一、前言
看过上篇《显存低配福音!llama.cpp本地AI编程免费部署》的朋友都知道:普通无独显、低显存电脑,也能流畅跑本地大模型,彻底告别在线AI充值、泄密问题。
但原生 llama.cpp 仅提供基础推理能力与简易调试界面,只能本地测试,无代码接口、无法二次开发、无法和业务系统打通。因此我们需要通过代码深度整合 llama.cpp 底层能力,封装接口、开发可视化业务功能,才能落地真实业务。
本文基于 llama-cpp-python 代码编程方式,深度整合 llama.cpp 离线推理核心能力,搭配 FastAPI + Vue3 搭建一套纯离线、零费用、可集成的广告文案业务测试系统,专注广告行业策划案、短视频文案生成,主打大模型与业务系统集成能力落地测试。
二、技术架构
核心技术栈:本项目基于官方原生 llama-cpp-python 开发,核心架构优势在于摆脱 llama.cpp 原生命令行启动模式,支持通过 Python 代码直接加载、启动和运行大模型。可直接嵌入后端服务体系,实现模型推理与程序服务一体化,是 llama.cpp 工程化集成的标准技术方案。
后端架构:基于 FastAPI 搭建轻量化后端服务,将模型推理能力封装为标准接口,实现模型能力可调用、可集成、可拓展,适配各类程序业务场景。
前端架构:采用 Vue3 + Element Plus 构建可视化交互界面,对接后端标准化接口,实现模型能力可视化调用与测试。
部署架构:全本地私有化部署,模型、推理、服务均运行在本地设备,跨平台兼容,主打模型离线推理与工程化集成能力测试。
三、核心实现思路
本项目整体实现逻辑简洁清晰,主打轻量化工程化集成,无需复杂配置即可完成大模型服务落地。首先基于llama-cpp-python库,在本地设备中通过代码加载GGUF量化大模型,优化模型推理参数,保障低配设备稳定运行离线推理服务,彻底替代传统命令行启动的孤立运行模式。
后端依托FastAPI框架搭建轻量化服务,对大模型的文本推理能力进行封装,统一生成、润色类接口规范,实现模型能力的标准化调用,同时保障服务可拓展、可对接各类业务项目。前端基于Vue3+Element Plus搭建可视化操作页面,简洁适配后端接口逻辑,实现功能可视化调用、结果实时展示,降低模型测试与集成的操作门槛。
整套项目采用前后端分离架构,全程本地私有化运行,无外网数据交互,兼顾轻量化、安全性与实用性,可快速验证llama.cpp代码集成能力,适配低配设备的大模型工程化测试场景。
整条业务链路可以概括为:下载模型 → 启动预加载 → 接口推理 → 页面展示,下面按执行顺序说明核心逻辑。
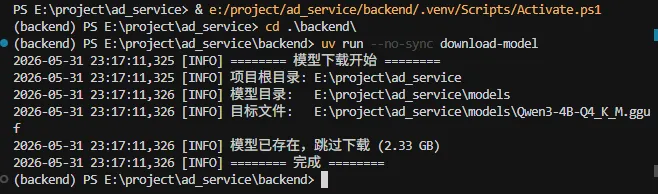
Step 1|模型准备执行 uv run download-model,优先走 ModelScope 国内镜像,将 Qwen3-4B Q4_K_M 量化模型下载到本地 models/ 目录。.env 中配置模型路径、GPU 层数、上下文长度等参数,避免推理时显存溢出。
Step 2|服务启动与预加载
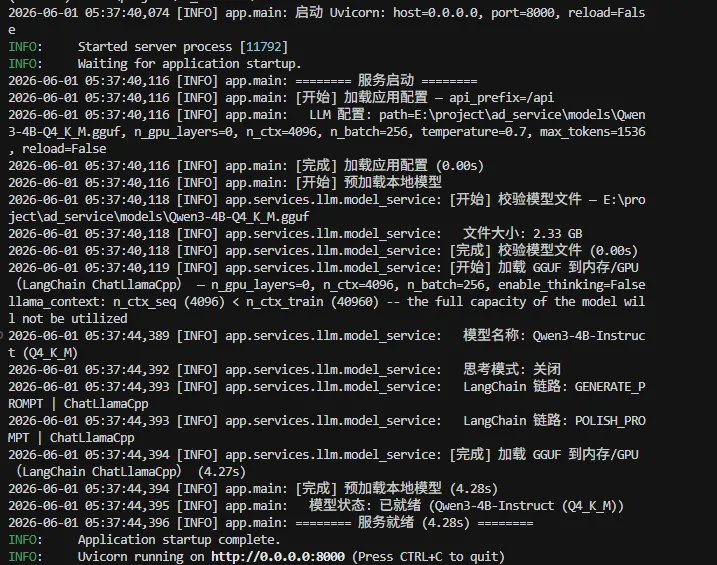
uv run serve 启动 FastAPI 后,生命周期钩子自动读取配置,通过 llama-cpp-python 将 GGUF 加载进显存,全程只加载一次、全局单例复用。日志会逐步输出「读配置 → 校验模型 → 加载 GPU(由于显卡太旧用的是CPU) → 服务就绪」,无需再调单独的预热接口。
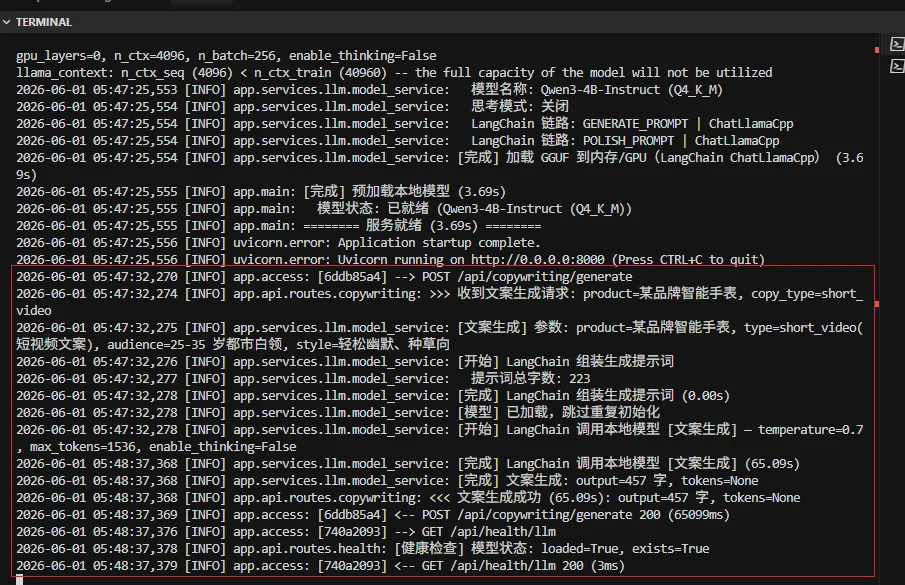
Step 3|LangChain 组装并推理前端提交产品名、受众、文案类型等参数 → FastAPI 接收请求 → LangChain ChatPromptTemplate 填充变量生成提示词 → 进入对应链路推理:
提示词与业务解耦,改话术只改模板;推理在独立线程执行,不阻塞 Web 主线程。
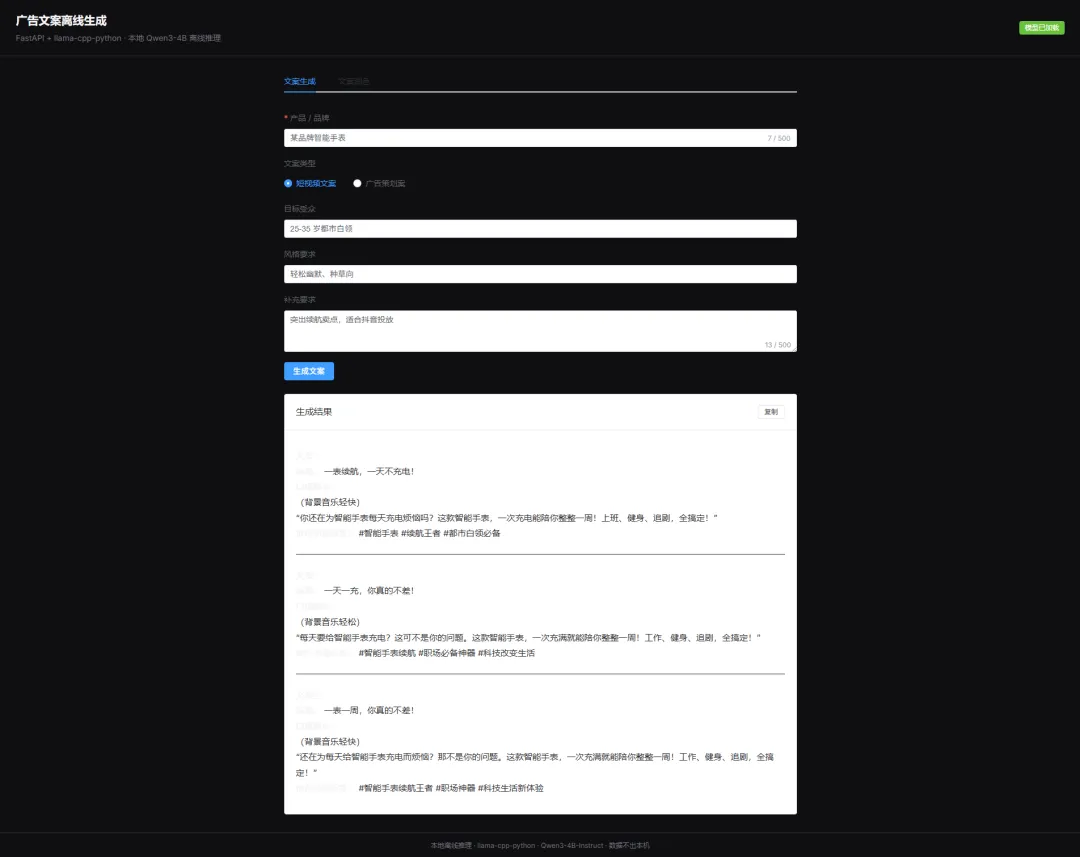
Step 4|前端调用与结果展示Vue3 页面调用 /api/copywriting/generate 或 /polish,后端返回统一 JSON,前端实时渲染策划案 / 短视频文案。右上角可查看模型加载状态,全程本地离线,数据不出本机。
四、项目总结与学习引导
相较于原生llama.cpp仅支持命令行调试、无法对接业务体系的局限性,基于llama-cpp-python开发的方案,真正实现了大模型代码化启动、服务化运行与工程化集成,打通了本地大模型与程序业务系统的壁垒,是低配设备下落地离线AI服务的优质方案。
本项目无需高额硬件配置、无任何调用费用,部署简单、架构轻量化,不仅可以用于广告文案类场景的测试使用,更可作为llama.cpp二次开发、业务集成的通用模板,适配各类离线文本生成业务场景,具备极高的学习与复用价值。
实战踩坑记录(共 8 条)
老显卡用不了 GPU 推理:GTX 10 系等与新版 CUDA wheel 不兼容 → 装 CPU 版
Windows 别直接 pip 装 llama-cpp-python:易触发源码编译失败 → 用 GitHub Releases 的 预编译 wheel。
CPU 版优先 v0.3.22:v0.3.23 CPU 在部分机器会崩溃 → 安装脚本与 README 已默认 v0.3.22。
CPU 推理偏慢属正常:单次生成 60s+ 常见 → 关闭思考模式 LLM_ENABLE_THINKING=false,必要时调小 LLM_MAX_TOKENS。
本地服务别开热重载:推理中进程重启易触发 CUDA/模型状态异常 → SERVER_RELOAD=false。
我会持续更新llama.cpp工程化、低配设备AI部署实战干货,同时已整理好本项目完整可运行源码!想要免费领取源码、快速上手实操的朋友,记得点赞、收藏、转发、一键三连,私信即可获取全套工程源码,轻松掌握llama-cpp-python业务集成核心技巧!

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
