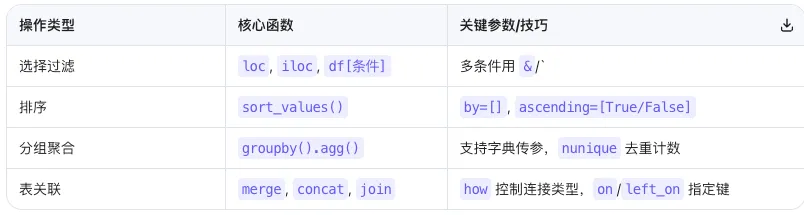
今天我们将深入 Pandas 的核心引擎——数据操作。无论是精准定位、条件过滤、多维排序,还是分组统计与多表关联,这 4 大模块将覆盖你 90% 的日常分析需求。数据选择与过滤
精准提取目标数据,是分析的第一步。Pandas 提供了三种主流定位方式: 1.按标签选择 (loc)
import pandas as pddf = pd.DataFrame({ 'Name': ['Alice', 'Bob', 'Charlie', 'David'], 'Age': [25, 30, 35, 40], 'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']})# 选单列 / 多列age_col = df['Age']name_age = df[['Name', 'Age']]# 按行索引 + 列名定位print(df.loc[1, 'Name']) # Bobprint(df.loc[1]) # 第2行完整数据
2.按位置选择 (iloc / iat)
# iloc 支持切片(行, 列)subset = df.iloc[0:2, 1:3] # 前2行,第2~3列# iat 专攻单个元素(性能更高)first_val = df.iat[0, 0] # Alice
口诀:loc 看名字,iloc 看序号,iat 取单值。
3.布尔索引(条件过滤)
# 单条件filtered = df[df['Age'] > 30]# 多条件(⚠️必须加括号,用 & 代替 and,| 代替 or)multi_filtered = df[(df['Age'] > 30) & (df['City'] == 'Chicago')]
数据排序
让数据按业务逻辑排列,洞察更直观。
# 单列排序(默认升序)sorted_age = df.sort_values(by='Age')# 降序排列sorted_desc = df.sort_values(by='Age', ascending=False)# 多列排序(先按城市升序,再按年龄降序)sorted_multi = df.sort_values(by=['City', 'Age'], ascending=[True, False])
数据分组与聚合 (GroupBy)
Pandas 的 groupby 遵循 “拆分-应用-合并” 范式,是透视分析的基石。
df_group = pd.DataFrame({ 'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'], 'Age': [25, 30, 35, 25, 30], 'City': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Chicago']})# 1. 分组grouped = df_group.groupby('City')# 2. 单函数聚合city_avg_age = grouped['Age'].mean()# 3. 多函数聚合 (agg)agg_res = grouped.agg({ 'Age': ['mean', 'max'], 'Name': 'count'})# 4. 多重聚合(去重计数 + 统计)multi_agg = df_group.groupby('Age').agg({ 'City': pd.Series.nunique, # 不同城市数量 'Name': 'count' # 该年龄段人数})
groupby 返回的是分组对象,必须接聚合函数(如 .mean(), .sum(), .agg())才会真
数据合并与连接
实际业务中,数据往往散落在多张表里。Pandas 提供了 3 种拼接策略:
函数 | 核心逻辑 | 适用场景 |
|---|
pd.merge()
| 基于列值匹配(类似 SQL JOIN) | 员工表+薪资表,通过 EmployeeID 关联 |
pd.concat()
| 基于轴向拼接(上下堆叠/左右并排) | 多个月份的流水表垂直合并 |
df.join()
| 基于索引匹配 | 已设置好 Index 的表快速关联 |
实战示例
# 1. merge (类SQL JOIN)df1 = pd.DataFrame({'ID': [1,2,3], 'Name': ['A','B','C']})df2 = pd.DataFrame({'ID': [2,3,4], 'Score': [85,90,78]})inner = pd.merge(df1, df2, on='ID', how='inner') # 仅保留匹配行left = pd.merge(df1, df2, on='ID', how='left') # 保留左表全部# 2. concat (垂直/水平拼接)df3 = pd.DataFrame({'Name': ['D','E'], 'Age': [28,32]})vertical = pd.concat([df1, df3], axis=0, ignore_index=True) # 上下拼接,重置索引# 3. join (基于索引)df_a = pd.DataFrame({'Dept': ['HR','IT']}, index=[1,2])df_b = pd.DataFrame({'Salary': [7000,8000]}, index=[1,3])joined = df_a.join(df_b, how='left') # 按索引左连接
核心避坑指南(实战必看)
综合实战
将今日知识点串联,建议直接复制运行(已清理原稿中的拼写误差):
import pandas as pdimport numpy as np# 1. 基础数据df = pd.DataFrame({ 'Name': ['Alice', 'Bob', 'Charlie', 'David'], 'Age': [25, 30, 35, 40], 'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']})# 2. 选择与过滤print("🔹 年龄>30的人员:\n", df[df['Age'] > 30])# 3. 排序print("\n🔹 按年龄降序:\n", df.sort_values('Age', ascending=False))# 4. 分组聚合df_g = pd.DataFrame({ 'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'], 'Age': [25, 30, 35, 25, 30], 'City': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Chicago']})print("\n🔹 各城市平均年龄:\n", df_g.groupby('City')['Age'].mean())# 5. 表合并df1 = pd.DataFrame({'ID': [1, 2, 3], 'Name': ['A', 'B', 'C']})df2 = pd.DataFrame({'ID': [2, 3, 4], 'Score': [85, 90, 78]})merged = pd.merge(df1, df2, on='ID', how='left')print("\n🔹 左连接结果:\n", merged)
今日知识点
【一起学Python】每天进步一点点,365天后遇见更优秀的自己!
👉 关注公众号,不错过每天的学习内容!
🎯 今日金句:
"数据的质量,决定分析的上限;清洗的耐心,成就洞察的深度。"