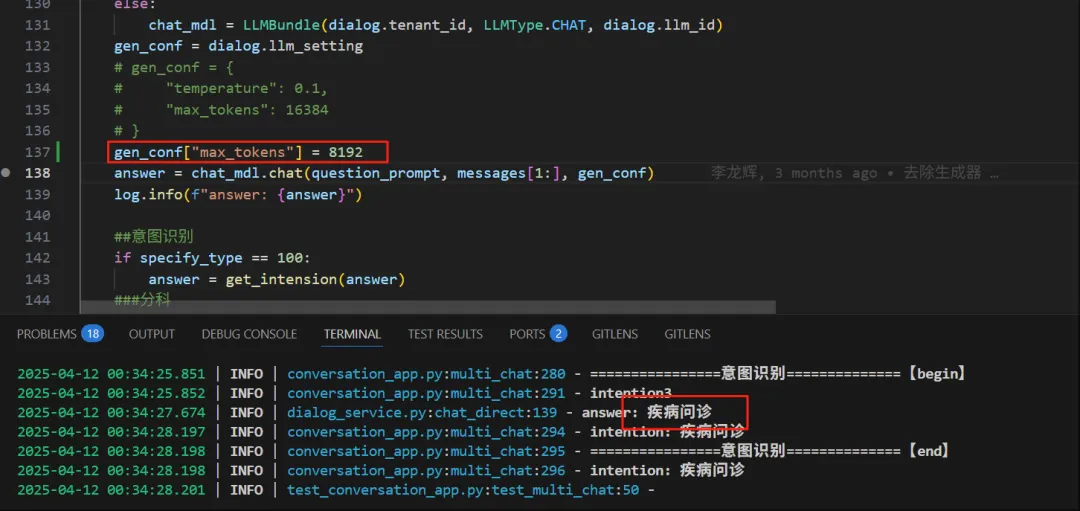
注:接下来,把分科也需要修改一下,修改如下:
图3c-4
注:这样就可以了,接下来,上线测试。
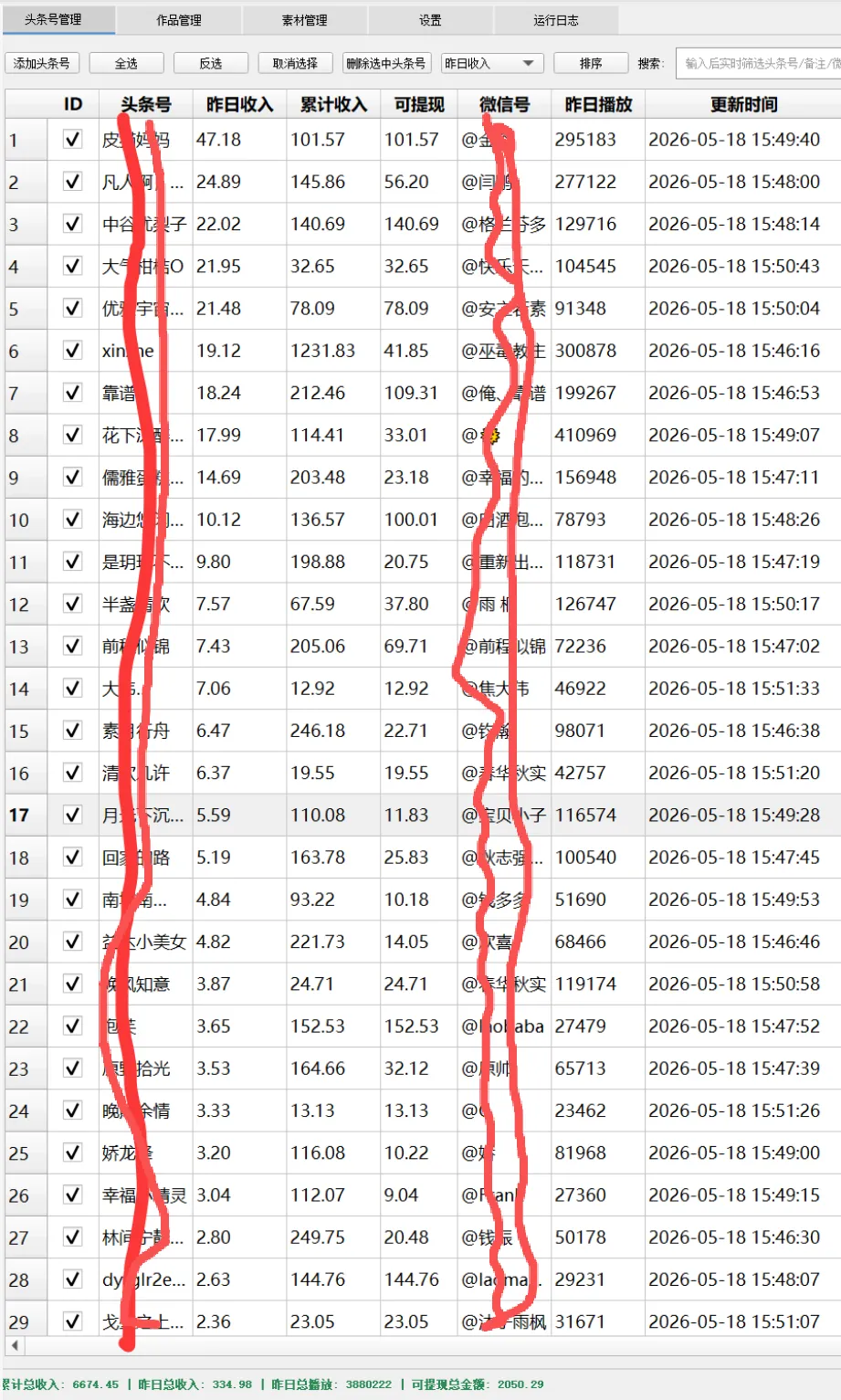
四、头条号战果汇报
昨日数据来啦,累计总收入:6674.4,昨日总收入:334.9 ,昨日总播放:388.1万,可提现总金额:2050.2,软件截图如下:
图3d-1
注:想要全脱管运营头条号的联系我,你出账号,我来运营,收益四六分成(你六我四),你当甩手掌柜,每天都能得几块零花钱,财富wx: 17701328814,也可以加群先了解一下。
图2d-2
五、生活照片
拍摄于2025年6月1日,13:13:14,带二宝在小区门口玩,当时二宝两岁八个月。小时候想着长大了就好了,不再受人欺负,并且可以支配自己的金钱,想买啥买啥。长大了发现,有很多地方花钱,根本没有财务自由,所以,我给两个孩子说,你们就负责快乐成长,现在想实现的梦想,我和你妈尽量帮你们实现,别长大了,想着小时候买一个棒球帽或者全套的奥特曼就好了,现在买了也不想玩了。每个阶段有每个阶段的义务和使命,过好每一天才是正理,加油!
图2e-1
《本文完》




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
