大家好,我是你们的小帅学长,感谢关注!
如果你做的是回归、预测、反演、估算这一类任务,那么你几乎一定绕不开一张图:真值 vs 预测图(Observed vs Predicted)。
这张图在遥感、机器学习、生态、环境、医学、工程里都非常常见。
因为它回答的是一个最直接、也最核心的问题:模型预测出来的值,和真实值到底贴得有多近?
很多人也会画这张图,但常见问题是:
只会把点画出来,不知道为什么要加 1:1 线
指标写得乱,有的多有的少
图里信息很多,但结论不够清楚
看起来像“能交作业”,不像“能发论文”
所以这一篇,我想讲一下这张图:为什么要画、应该包含什么、怎么画得像论文图。
01.这张图到底在看什么?
真值 vs 预测图的核心,不是看“点漂不漂亮”,而是看:
整体贴合程度:预测值是否整体接近真值
系统偏差:模型有没有整体高估/低估
离散程度:点有没有大范围散开
异常区域:某些区间是否预测明显变差
02.为什么一定要加 1:1 线?
1:1 线表示什么?它表示:
也就是理想预测状态。
如果点全部落在这条线上,说明模型是完美的。
现实当然不会这样,但这条线给了我们一个非常清晰的参照系:
点在 1:1 线上方 → 模型高估
点在 1:1 线下方 → 模型低估
点越贴近 1:1 线 → 拟合越好
所以这张图里,1:1 线不是装饰,是基准。
03.指标框为什么要放?放哪些最合适?
只看散点位置,读者只能“感受”模型好不好;但科研图不能只靠感受,还要给出定量评价。这就是指标框的作用。
最常见、也最稳的一组指标
R²:拟合程度
RMSE:均方根误差,体现整体误差量级
MAE:平均绝对误差,更直观
Bias:系统偏差(高估 or 低估)
这四个指标组合在一起,基本已经足够支撑绝大多数论文情境。
为什么不要塞太多指标?因为图的任务是“让人快速判断模型质量”,不是把评价报告全贴上去。指标太多,读者反而抓不到重点。
一张论文图要做的是“提炼结论”,不是“堆满信息”。
04.这张图最容易踩的 4 个坑
1)横纵坐标范围不一致
如果 x 轴和 y 轴范围不一致,1:1 线就会失真,视觉判断会被误导。
所以这类图最重要的一条规范是:x 和 y 使用相同范围。
2)只画拟合线,不画 1:1 线
拟合线当然可以画,但拟合线不能替代 1:1 线。
拟合线反映的是“模型与数据的统计关系”。
1:1 线反映的是“模型是否理想”。
如果只画拟合线,不画 1:1 线,读者/审稿人很难一眼判断高估还是低估。
3)点太密,遮挡严重
当样本量大时,点会叠在一起。
解决方法很简单:
降低透明度 alpha
控制点大小 s
必要时用密度着色(后面可以进阶讲)
4)指标框位置挡住数据
指标框是辅助信息,不应该压住主要趋势。
建议放在图中“天然空白”的角落,比如左上或右下。
05.论文级 Python 示例代码
下面这段代码是一个完整、可复用的模板:
import osimport numpy as npimport matplotlib as mplimport matplotlib.pyplot as pltfrom matplotlib import font_manager as fmfrom matplotlib.ticker import MaxNLocatorfrom sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error# =========================# 字体设置:英文 Times New Roman + 中文 SimSun# =========================win_fonts = r"C:\Windows\Fonts"for p in [ os.path.join(win_fonts, "times.ttf"), os.path.join(win_fonts, "timesbd.ttf"), os.path.join(win_fonts, "timesi.ttf"), os.path.join(win_fonts, "simsun.ttc"),]: if os.path.exists(p): try: fm.fontManager.addfont(p) except Exception: passmpl.rcParams["font.family"] = ["Times New Roman", "SimSun"]mpl.rcParams["axes.unicode_minus"] = False# =========================# 输出路径# =========================OUT_DIR = r"D:\py_figs"os.makedirs(OUT_DIR, exist_ok=True)# =========================# 构造示例数据# =========================np.random.seed(42)y_true = np.random.uniform(280, 320, 500)y_pred = y_true + np.random.normal(0, 2.2, 500) + 0.4# =========================# 计算指标# =========================r2 = r2_score(y_true, y_pred)rmse = np.sqrt(mean_squared_error(y_true, y_pred))mae = mean_absolute_error(y_true, y_pred)bias = np.mean(y_pred - y_true)# =========================# 坐标范围统一# =========================xy_min = min(y_true.min(), y_pred.min())xy_max = max(y_true.max(), y_pred.max())pad = 1.5xy_min -= padxy_max += pad# =========================# 绘图# =========================fig, ax = plt.subplots(figsize=(5.8, 5.2))ax.scatter( y_true, y_pred, s=18, alpha=0.40, color="#4C78A8")ax.plot( [xy_min, xy_max], [xy_min, xy_max], linestyle="--", linewidth=1.6, color="red")ax.set_xlim(xy_min, xy_max)ax.set_ylim(xy_min, xy_max)ax.set_xlabel("True Value (K) / 真值", fontsize=12)ax.set_ylabel("Predicted Value (K) / 预测值", fontsize=12)ax.set_title("True vs Predicted / 真值与预测值", fontsize=14)ax.xaxis.set_major_locator(MaxNLocator(nbins=6))ax.yaxis.set_major_locator(MaxNLocator(nbins=6))metrics_text = ( f"$R^2$ = {r2:.4f}\n" f"RMSE = {rmse:.3f}\n" f"MAE = {mae:.3f}\n" f"Bias = {bias:.3f}")ax.text( 0.05, 0.95, metrics_text, transform=ax.transAxes, va="top", ha="left", fontsize=11, bbox=dict(boxstyle="round,pad=0.3", facecolor="white", edgecolor="black", alpha=0.9))for spine in ax.spines.values(): spine.set_linewidth(1.2)out_path = os.path.join(OUT_DIR, "true_vs_predicted.jpg")fig.savefig(out_path, dpi=300, bbox_inches="tight", pad_inches=0.05)plt.close(fig)print("Saved:", out_path)
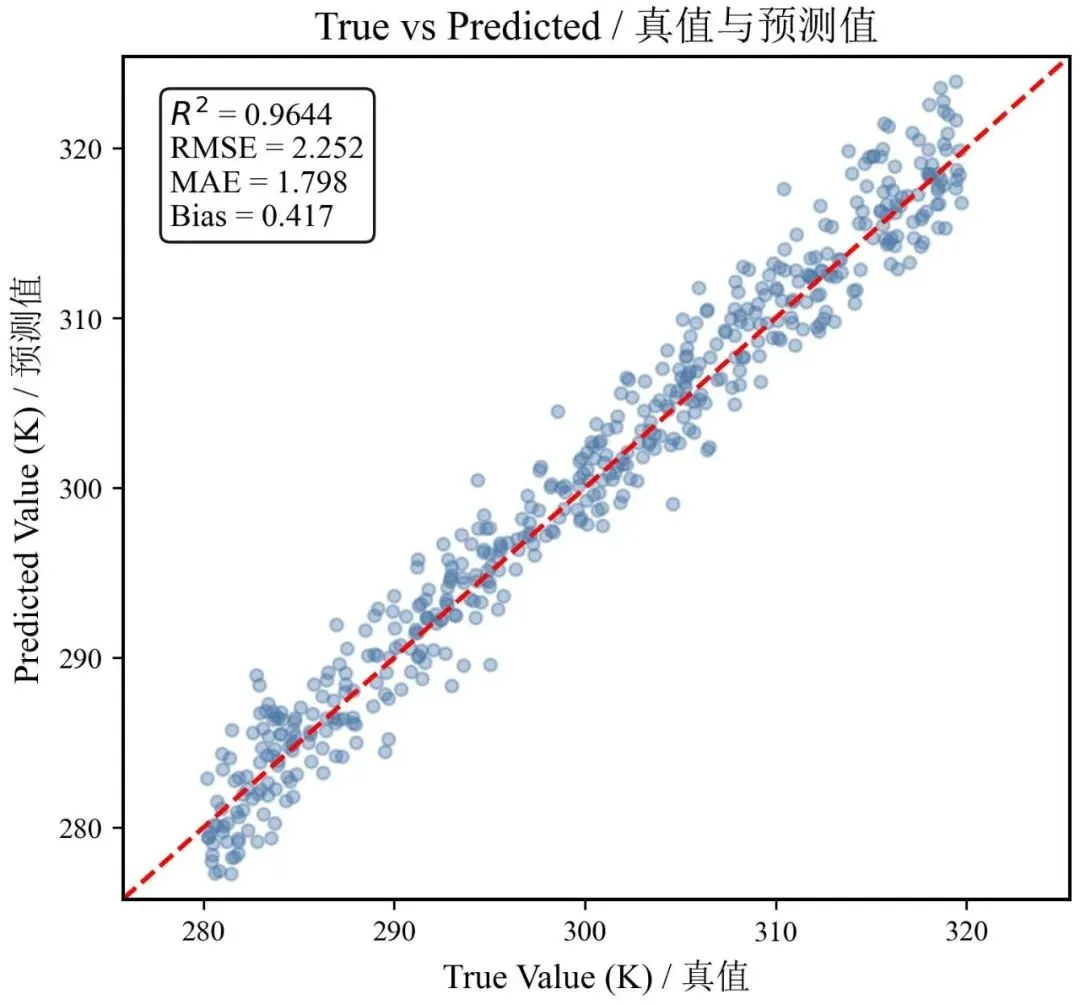
真值 vs 预测图的关键,不只是“点贴不贴线”,而是让读者/审稿人同时看到一致性、误差大小和系统偏差——1:1 线给出基准,指标框给出定量依据,这才是一张完整的评估图。
下一篇我们继续沿着“误差表达”往下讲,进入另一张非常关键的图:
《误差分布(直方 + KDE + Bias 线)》
它会告诉你模型误差是集中在 0 附近,还是存在明显偏移,是对称分布,还是偏态分布——也就是说,它不只告诉你“误差有多大”,还告诉你“误差长什么样”。
——期待你的关注——
往期内容:
用Python做科研级画图——相关矩阵热力图
用Python做科研级画图——残差图
用Python做科研级画图——回归拟合线
用Python做科研级画图——分组散点的编码策略
用Python做科研级画图——雨云图
用Python做科研级画图——小提琴图
用Python做科研级画图——异常值可视化
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
