从笔者一开始接触CST仿真的时候就知道它可以通过VBA以及Python进行联用,但是一直不知道怎么做。在仿真过程中,随着仿真数量的增多,如果仿真数量达到几百甚至上千,或者好几千的时候,导出S参数是一个比较困难的事情,一部分一部分导出又太过费时间,而且文件太大,容易崩溃。
最近,笔者走通了一条使用Python代码导出CST仿真S参数结果的一个方法,这个方法对于电脑配置没有要求,非常好用:
笔者首先使用的CST版本是2025版本,别的版本应该差不多,右键仿真图标,打开文件位置,笔者位置如下
C:\Program Files (x86)\CST Studio Suite 2025\AMD64
在这个文件夹里面找到python.bat
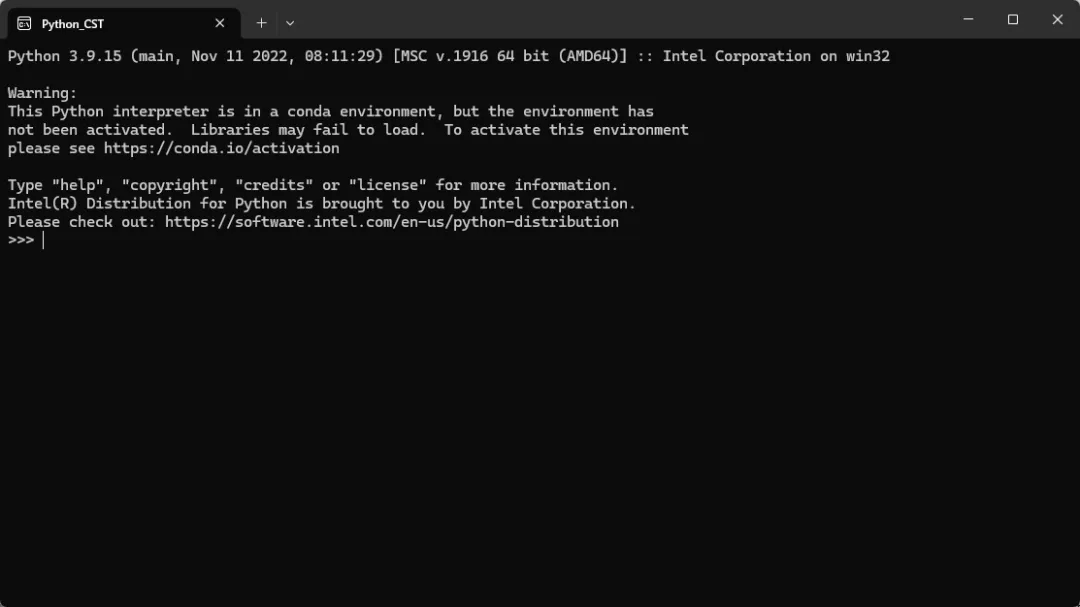
这是一个批处理脚本,就是打开自带的python软件,打开之后如下界面
对于想知道自己python位置的,以及想要知道工作位置等信息的,可以复制下面信息到这个对话框import sys, os
print(f"Python版本: {sys.version[:10]}")
print(f"解释器位置: {sys.executable}")
print(f"安装根目录: {sys.prefix}")
print(f"当前工作目录: {os.getcwd()}")
这五行代码,其中第一行需要解释一下,就是python这个相当于是一个工匠,可以做很多事,但是没有工具箱不行,做铁匠就要用到铁匠工具箱,做木匠就要用到木匠工具箱,所以import这一步就是导入后面需要的工具箱,所以很多python代码都需要import,因为python没有工作去,也不会保存上一次导入的工具,所以每一次运行代码都需要导入工具箱。上面这五行就是让你知道自己的python在哪的
同时,不同版本的python还需要确定一下就是自己depython有没有链接到CST,所以可以用如下代码确认一下
import cst
print(cst.__file__) # should print '<PATH_TO_CST_AMD64>\python_cst_libraries\cst\__init__.py'
这个是官方介绍的,验证方法
正常的就会显示自己的CST安装位置了
然后,我们确定之后,现在,处于python已经运行的环境中,然后,我们需要准备好的就是已经仿真好的文件,假如我们要导出的就是S11,在CST里面的导航树是
"1D Results\S-Parameters\SZmax(1),Zmax(1)"
那么,我们就可以使用下面的代码
'''牛逼,完美运行,可以提取cst中文件的S参数,提取文件数据结构没毛病,但是需要使用cst自己的python运行'''
importsys
importos
importcst.results
import numpy as np
import pandas as pd
# ============================================================
# 配置区域 - 请根据你的实际情况修改以下路径
# ============================================================
cst_file_path=r"F:\test.cst"
output_csv_path=r"F:\S11__ParametricSweep_Results.csv"
output_excel_path=r"F:\S11_circle_ParametricSweep_Results.xlsx"
# ============================================================
# 打开 CST 项目文件(不打开 CST 界面,后台读取)
# ============================================================
print("正在打开 CST 项目文件...")
project=cst.results.ProjectFile(cst_file_path)
results_3d=project.get_3d()
# ============================================================
# Step 1: 获取所有 run_ids(参数化扫描编号)
# ============================================================
# 文档说明:get_all_run_ids() 获取所有存在的 run ids
# run_id=0 是 Current Run,参数化扫描结果从 1 开始
print("正在获取参数化扫描的 run_ids...")
all_run_ids=results_3d.get_all_run_ids()
print(f"所有 run_ids: {all_run_ids}")
# 过滤掉 run_id=0(Current Run),只保留参数化扫描结果
parametric_run_ids= [ridforridinall_run_idsifrid!=0]
num_runs=len(parametric_run_ids)
ifnum_runs==0:
print("未找到任何参数化扫描结果,请检查:")
print(" 1. 文件路径是否正确")
print(" 2. 是否已经运行过参数化扫描")
exit()
print(f"参数化扫描结果数量: {num_runs} 个(run_ids = {parametric_run_ids})")
# ============================================================
# Step 2: 读取第 1 个结果获取频率信息和标签
# ============================================================
first_run_id=parametric_run_ids[0]
first_result=results_3d.get_result_item(
r"1D Results\S-Parameters\SZmax(1),Zmax(1)",
run_id=first_run_id
)
freqs=np.array(first_result.get_xdata())
xlabel=first_result.xlabel
ylabel=first_result.ylabel
n_freq=len(freqs)
print(f"\n===== 数据信息 =====")
print(f"X轴标签: {xlabel}")
print(f"Y轴标签: {ylabel}")
print(f"频率点数: {n_freq}")
# 尝试获取频率范围
iffreqs.max() >1e9:
print(f"频率范围: {freqs[0]/1e9:.4f} ~ {freqs[-1]/1e9:.4f} GHz")
eliffreqs.max() >1e6:
print(f"频率范围: {freqs[0]/1e6:.4f} ~ {freqs[-1]/1e6:.4f} MHz")
else:
print(f"频率范围: {freqs[0]:.4f} ~ {freqs[-1]:.4f} Hz")
# ============================================================
# Step 3: 获取参数化扫描的参数信息
# ============================================================
# 文档 Example 3 说明:ResultModule.get_parameter_combination(run_id)
# 返回一个字典,包含参数名称和值
print(f"\n===== 正在获取参数化参数信息 =====")
# 先获取第一个 run_id 的参数组合,提取参数名称
first_params=results_3d.get_parameter_combination(first_run_id)
param_names=list(first_params.keys())
print(f"参数化参数名称: {param_names}")
print(f"第 {first_run_id} 个参数组合: {first_params}")
# 收集所有 run_id 的参数值
all_param_values= {}
forridinparametric_run_ids:
params=results_3d.get_parameter_combination(rid)
all_param_values[rid] =params
print(f"成功获取 {len(all_param_values)} 个参数组合")
# ============================================================
# Step 4: 循环读取所有参数化扫描的 S11 结果
# ============================================================
print(f"\n===== 开始读取所有参数化扫描的 S11 结果 =====")
all_results= [] # 存储所有结果
foridx, run_idinenumerate(parametric_run_ids):
try:
# 读取当前 run_id 的 S11 结果
result=results_3d.get_result_item(
r"1D Results\S-Parameters\SZmax(1),Zmax(1)",
run_id=run_id
)
s11_complex=np.array(result.get_ydata()) # 复数 S11 数据
# 计算各种格式的 S11
s11_real=np.real(s11_complex)
s11_imag=np.imag(s11_complex)
s11_mag=np.abs(s11_complex)
s11_db=20*np.log10(s11_mag+1e-20) # 加极小值防止 log(0)
s11_phase=np.angle(s11_complex, deg=True) # 相位(度)
# 获取该 run 的参数值
params=all_param_values[run_id]
# 构建该 run 的数据字典
run_data= {
'Run_ID': run_id,
'Frequency_Hz': freqs,
'Frequency_GHz': freqs/1e9,
'S11_Real': s11_real,
'S11_Imag': s11_imag,
'S11_Magnitude': s11_mag,
'S11_dB': s11_db,
'S11_Phase_deg': s11_phase,
}
# 添加参数值到数据字典
forpname, pvalinparams.items():
run_data[pname] =pval
all_results.append(run_data)
if (idx+1) %5==0or (idx+1) ==num_runs:
print(f" 已读取: {idx+1}/{num_runs} (Run_ID={run_id})")
exceptExceptionase:
print(f" Run {run_id} 读取失败: {e}")
continue
print(f"成功读取 {len(all_results)} 个参数化扫描结果")
# ============================================================
# Step 5: 整理数据并导出
# ============================================================
print(f"\n===== 正在导出数据 =====")
# 将所有结果展平为 DataFrame 的行
export_rows= []
forrun_datainall_results:
n_points=len(run_data['Frequency_Hz'])
foriinrange(n_points):
row= {
'Run_ID': run_data['Run_ID'],
'Frequency_Hz': run_data['Frequency_Hz'][i],
'Frequency_GHz': run_data['Frequency_GHz'][i],
'S11_Real': run_data['S11_Real'][i],
'S11_Imag': run_data['S11_Imag'][i],
'S11_Magnitude': run_data['S11_Magnitude'][i],
'S11_dB': run_data['S11_dB'][i],
'S11_Phase_deg': run_data['S11_Phase_deg'][i],
}
# 添加参数值列(每个频率点重复相同的参数值)
forpnameinparam_names:
row[pname] =run_data.get(pname, np.nan)
export_rows.append(row)
df=pd.DataFrame(export_rows)
# 调整列顺序:Run_ID → 参数名 → 频率 → S11数据
cols_order= ['Run_ID'] +param_names+ [
'Frequency_Hz', 'Frequency_GHz',
'S11_Real', 'S11_Imag', 'S11_Magnitude', 'S11_dB', 'S11_Phase_deg'
]
# 只保留实际存在的列
cols_order= [cforcincols_orderifcindf.columns]
df=df[cols_order]
# ----- 导出为 CSV -----
df.to_csv(output_csv_path, index=False, encoding='utf-8-sig')
print(f"CSV 文件已保存: {output_csv_path}")
# ----- 导出为 Excel(多个 sheet)-----
try:
withpd.ExcelWriter(output_excel_path, engine='openpyxl') aswriter:
# Sheet 1: 所有数据汇总
df.to_excel(writer, sheet_name='All_Data', index=False)
# Sheet 2-N: 每个 Run_ID 的单独数据
forrun_datainall_results:
rid=run_data['Run_ID']
sheet_name=f"Run_{rid}"
run_df_data= {
'Frequency_Hz': run_data['Frequency_Hz'],
'Frequency_GHz': run_data['Frequency_GHz'],
'S11_Real': run_data['S11_Real'],
'S11_Imag': run_data['S11_Imag'],
'S11_Magnitude': run_data['S11_Magnitude'],
'S11_dB': run_data['S11_dB'],
'S11_Phase_deg': run_data['S11_Phase_deg'],
}
# 添加参数值(作为常数列)
forpnameinparam_names:
run_df_data[pname] = [run_data.get(pname, np.nan)] *len(run_data['Frequency_Hz'])
run_df=pd.DataFrame(run_df_data)
run_df.to_excel(writer, sheet_name=sheet_name, index=False)
# Sheet: 参数汇总表(每个 Run 的参数值一览)
param_summary= []
forrun_datainall_results:
row= {'Run_ID': run_data['Run_ID']}
forpnameinparam_names:
row[pname] =run_data.get(pname, np.nan)
row['S11_Min_dB'] =np.min(run_data['S11_dB'])
row['S11_Max_dB'] =np.max(run_data['S11_dB'])
param_summary.append(row)
pd.DataFrame(param_summary).to_excel(
writer, sheet_name='Param_Summary', index=False
)
print(f"Excel 文件已保存: {output_excel_path}")
exceptImportError:
print("未安装 openpyxl,跳过 Excel 导出(可通过 pip install openpyxl 安装)")
# ============================================================
# 完成总结
# ============================================================
print(f"\n{'='*50}")
print(f"===== 导出完成,数据摘要 =====")
print(f"{'='*50}")
print(f"参数化扫描数量: {num_runs}")
print(f"参数名称: {param_names}")
print(f"频率点数: {n_freq}")
print(f"总数据行数: {len(df)}")
print(f"总列数: {len(df.columns)}")
print(f"列名: {list(df.columns)}")
print(f"\n输出文件:")
print(f" CSV: {output_csv_path}")
print(f" Excel: {output_excel_path}")
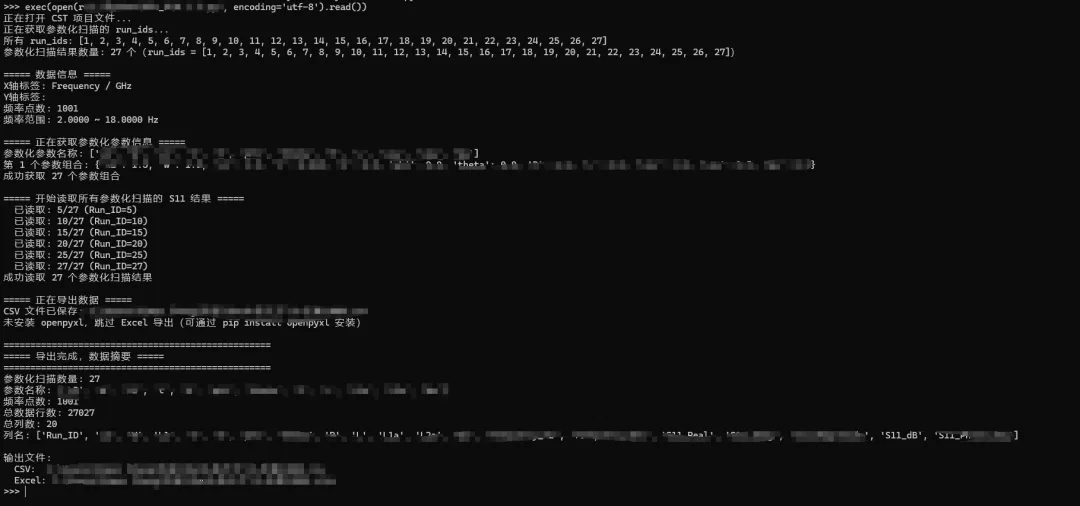
这个代码修改对应文件位置,保存文件位置,然后复制粘贴,保存为.py格式文件,这样就可以了。这个里面多说两个,就是自己带的python如果没有pandas以及numpy的话,记得在Windows的cmd界面输入记得用管理员身份运行,之后,在python界面使用exec(open(r"D:\文件位置\test.py", encoding='utf-8').read())
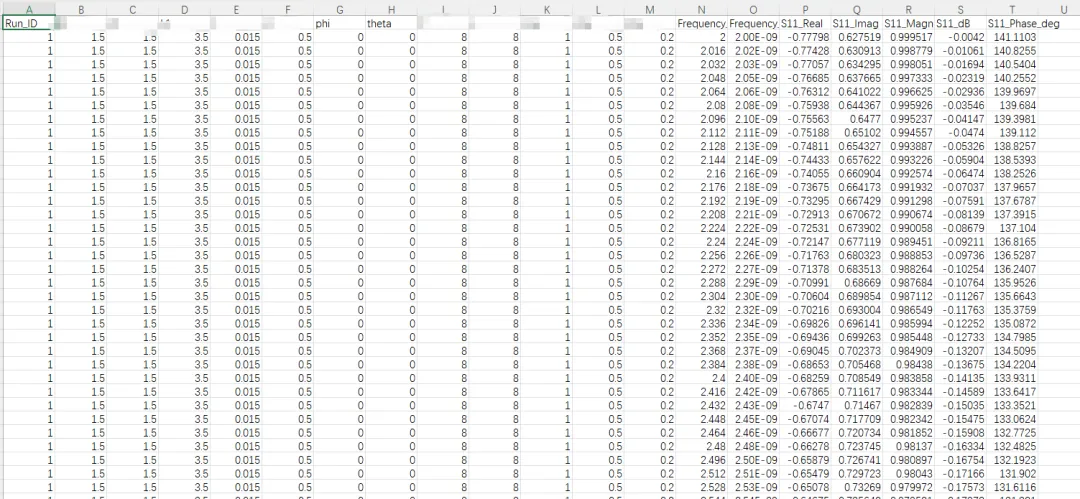
这样就可以读取了,笔者读取了5000组以上的数据,没有看到报错,也没有卡顿,非常好使笔者使用了另一个文件,只有27个,也可以顺利运行,由于没有安装excel相关的库,所以结果没有导出excel最后文件以csv格式保存,各种信息完备,方便读取处理
关于帮助文档,就是cst自己的help界面,自行获取


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
