大家好,我是木木。
今天给大家分享一个别致的 Python 库,pony。
pony
Pony ORM 最有辨识度的地方,是它允许你用 Python 生成器表达式写数据库查询。比如 select(p for p in Product if p.stock > 0) 这种写法,看起来更像在操作对象集合,然后 Pony 会把表达式转换成 SQL。它不是最流行的 ORM,但风格很鲜明,适合对查询可读性有强偏好的团队评估。
项目地址:https://github.com/ponyorm/pony
官方文档:https://docs.ponyorm.org/
三大特点
语法特别
用生成器表达式写查询,代码很接近 Python 集合思维,对部分开发者很友好。
映射完整
实体、关系、事务、聚合和常见数据库后端都有覆盖,可以做真实业务模型。
节奏较慢
项目仍在可用范围内,但最近活跃度不如主流 ORM,上线前要认真验证兼容性。
最佳实践
安装方式:python -m pip install pony==0.7.19
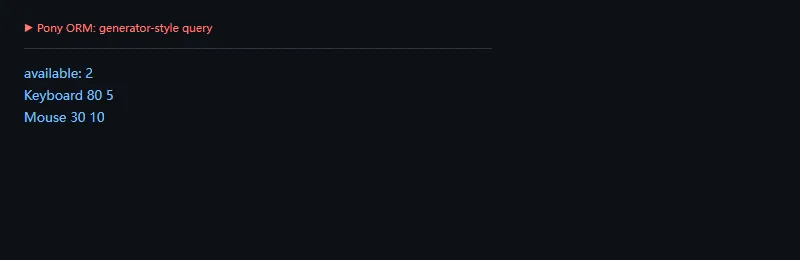
功能一:用生成器表达式查询
这段代码解决什么问题:定义商品实体,写入数据后,用 Pony 的生成器查询找出有库存的商品,并按价格排序。
frompony.ormimport*db=Database()classProduct(db.Entity):name=Required(str)price=Required(int)stock=Required(int,default=0)db.bind(provider="sqlite",filename=":memory:",create_db=True)db.generate_mapping(create_tables=True)withdb_session:Product(name="Keyboard",price=80,stock=5)Product(name="Mouse",price=30,stock=10)Product(name="Monitor",price=220,stock=0)items=select(pforpinProductifp.stock>0).order_by(desc(Product.price))print("available:",items.count())foriteminitems:print(item.name,item.price,item.stock)
这种查询写法的好处是直观,尤其是 Python 背景强、SQL 背景弱的团队,会更容易读懂查询意图。
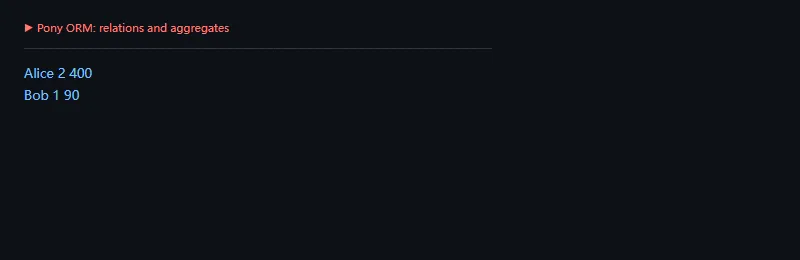
功能二:关系和聚合
这段代码解决什么问题:定义作者和书的一对多关系,然后用 Pony 查询按作者统计书籍数量和总页数。它展示了 Pony 在关系聚合上的表达方式。
frompony.ormimport*db=Database()classAuthor(db.Entity):name=Required(str)books=Set("Book")classBook(db.Entity):author=Required(Author)title=Required(str)pages=Required(int)db.bind(provider="sqlite",filename=":memory:",create_db=True)db.generate_mapping(create_tables=True)withdb_session:alice=Author(name="Alice")bob=Author(name="Bob")Book(author=alice,title="ORM Notes",pages=180)Book(author=alice,title="Query Guide",pages=220)Book(author=bob,title="SQLite Tips",pages=90)rows=select((a.name,count(a.books),sum(b.pagesforbina.books))forainAuthor).order_by(lambdaname,total,pages:desc(pages))forname,total,pagesinrows:print(name,total,pages)
这类写法很“Pony”,但也意味着团队需要熟悉它自己的查询规则。不要把 Python 生成器表达式和普通内存遍历完全混为一谈,最终仍然会落到 SQL。
环境与版本信息
- Demo 环境:Windows 11,Python 3.11
- 当前包未在 PyPI 元数据中声明
Requires-Python
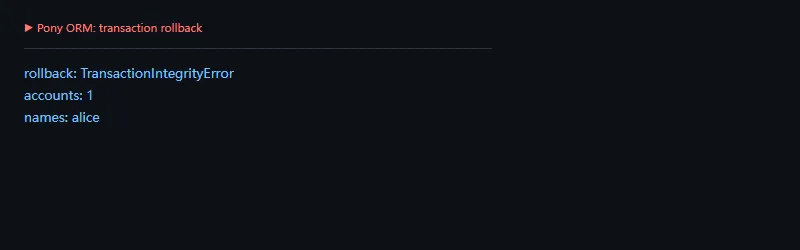
高级功能
这段代码解决什么问题:用唯一约束触发事务失败,确认第二次写入整体回滚。Pony 的 db_session 同时承担会话和事务边界,使用时要明确提交点。
frompony.ormimport*db=Database()classAccount(db.Entity):name=Required(str,unique=True)balance=Required(int,default=0)db.bind(provider="sqlite",filename=":memory:",create_db=True)db.generate_mapping(create_tables=True)try:withdb_session:Account(name="alice",balance=100)commit()withdb_session:Account(name="bob",balance=50)Account(name="alice",balance=200)commit()exceptExceptionasexc:print("rollback:",exc.__class__.__name__)withdb_session:print("accounts:",count(aforainAccount))print("names:",", ".join(a.nameforainselect(aforainAccount).order_by(Account.name)))
事务示例也提醒我们:越是语法看起来像普通 Python,越要记得背后仍然是数据库事务、约束和 SQL 执行计划。
适用场景
- 你喜欢用 Python 表达式描述查询,希望 ORM 语法更接近对象集合。
- 项目规模中小,数据库模型不算特别复杂,但需要关系和聚合。
- 团队愿意为 Pony 自己的查询风格做一轮学习和验证。
不适用场景
- 项目里已有 SQLAlchemy 或 Django ORM 规范,不想切换心智模型。
- 复杂 SQL、性能优化和数据库特性使用很重,需要更强的生态支撑。
上线检查
- 在目标 Python 和数据库版本下完整跑一轮集成测试。
- 对关键查询打开 SQL 日志,确认生成 SQL 符合预期。
- 团队先统一 Pony 查询风格,避免普通 Python 遍历和数据库查询边界混乱。
总结
Pony ORM 是一个风格很别致的 ORM。它最大的吸引力是 generator 查询语法,读起来很 Pythonic;但它也不是最主流路线。适合喜欢这种表达方式的团队试用,生产上则要多做兼容性和维护节奏评估。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
