完整代码获取回复“分组散点回归”即可获得通道
不同配色效果展示:
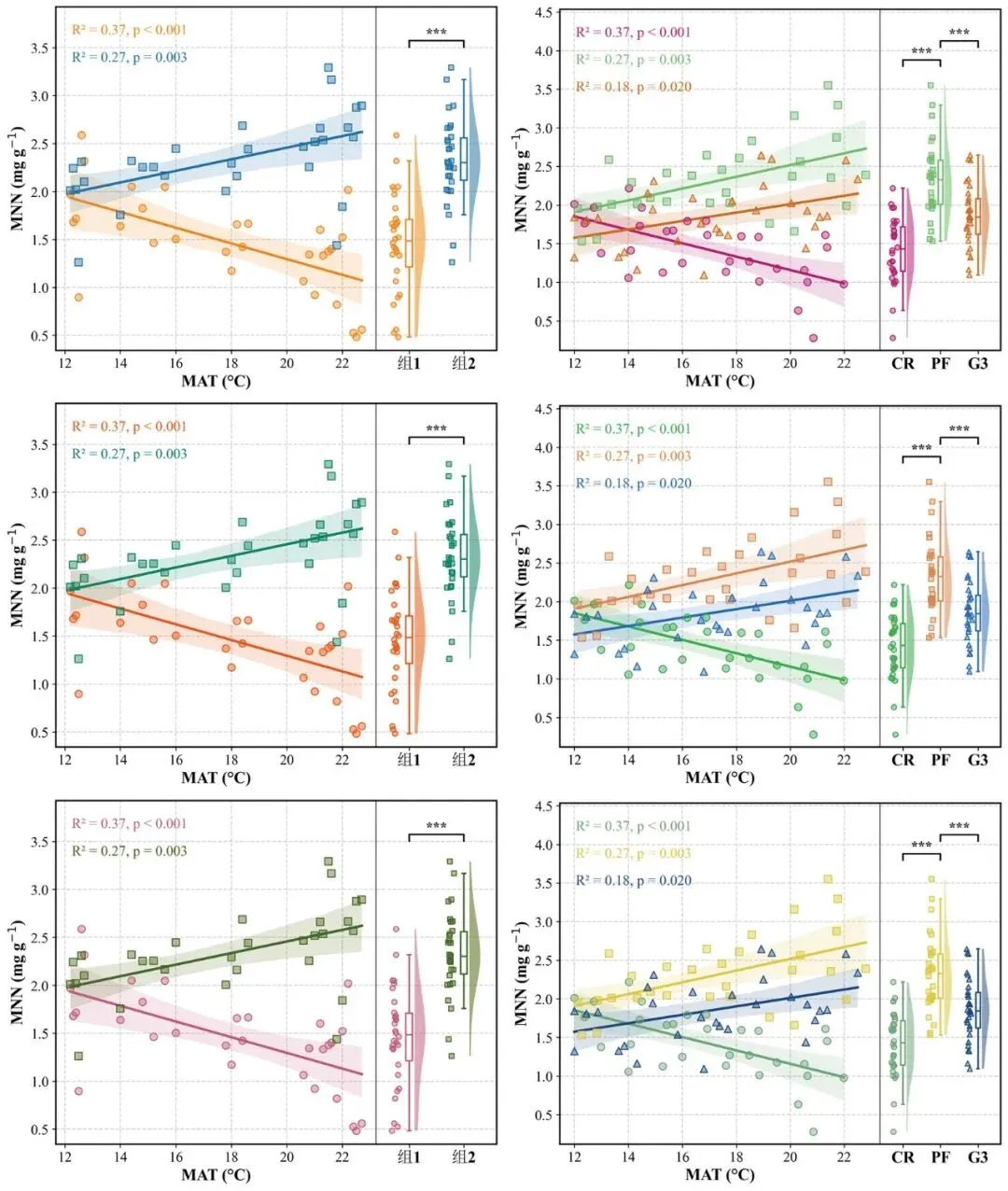
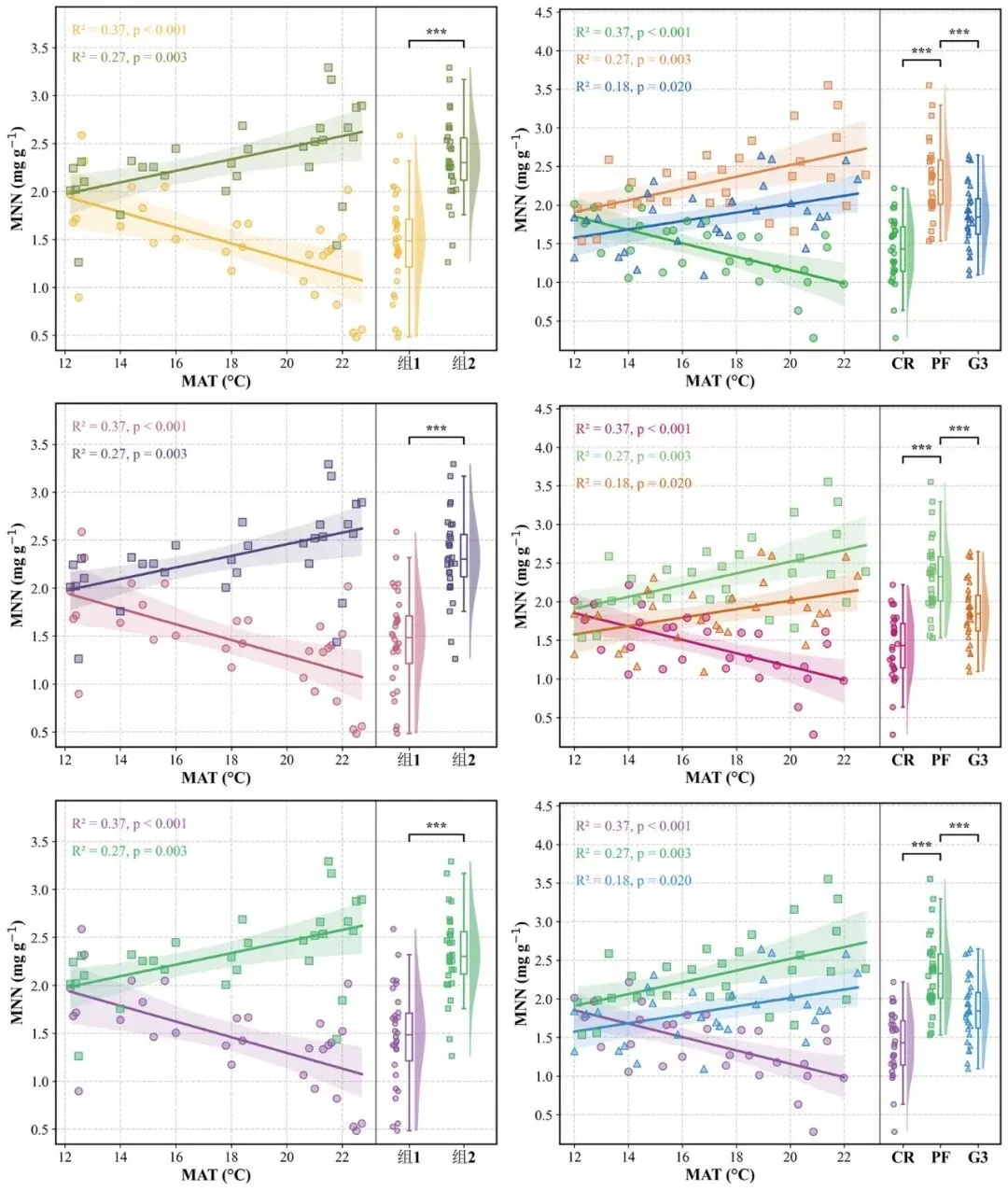
一、代码功能简介
本代码用于绘制一种常见的分组散点回归图+小提琴箱线散点组合图,适合展示连续型变量之间的相关关系以及不同分组之间的数值分布差异。
该图主要由两部分组成:
1.左侧散点回归图
用于展示不同分组中,x轴变量 与 y轴变量 之间的线性关系。每个分组使用不同颜色和点形表示,同时绘制对应的线性回归拟合线、95%置信区间,并自动计算和标注每组的 R2
和 p 值。
2.右侧分布比较图
用于展示不同分组中 y轴变量 的分布情况。右侧图综合了小提琴图、箱线图和散点图,同时对相邻分组进行独立样本 t 检验,并用 ns、*、**、*** 标注显著性水平。
整体上,该代码适合用于复刻类似下面类型的科研图:
分组散点回归图 + 半小提琴图 + 箱线图 + 原始散点 + 显著性标记
二、适用数据类型
该代码适合处理 Excel 表格数据。每一行代表一个样本,每一列代表一个变量。
按照当前代码设置,Excel 表格中至少需要包含以下三列:
列位置 | 代码索引 | 含义 | 示例 |
第1列 | 0
| y轴变量 | MNN (mg g^-1)
|
第2列 | 1
| x轴变量 | MAT (°C)
|
第3列 | 2
| 分组变量 | CR / PF / G3
|
当前代码中,Y_COL_INDEX = 0 表示第1列作为 y 轴,X_COL_INDEX = 1 表示第2列作为 x 轴,GROUP_COL_INDEX = 2 表示第3列作为分组列。
示范数据如下:
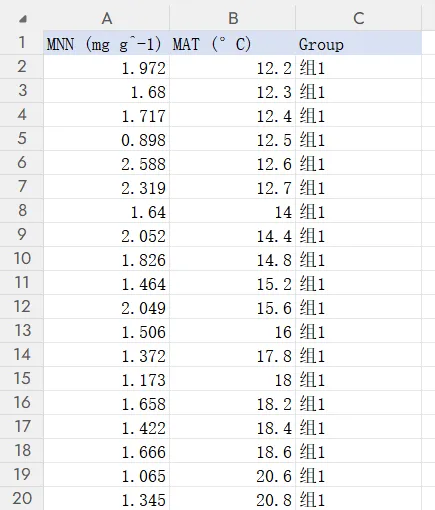
其中:
第一列是 y轴指标;
第二列是 x轴指标;
第三列是 分组变量;
分组名称可以是组1、组2、组3,也可以改成自己的实验组名称。
三、图形整体介绍
该图是一类用于同时展示变量相关关系与组间分布差异的组合图。整体图形通常由左侧的分组散点回归图和右侧的分组分布比较图构成。左侧图主要用于分析连续型自变量与因变量之间的关系,右侧图主要用于比较不同组别中因变量的总体分布特征。该类图形的优势在于能够在同一张图中同时呈现两个层面的信息:一方面,可以观察因变量是否随自变量变化而发生规律性改变;另一方面,可以比较不同实验组、处理组或分类组之间因变量水平是否存在差异。由于左右两部分通常共享同一个纵坐标,因此读者可以在统一数值尺度下同时理解变量关系和组间差异。
四、坐标轴元素
1. 纵坐标
纵坐标表示研究中的目标响应变量,也就是图中主要关注的因变量。该变量可以是某种含量、浓度、丰度、活性、评分、比例或其他定量指标。纵坐标标题通常包含变量名称及其单位,用于说明所有散点、箱线图和小提琴图所对应的数值含义。在解读时,首先应明确纵坐标代表什么指标,以及该指标数值升高或降低在研究背景中的实际意义。纵坐标数值越高,通常表示目标指标水平越高;纵坐标数值越低,则表示目标指标水平较低。
2. 左侧横坐标
左侧横坐标表示连续型解释变量或环境梯度变量,例如温度、时间、浓度、剂量、距离、年龄、pH、降水量等。该变量用于分析因变量随自变量变化的响应趋势。在解读时,应关注散点是否随着横坐标增加而整体上升或下降。如果散点整体上升,说明自变量增加时,因变量可能呈增加趋势;如果散点整体下降,则说明自变量增加时,因变量可能呈降低趋势。
3. 右侧横坐标
右侧横坐标表示不同分组,例如对照组、处理组、不同类型、不同区域或不同实验条件。右侧图通过将各组数据并列展示,用于比较不同组别中因变量的分布水平和变异特征。在解读时,应重点比较各组在纵坐标方向上的整体高低、分布范围和中位数位置。
五、左侧散点元素
1. 单个散点的含义
左侧图中的每一个散点代表一个独立样本或观测值。散点在横坐标上的位置表示该样本对应的自变量数值,散点在纵坐标上的位置表示该样本对应的因变量数值。因此,散点图能够直观展示每个样本在两个变量维度上的分布状态。通过观察散点的分布方向和密集程度,可以初步判断变量之间是否存在相关趋势。
2. 散点颜色与形状
不同颜色或不同点形通常用于区分不同组别。每一种颜色或点形代表一个实验组、处理组或分类组。如果不同组别的散点在图中分布区域明显不同,说明不同组别在自变量或因变量水平上可能存在差异。如果不同组别的散点高度重叠,则说明组间差异可能较小,或不同组别在该变量空间中的分布相似。
3. 散点离散程度
散点的离散程度反映样本之间的变异性。若某一组散点较为集中,说明该组内部样本差异较小,数据稳定性较高;若散点分布较为分散,说明该组内部差异较大,可能存在较强个体差异、环境异质性或其他未控制因素影响。如果图中出现明显偏离整体趋势的点,应注意是否存在异常值、极端值或具有特殊生物学意义的样本。
六、回归线元素
1. 回归线的含义
左侧图中的实线通常表示对某一组数据进行线性回归后得到的拟合趋势线。回归线用于概括该组中自变量与因变量之间的总体变化方向。回归线并不代表每一个样本的真实值,而是对样本整体趋势的统计概括。
2. 回归线斜率方向
回归线斜率是解读该图的关键元素之一。当回归线向右上方倾斜时,说明自变量增加时,因变量整体呈增加趋势,即二者可能呈正相关关系。当回归线向右下方倾斜时,说明自变量增加时,因变量整体呈降低趋势,即二者可能呈负相关关系。当回归线接近水平时,说明因变量随自变量变化的趋势较弱,二者之间可能不存在明显线性关系。
3. 不同组别回归线的比较
如果不同组别的回归线斜率方向一致,说明各组中因变量对自变量的响应方向相似。如果不同组别的回归线斜率大小不同,说明各组的响应强度可能不同。如果不同组别的回归线斜率方向相反,则说明组别因素可能改变了自变量与因变量之间的关系方向。这种情况在论文中具有较高解释价值,因为它提示不同组别下变量关系并不一致,可能存在组别因素的调节作用或交互效应。
七、置信区间阴影元素
1. 置信区间的含义
回归线周围的浅色阴影通常表示回归拟合线的置信区间,常见为 95% 置信区间。置信区间用于表示回归趋势估计的不确定性。
2. 阴影宽窄的解释
如果置信区间较窄,说明回归线估计相对稳定,样本点围绕拟合线的波动较小。如果置信区间较宽,说明该区域内回归估计不确定性较高,可能与样本量较少、数据离散程度较大或极端值影响有关。
3. 组间置信区间的比较
如果不同组别的置信区间明显分离,说明组间趋势差异可能较为明显。如果不同组别的置信区间大范围重叠,则说明组间趋势差异需要谨慎解释,不能仅凭回归线表面差异作出过强结论。
八、回归统计量元素
1. R2的含义
图中标注的 R2表示决定系数,用于衡量自变量对因变量变异的解释程度。R2的取值越大,说明自变量能够解释因变量变化的比例越高;R2越小,说明因变量的变化可能更多受到其他因素影响。例如,若 R2=0.30,通常可以理解为该自变量能够解释因变量约 30% 的变异。
2. p 值的含义
p 值用于判断回归关系是否具有统计学显著性。若 p 值小于预设显著性水平,通常认为自变量与因变量之间存在显著线性关系。常见判断标准为:p < 0.05 表示差异或相关关系具有统计学意义;p < 0.01 表示具有较强统计学意义;p < 0.001 表示具有极显著统计学意义。
3. 统计量解读注意事项
R2和 p 值反映的是统计相关关系,而不是因果关系。即使回归关系显著,也不能单独证明自变量导致因变量变化。因此,在博士论文写作中,应使用“呈显著相关”“与……相关”“随……变化呈增加或降低趋势”等表述,避免直接使用“导致”“决定”“引起”等因果化措辞。
九、右侧原始散点元素
1. 原始散点的含义
右侧分布图中的每一个散点同样代表一个独立样本或观测值。散点的纵向位置表示该样本的因变量数值,横向位置表示其所属组别。右侧散点的作用是展示原始数据分布,使读者能够看到每个样本的真实数值,而不仅仅依赖箱线图或小提琴图等统计摘要。
2. 散点抖动的作用
右侧散点通常会在水平方向上进行轻微随机偏移,这种处理称为抖动。其目的是避免多个样本点完全重叠,从而更清楚地展示样本数量和分布密度。这种横向偏移不代表真实的数值差异,只是为了增强图形可读性。
十、箱线图元素
1. 箱线图的基本含义
右侧图中的箱线图用于概括各组因变量的集中趋势和离散程度。它是一种常见的统计摘要图形,能够快速反映每组数据的中位数、四分位数和主要波动范围。
2. 箱体中位数
箱体中间的横线通常表示中位数。中位数越高,说明该组因变量的中心水平越高;中位数越低,说明该组因变量的中心水平越低。在组间比较时,中位数的位置是判断不同组别总体水平差异的重要依据。
3. 箱体上下边界
箱体上下边界通常表示第一四分位数和第三四分位数,也就是中间 50% 样本的分布范围。箱体越高,说明该组数据离散程度越大;箱体越矮,说明该组数据分布越集中。
4. 须线
箱体上下延伸的须线表示数据的主要波动范围。须线较长说明该组样本值跨度较大,组内差异明显;须线较短则说明样本值较为集中。
十一、小提琴图元素
1. 小提琴图的含义
小提琴图用于展示各组数据的概率密度分布。它不仅能反映数据的高低水平,还可以显示数据在不同数值范围内的集中程度。在组合图中,小提琴图通常与箱线图和散点图结合使用,用于同时展示数据分布形态、统计摘要和原始样本值。
2. 小提琴图宽度的解释
在某一纵坐标位置处,小提琴图越宽,说明该数值附近样本越多;小提琴图越窄,说明该数值附近样本较少。因此,小提琴图可以帮助判断数据是否集中在某一数值范围,是否存在偏态分布,或者是否具有多个峰值。
3. 半小提琴图的作用
如果图中只显示小提琴图的一半,则称为半小提琴图。半小提琴图常用于和箱线图、散点图组合展示,可以减少图形拥挤,同时保留数据密度分布信息。
十二、显著性标记元素
1. 显著性横线
右侧图顶部的横线通常表示正在进行统计比较的两个组别。横线连接的组别即为参与显著性检验的对象。如果图中有多个横线,则表示进行了多组之间的两两比较或特定比较。
2. 星号标记
横线上方的星号表示组间差异的显著性水平。常见标记方式为:ns 表示差异不显著;* 表示 p < 0.05;** 表示 p < 0.01;*** 表示 p < 0.001。星号越多,表示统计学显著性越强。
3. 显著性解释注意事项
显著性标记只能说明组间差异是否达到统计学显著水平,并不能直接说明差异的实际大小、机制原因或生物学意义。因此,在解读时还需要结合箱线图位置、散点分布、小提琴图密度、样本量以及研究背景综合判断。
十三、例图解读:
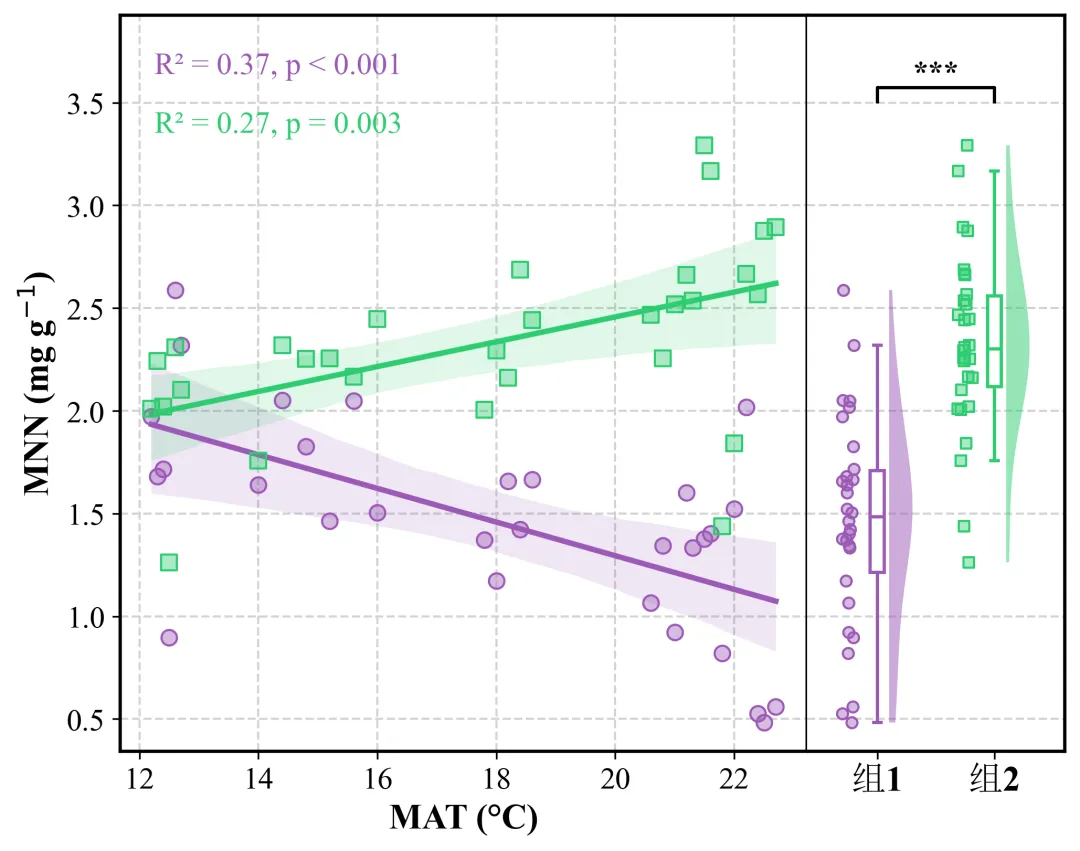
如图所示,该图综合展示了不同组别中 MNN 含量与 MAT 之间的关系,以及不同组别间 MNN 含量的总体分布差异。整幅图由左侧的分组散点回归图和右侧的组间分布比较图构成,能够同时反映连续环境因子与目标指标之间的相关关系,以及不同组别之间目标指标水平的差异特征。
左侧散点回归图以 MAT 为横坐标,以 MNN 含量为纵坐标,分别展示了组1和组2中 MNN 随 MAT 变化的趋势。图中每一个散点代表一个独立样本,不同颜色和点形用于区分不同组别。其中,组1以紫色圆点表示,组2以绿色方形表示。两组数据分别进行了线性回归拟合,实线表示拟合趋势线,浅色阴影表示回归线的 95% 置信区间。
从回归趋势来看,组1和组2中 MNN 对 MAT 的响应方向存在明显差异。组1中,MNN 与 MAT 呈显著负相关关系,随着 MAT 升高,MNN 含量整体呈下降趋势。线性回归结果显示,组1的决定系数为 R2=0.37,且 p<0.001,说明 MAT 能够解释组1中 MNN 变异的约 37%,且该相关关系具有极显著统计学意义。该结果表明,在组1条件下,较高的 MAT 与较低的 MNN 含量密切相关,提示该组中 MNN 的积累或保存过程可能对温度升高较为敏感。
与组1相反,组2中 MNN 与 MAT 呈显著正相关关系。随着 MAT 升高,组2中 MNN 含量整体呈增加趋势。回归结果显示,组2的决定系数为 R2=0.27,p=0.003,表明 MAT 可以解释组2中 MNN 变异的约 27%,且该正相关关系达到显著水平。该结果说明,在组2条件下,较高的 MAT 与较高的 MNN 含量相关,提示温度升高可能与组2中 MNN 的形成、积累或稳定保存过程存在正向联系。
值得注意的是,两组回归线的斜率方向相反,说明 MNN 对 MAT 的响应并非具有统一方向,而是受到组别因素的调节。换言之,同样是 MAT 升高,在组1中表现为 MNN 降低,而在组2中则表现为 MNN 升高。这一结果提示,组别因素可能改变了 MAT 与 MNN 之间的关系方向,表明二者之间可能存在潜在的交互效应。若从博士论文结果阐释的角度来看,这一发现不仅说明 MAT 是影响 MNN 变化的重要环境因子,也进一步表明不同组别背景下 MNN 对温度变化的响应机制可能存在差异。
右侧分布图进一步展示了组1和组2中 MNN 含量的总体分布特征。该部分由原始散点、箱线图和半小提琴图共同构成。原始散点展示了每个样本的实际 MNN 数值,箱线图反映了各组数据的中位数、四分位数及离散程度,半小提琴图则用于展示数据的密度分布情况。通过这种组合方式,可以较为直观地观察不同组别中 MNN 的集中趋势、离散程度和样本分布形态。
从右侧分布图可以看出,组2的 MNN 含量整体高于组1。组1样本主要分布在较低的 MNN 范围内,而组2样本则更多集中于较高的 MNN 水平。箱线图结果显示,组2的中位数明显高于组1,且其整体分布区间相对上移。半小提琴图也显示,组2的主要分布密度集中在较高 MNN 值附近,而组1的分布中心则相对较低。这些结果共同表明,组2具有更高的 MNN 基础水平。
右侧图顶部的显著性标记显示,组1与组2之间的 MNN 含量差异达到极显著水平,通常表示 p<0.001。因此,从组间比较结果来看,组2的 MNN 含量显著高于组1。该结果说明,除 MAT 的影响外,组别因素本身也可能对 MNN 的水平具有显著影响。
综合左侧相关性分析和右侧组间比较结果可以发现,MNN 的变化同时受到 MAT 和组别因素的共同影响。一方面,MAT 与 MNN 在两个组别中均存在显著相关关系,说明温度条件可能是影响 MNN 变化的重要环境因子;另一方面,不同组别中 MAT 与 MNN 的相关方向相反,并且组2的 MNN 含量显著高于组1,说明组别因素不仅影响 MNN 的总体水平,还可能改变 MNN 对 MAT 的响应方向。这一结果提示,在解释 MNN 变化机制时,不能仅考虑 MAT 的单一影响,还应进一步关注组别背景及其与 MAT 之间的潜在交互作用。
十四.Python 绘图代码完整操作步骤
1. 下载 Python
首先需要在电脑中安装 Python。建议使用 Python 3.11 ~3.13的稳定版本。
打开浏览器,进入 Python 官方网站,下载适合自己电脑系统的安装包。安装教程可根据电脑配置网上查找教程。
2.安装代码编辑器
这段代码可以在多种编辑器中运行,例如:VS Code、PyCharm、Jupyter Notebook、Anaconda Spyder等。对于初学者,推荐使用 PyCharm 或 VS Code。如果你只是运行这一类科研绘图代码,PyCharm 更适合直接管理项目和运行脚本;如果你后续还需要写很多不同类型代码,VS Code 更轻量。大家可根据自己的需求安装,网上自行查找安装教程。安装好之后需要再编辑器中配置Python环境,不同的编辑器配置方法不同,可根据自己的编辑器查找相关教程。
3.创建项目文件夹
新建一个项目文件夹,这个文件夹之后用来存放,文件夹包含Python代码文件、Excel数据文件,所有相关文件都放在同一个文件夹中,方便代码读取和输出。
4.使用Python编辑器打开代码文件
5.安装代码所需库
运行代码前需要在终端安装代码用到的库,直接在终端、命令提示符或 PyCharm 终端中运行,安装代码为:pip install pandas numpy matplotlib seaborn scipy openpyxl
如果你用的是 Anaconda,也可以用:conda install pandas numpy matplotlib seaborn scipy openpyxl
6.代码运行
如果你的 Excel 文件名不是示范数据.xlsx。而是其他命名,需要将代码中的EXCEL_FILE_PATH = "示范数据.xlsx"。双引号内的示范数据修改为您的Excel文件名。替换好之后点击运行即可。
代码可自行修改字体大小、颜色等风格配置
完整代码获取回复“分组散点回归”即可获得通道
代码运行问题可添加微信详细咨询:zhouysh001(八宝粥加油)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
