接上篇的《Python编程从入门到实践》第三版 学习笔记 下(8~9章节),今天更新第10章,此篇属于附加篇1,包括文件的存取和异常的处理,之前说一周学完发现太难了,根本学不完!本来准备上中下就写完的,硬是拖出了两个附加篇,不管怎样,基础打实了才是最重要的,下面开始第10章的文件和异常的笔记。1. 读取文件(path.read_text())1.1 导入pathlib模块中的Path类的方法read_text()读取文本文件内容#读取txt文件,使用pathlib库读取路径from pathlib import Path #从pathlib模块导入Path类path = Path('pi_digits.txt') #新建Path对象指向一个‘pi_digits.txt’文件#使用Path类的方法read_text(),将文件内容作为字符串返回给变量contentscontents = path.read_text() print(contents)
D:\Jupyter\Python Study>file_reader.py3.1415926535 8979323846 2643383279
这里有一个问题,结尾部分有一空行,使用结尾空白删除方法:rstrip()也无法消除,后来查阅print()函数发现有一默认参数end='\n',也就是打印后结尾会默认换行,此处手动将其改为空白则换行取消,结尾无多余行#读取文件from pathlib import Path #导入Path类file_path = Path('pi_digits.txt') #创建Path类的一个对象#方法链式调用读取文件内容并删除结尾空格contents = file_path.read_text().rstrip()#print()函数有一个默认参数end='\n',默认结尾换行,#手动改为end=''空白则会消除这一行为print(contents,end='')
D:\Jupyter\Python Study>file_reader.py3.141592653589793238462643383279
contents = file_path.read_text().rstrip()
此行代码展现了方法链式调用(method chaining),从左到右依次执行方法,编程时可以简化代码①相对文件路径:file_path = Path('text_files/pi_digits.txt') 用于文件在当前程序所在文件夹中的子文件夹内的情况,程序在所在文件夹中查找text_files文件夹,然后进入再查找pi_digits.txt文件。②绝对文件路径:file_path = Path('D:/Jupyter/Python Study/text_files/pi_digits.txt')从根目录出发可读取系统中任何位置文件,注意要是斜杠而不是你直接copy过来的带反斜杠的地址。1.3 splitelines()方法将冗长字符串转换为一系列行:#(省略前面代码)示例 lines = contents.splitlines()for line in lines:print(line)
from pathlib import Pathfile_path = Path('D:/Jupyter/Python Study/text_files/pi_digits.txt')contents = file_path.read_text()for line in contents:print(line)
(注:不加splitlines()时,contents 是一个大字符串,for 循环遍历的是每个字符,而不是每一行)from pathlib import Pathfile_path = Path('D:/Jupyter/Python Study/text_files/pi_digits.txt')contents = file_path.read_text().splitlines()for line in contents:print(line)
D:\Jupyter\Python Study>splitlines.py3.1415926535 8979323846 2643383279
1.4 操作文件内字符串,将多行合并为一行,删除中间的空格strip():lines = contents.splitlines()pi_string = ''for line in lines: pi_string = pi_string+line.strip() print(pi_string)
2.写入文件(path.write_text())from pathlib import Pathpath = Path('programming.txt')#新建一个对象关联到一个文件名 path.write_text('I love programming') #调用path类中的write_text()方法
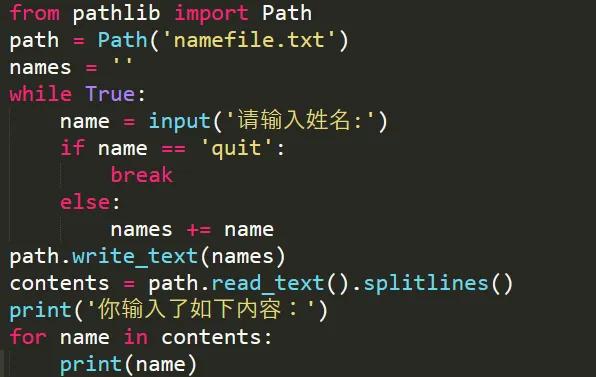
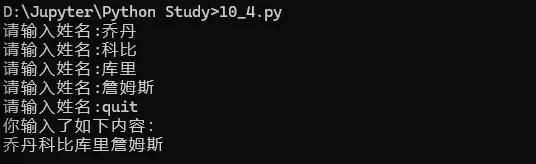
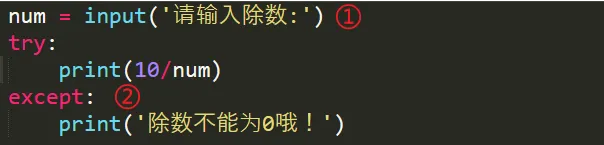
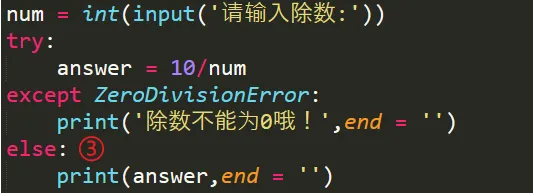
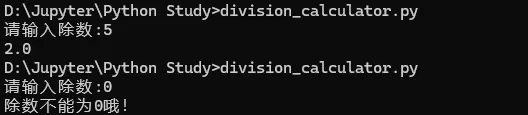
注:只能将字符串写入文本文件,若想写入数值则需使用str()转换为文本例题:新建一个文本文件,提醒用户写入姓名,最后将文件读取并按行打错误解析:最后输出没有按要求按行输出,原因在于写入的时候是按字符串连续相加,中间没有换行符‘\n’,因此读取的时候自然也是输出一段连续的结果,所以只要在拼接每个姓名的时候在中间增加一个换行符即可python 使用称为异常(exception)的特殊对象来管理执行发生的错误,每当错误发生它会创建一个异常对象,若你已编写处理该异常的代码,程序将继续运行,若没有,程序将停止并显示一个traceback,其中包含异常的报告,try-except 代码块的作用就是即便出现异常,程序也将继续运行并显示你编写的内容来告诉用户出了什么错。踩坑说明:①input() 在输入是数字的情况下也会将其转换为字符串,因此需加int() : num = int(input('请输入除数:')),这里没加,然后用数值10除以字符串,会出现一个TypeError②except后未加ZeroDivisionError(除零错误),因此其等价于except Exception(所有异常(除了系统级异常如强制终止程序的ctrl+C)),所以上面的TypeError也包括在内,因此执行except下面内容,在这里我们只交代除0错误才执行这条命令,因此需加ZeroDivisionError。③依赖try代码块成功执行的代码都被放在else代码块中,如果除法运算成功,就使用else代码块来打印结果3.2 静默失败 : pass代码可以让代码像什么都没有发生一样,充当一个占位符,程序会继续运行4.1 json.dumps() json.loads() 的使用:json保存用户生成的数据在程序停止运行时仍被存储,重新打开时数据还在
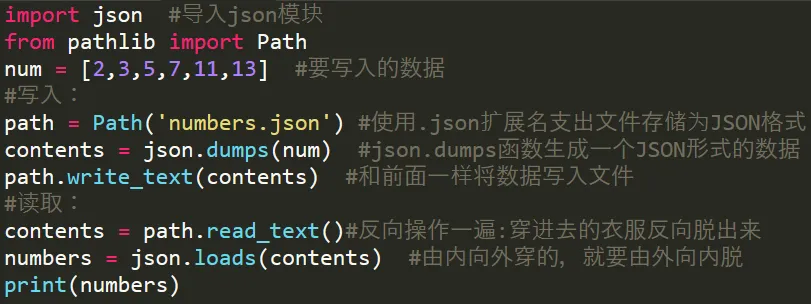
 json的使用需要注意3点:②.写入数据和前面不一样的是需要在写入前加一个使普通数据转为json格式的步骤:contents = json.dumps(num),然后才是和前面一样用write_text()方法写入;③读取时先正常用read_text()读取数据,然后把读取出来的json形式的数据使用json.loads()函数转为普通数据打印出来。总的来说,json的使用一句话概括为:数据的序列化与反序列化4.2 path.exists() 判断的使用:用于判断这个路径文件是否存在配合if语句使用可在文件存在时输出,不存在时选择写入。编写一个程序,可以实现一个记账簿的功能:用户可以输入对应的日期,项目,项目花费,然后将这些内容存在一个json文件中,同时用户可以查看账簿,关闭程序后重新打开,仍可以查看以前内容。项目分析:考察pathlib进行文件的读写,json模块的读写功能,字典的嵌套,数据结构设计,if条件语句的使用,异常处理(try/except)保障程序安全。
json的使用需要注意3点:②.写入数据和前面不一样的是需要在写入前加一个使普通数据转为json格式的步骤:contents = json.dumps(num),然后才是和前面一样用write_text()方法写入;③读取时先正常用read_text()读取数据,然后把读取出来的json形式的数据使用json.loads()函数转为普通数据打印出来。总的来说,json的使用一句话概括为:数据的序列化与反序列化4.2 path.exists() 判断的使用:用于判断这个路径文件是否存在配合if语句使用可在文件存在时输出,不存在时选择写入。编写一个程序,可以实现一个记账簿的功能:用户可以输入对应的日期,项目,项目花费,然后将这些内容存在一个json文件中,同时用户可以查看账簿,关闭程序后重新打开,仍可以查看以前内容。项目分析:考察pathlib进行文件的读写,json模块的读写功能,字典的嵌套,数据结构设计,if条件语句的使用,异常处理(try/except)保障程序安全。#导入模块及函数:from pathlib import Path #从pathlib库中导入Path类import json #导入json模块path = Path('user_information.json')#1——每次启动都会重置为空字典,导致记录丢失,应先尝试读取数据user_information = {} records = {}print('---欢迎使用记账簿---')#子函数:def information_input(): time = ''while True:print('请按顺序输入日期,商品名,花费:') time = input('日期(如:5/31):')if time == 'q':break#2——在输入商品名或花费时输入q会直接跳出循环导致以输入的日期没有对应数据 item = input('商品名称:')if item == 'q':break#3——花费应直接转为float方便日后统计 cost = input('花费(单位¥):')if cost == 'q':break#4——数据共享错误:全局变量records = {}在每次调用information_input()时反复使用且所有日期都指向这同一个字典对象 records[item] = cost user_information[time] = records contents = json.dumps(user_information) path.write_text(contents)return pathdef information_output():if path.exists(): contents = path.read_text() information = json.loads(contents)return informationelse:#5——文件不存在时没有任何返回值,会隐式返回一个None,导致主程序打印None,应返回明确的空字典{}print('内容为空,请先记账')#主程序:while True: active = input('请问是输入还是查看数据(输入请输:i,查看请输:o,退出请输:q):')#6——if结构错误,下面的else只是最后一个if的配对,因此只要不是'q'都会执行else内容if active == 'i': information_input()if active == 'o': user_informations = information_output()print(user_informations)if active == 'q':breakelse:print('请按提示输入!')print('---欢迎下次使用,再见!---')'''
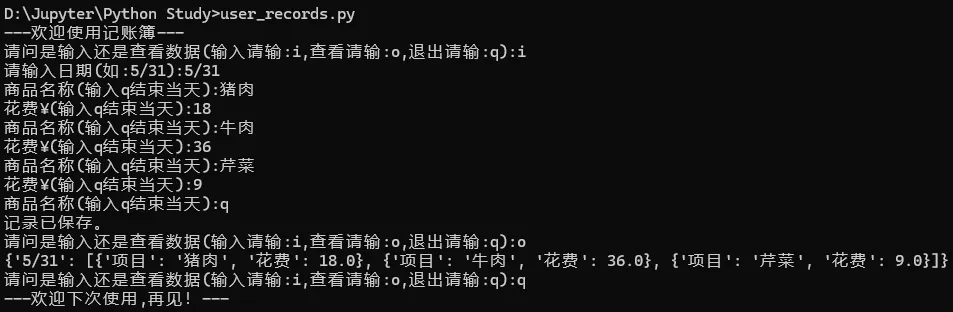
#导入模块及函数:from pathlib import Path #从pathlib库中导入Path类import json #导入json模块path = Path('user_information.json')#1——此处改为先尝试读取数据,同时加入try/except语句避免内容错误引起的异常if path.exists(): try: user_information = json.loads(path.read_text()) except json.JSONDecodeError: #json.JSONDecodeError是Python内置json模块抛出的解析异常,父类是ValueError #触发场景:调用 json.loads(字符串)/json.load(文件)时,传入的内容不符合标准JSON语法,解析器无法转换成Python dict/list。 user_information = {} #内容错误时重置为空字典else: user_information = {} #文件不存在时新建一个空字典print('---欢迎使用记账簿---')#子程序1def information_input(): """数据输入子程序""" #date在输入前不需要先行定义,删除date = '' #让用户先输入日期 date = input('请输入日期(如:5/31):').strip() #strip用于删除用户多输入的空格 if date.lower() == 'q': #加lower()防止输入为大写的Q return #需要优先取出该日期下已有的账簿,没有则新建空列表 #dict.get(key,b):获取dict字典中key对应的值,如果没有获取成功就返回设定值b,不会报错 records = user_information.get(date,[]) #如此日期已有记录,则获取该日期下的账簿,并继续在此日期上更新,没有则新建一个空列表用于记账 #2——按天来记录,如果当天记录完成,直接结束函数询问用户下一步操作 while True: item = input('商品名称(输入q结束当天):').strip() if item.lower() == 'q': break #3——input输入的花费默认为字符串形式,因此加后缀_str,后续调整为浮点数方便后续增加其他操作如统计当月花费 cost_str = input('花费¥(输入q结束当天):').strip() if cost_str.lower() == 'q': break try: cost = float(cost_str) except ValueError: print('花费请输入数字,本条记录未保存。') #如果不是数字就会不记录并提醒用户输入正确数据 continue #添加记录(商品重复视为两笔消费) records.append({'项目':item,'花费':cost}) #4——数据共享错误:全局变量records = {}在每次调用information_input()时反复使用,导致所有日期都指向这同一个字典 if records: #只有在有记录时才保存 user_information[date] = records # 数据结构为: {'日期1':[{'项目名1':花费},{'项目名2':花费},...],'日期2':[{'项目名1':花费},{'项目名2':花费}]} #简化写法即:{date:records,date:records},records是一个嵌套了字典的列表。 path.write_text(json.dumps(user_information,ensure_ascii=False,indent=2)) #后面两个参数设定用于json数据的美化,可以省略 print('记录已保存。') else: print('当天无记录') #因为数据已经保存到user_information中了,任务已经完成,后续要读取直接调用information_output()函数即可,无需返回值,因此return path去掉#子程序2def information_output(): """数据读取子程序""" #if先判断文件是否存在,存在则读取,不存在则提醒用户先输入 if path.exists(): try: contents = path.read_text() information = json.loads(contents) return information except json.JSONDecodeError: print('文件损坏,无法读取。') return {} #文件不存在时没有任何返回值,会隐式返回一个None,导致主程序打印None,应返回明确的空字典{} else: #文件不存在时没有任何返回值,会隐式返回一个None,导致主程序打印None,应返回明确的空字典{} print('内容为空,请先记账')#主程序:while True: active = input('请问是输入还是查看数据(输入请输:i,查看请输:o,退出请输:q):').strip().lower()#5.if结构调整为if--elif--elif--else结构,保证前三项都不满足时才运行else结果。 if active == 'i': information_input() elif active == 'o': user_informations = information_output() print(user_informations) elif active == 'q': break else: print('请按提示输入!')print('---欢迎下次使用,再见!---')
1.对于有json的代码,应先尝试读取json文件,若有内容一般需要先导入;2.数据复杂时可用字典的嵌套,使用前务必先确认好数据结构;3.if-elif-else结构前两个条件不满足else才会执行;5.input()输入内容会被默认转为字符串格式,如需数字则需提前转换;6.在提醒用户输入字母时需考虑用户可能输入大写,需用lower()转换;7.函数目的若是将数据写入文件的一般无需返回值,因为数据已存进文件。此次实践题目融合了部分前面的基础知识,后续实践项目尽量会融合已经学过的知识,还是那句话:用以致学。距离这次我写第一篇内容已经过去两周多了,主要是学习了Python的基础知识,另外还剩第11章未更新,《Python编程从入门到实践》这本书第一部分基础知识学完后面是游戏项目,个人觉得不符合我的需求,第11章更新完后,后面转numpy及pandas相关内容的学习,各位同学和前辈有什么心得或建议欢迎留言一起交流。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
