FastAPI 0.136.0 现已正式支持自由线程(free-threaded)Python。我做了一组基准测试,用来衡量它对 API 性能的实际影响。
测试分别在 Python 3.12(带 GIL)和 Python 3.13.0t(无 GIL)上运行,并使用 wrk 进行压力测试。
1. 什么是 GIL?为什么它很重要?
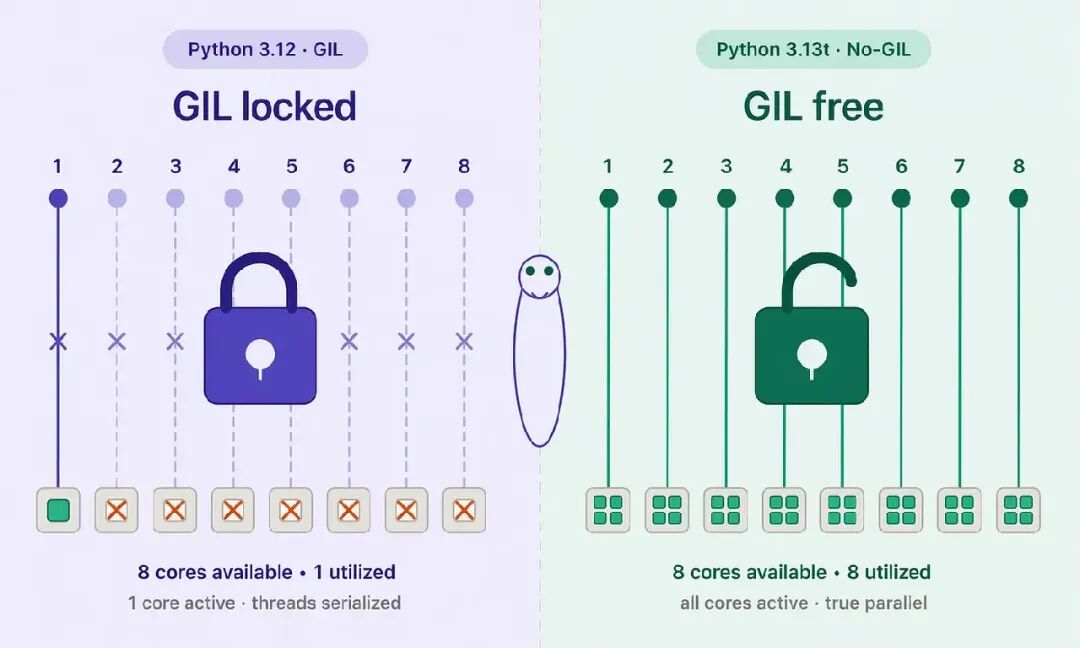
全局解释器锁(Global Interpreter Lock,GIL)是 CPython 中的一个互斥锁,它保证同一时间只有一个线程执行 Python 字节码。
对 I/O 密集型任务(例如等待数据库、HTTP 请求、文件读取),GIL 会被释放,因此线程之间可以很好地协作。
但对于 CPU 密集型任务,GIL 就成了性能上限:无论你启动多少线程,同一时间只能有一个线程真正运行。
自由线程 Python(3.13t)彻底移除了这把锁,使 Python 能够真正利用多个 CPU 核心并行执行。
2. 搭建实验环境
目标很简单:在两个不同的 Python 运行时中运行完全相同的代码,然后比较性能差异。
不修改任何代码,只更换 Python 解释器。
测试环境
所有基准测试均运行于:
MacBook M2(8 核 CPU,8 核 GPU)16GB RAM
运行如下命令安装uv,
curl -LsSf https://astral.sh/uv/install.sh | sh
运行如下命令安装wrk,
我是 macOS 系统,用 apt/dnf 在 Linux 下应该也能安装。
Step 1:创建项目
在项目根目录创建以下两个文件:
.python-version
pyproject.toml
[project]name = "fastapi-gil-benchmark"version = "0.1.0"description = "Benchmarking Python GIL vs free-threaded (No-GIL) performance with FastAPI"authors = []readme = "README.md"requires-python = ">=3.13,<3.14"dependencies = ["fastapi>=0.136.0", "uvicorn>=0.44.0"][dependency-groups]dev = []
.python-version 告诉 uv 自动使用自由线程版本的 Python,不需要手动切换 pyenv。
如果要测Python 3.12,可以用版本号 3.12.13,requires-python设置成 ">=3.12,<3.13"。
Step 2:安装依赖
uv 会读取 .python-version,如果本地还没有安装 3.13.0t,会
Step 3:验证 GIL 已关闭
uv run python -c "import sysconfig; print(sysconfig.get_config_var('Py_GIL_DISABLED'))"# 1
Step 4:创建 main.py
同一份代码同时运行于:
Python 3.12(带 GIL)
Python 3.13t(无 GIL)
包含四个接口:
同时覆盖线程版与顺序执行版。
"""FastAPI GIL vs No-GIL benchmark"""from fastapi import FastAPIimport timeimport threadingapp = FastAPI()def cpu_heavy_task(n: int): total = 0 for i in range(n): total += i * i return totaldef io_task(): time.sleep(2) # 模拟阻塞 I/O@app.get("/")def root(): return {"message": "GIL vs No-GIL Demo API"}@app.get("/cpu-thread")def cpu_thread(): start = time.time() threads = [] for _ in range(2): t = threading.Thread(target=cpu_heavy_task, args=(2_000_000,)) threads.append(t) t.start() for t in threads: t.join() return { "type": "CPU-bound (threads)", "time_taken": round(time.time() - start, 2), }@app.get("/cpu-seq")def cpu_seq(): start = time.time() cpu_heavy_task(2_000_000) cpu_heavy_task(2_000_000) return { "type": "CPU sequential", "time_taken": round(time.time() - start, 2), }@app.get("/io-thread")def io_thread(): start = time.time() threads = [] for _ in range(2): t = threading.Thread(target=io_task) threads.append(t) t.start() for t in threads: t.join() return { "type": "IO-bound (threads)", "time_taken": round(time.time() - start, 2), }@app.get("/io-seq")def io_seq(): start = time.time() io_task() io_task() return { "type": "IO sequential", "time_taken": round(time.time() - start, 2), }
Step 5:启动服务
务必只使用单 worker。
多个 worker 会启动多个独立进程,从而绕过 GIL,这样测试就失去了意义。
uv run uvicorn main:app --workers 1 --host 0.0.0.0 --port 8000
Step 6:压测
wrk -t4 -c20 -d30s http://localhost:8000/cpu-threadwrk -t4 -c20 -d30s http://localhost:8000/cpu-seqwrk -t4 -c20 -d30s http://localhost:8000/io-threadwrk -t4 -c20 -d30s http://localhost:8000/io-seq
参数含义:
服务器端的 --workers 1 非常关键。
否则你测到的是多进程性能,而不是 GIL 的影响。
3. 测试结果
4. 这些数字真正说明了什么
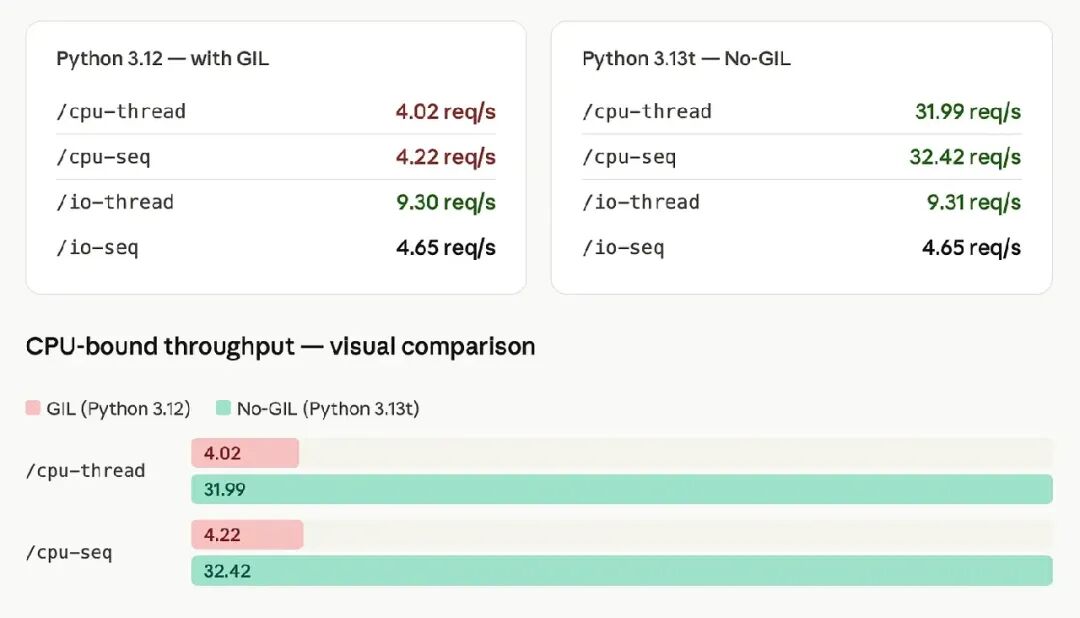
1)CPU 性能:提升约 8 倍
这是最核心的结果。
CPU 密集型接口的吞吐量从大约:
提升到
大约提升了 8 倍。
没有修改任何代码,只是换了一个 Python 解释器。
这正是自由线程所承诺的能力:
多个请求现在能够真正并行运行在多个 CPU 核心上,而不是排队等待。
2)令人意外的一点:请求内部使用线程依然没什么帮助
无 GIL 下的 CPU 测试结果:
/cpu-thread → 31.99 RPS(几乎与顺序版相同)/cpu-seq → 32.42 RPS(基线)
即便移除了 GIL,在单个请求内部手动创建线程,也没有带来性能提升。很多人会对此感到意外。原因在于当并发连接达到 20 时,CPU 已经被“请求级并行”完全占满。此时在单个请求内部再创建线程,只会增加调度开销。
无 GIL 真正提升的是“请求之间”的并行能力,多个请求现在可以真正同时执行。在高负载下,单个 endpoint 继续加线程,带来的更多是开销,而不是吞吐量。
3)I/O 密集型:几乎没有变化
I/O 测试在两个运行时中的结果几乎完全一致。
因为 GIL 从来都不是这里的瓶颈。
在阻塞 I/O 操作期间,GIL 本来就会释放。
如果你的 FastAPI 应用主要是:
那么自由线程基本不会带来明显收益。
I/O 测试结果:
/io-thread → 9.30 RPS(GIL)vs 9.31 RPS(No-GIL)几乎无变化/io-seq → 4.65 RPS(GIL)vs 4.65 RPS(No-GIL)完全无变化
5. 结论
自由线程 Python 真正有帮助的场景
没什么帮助的场景
需要注意的事情
这次实验最有意思的一点在于:同样的代码、同样的 endpoint、同样的 benchmark 命令,仅仅换了一个 Python 二进制版本,CPU 吞吐量就提升了 8 倍。
FastAPI 0.136.0 已正式支持自由线程 Python,这意味着它不再只是实验特性,而是真正可用于 CPU 密集型场景的现实选择。
参考
https://medium.com/@kevaldekivadiya2415/python-gil-vs-no-gil-real-fastapi-benchmarks-with-free-threaded-python-3-13-b5751f8d57a2