大家好,我是木木。
今天给大家分享一个稳健的 Python 库,psycopg。
psycopg
如果你的 Python 服务要连接 PostgreSQL,psycopg 基本绕不开。它是 PostgreSQL 生态里非常常见的适配器,第三代版本同时支持更现代的类型处理、连接信息解析、安全 SQL 组合和行结果工厂。它不是 ORM,而是数据库驱动层,所以更适合你已经明确要写 SQL、封装 DAO,或者给 SQLAlchemy、Django 等上层工具提供连接能力的场景。
项目地址:https://github.com/psycopg/psycopg
官方文档:https://www.psycopg.org/psycopg3/docs/
三大特点
连接清楚
连接串、关键参数和连接配置可以统一解析,方便服务启动时做校验和日志脱敏。
SQL 安全
表名、字段名和参数占位符可以分开组合,减少字符串拼接 SQL 带来的注入风险。
结果灵活
通过 row factory 可以决定返回 tuple、dict 或 namedtuple,适配脚本和服务端不同风格。
最佳实践
安装方式:pip install "psycopg[binary]"。
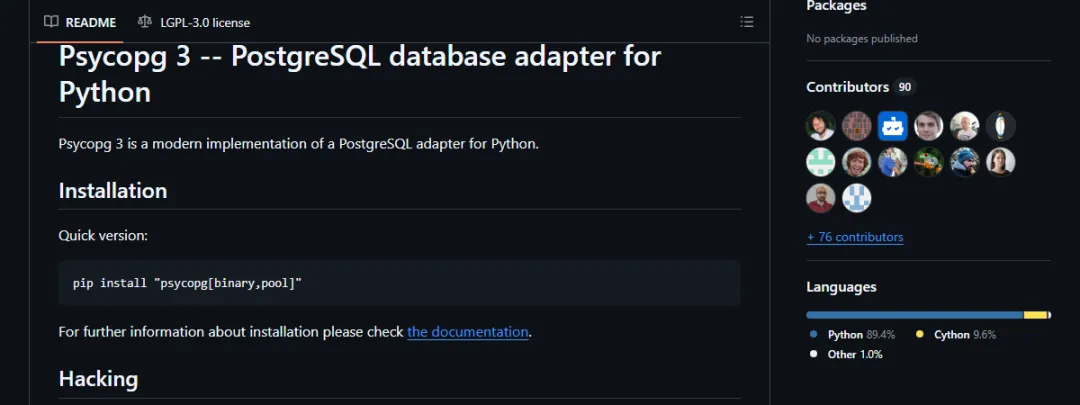
第一段代码解决的问题是:把连接串解析成清晰的配置字段。示例不连接真实 PostgreSQL,只验证连接信息处理。
frompsycopgimportconninfoinfo=conninfo.conninfo_to_dict("postgresql://app:secret@localhost:5432/shop?sslmode=disable")print("host:",info["host"])print("dbname:",info["dbname"])print("user:",info["user"])print("sslmode:",info["sslmode"])
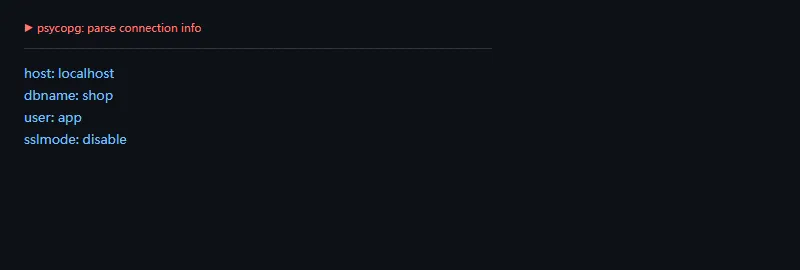
第二段看 SQL 组合。表名和字段名不能用普通参数占位符代替,应该用 Identifier 处理;值参数则继续走占位符。
frompsycopgimportsqlquery=sql.SQL("select {fields} from {table} where {column} = {placeholder}").format(fields=sql.SQL(", ").join([sql.Identifier("id"),sql.Identifier("email")]),table=sql.Identifier("users"),column=sql.Identifier("status"),placeholder=sql.Placeholder("status"),)print("query:",query.as_string(None))
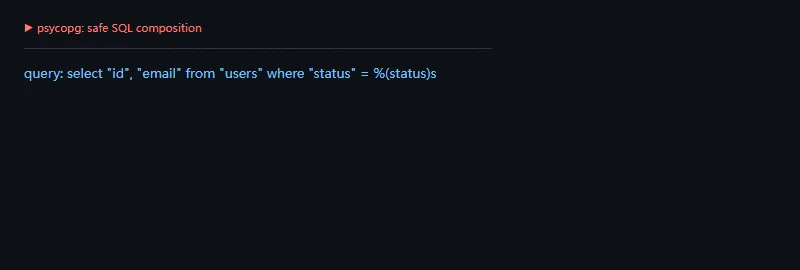
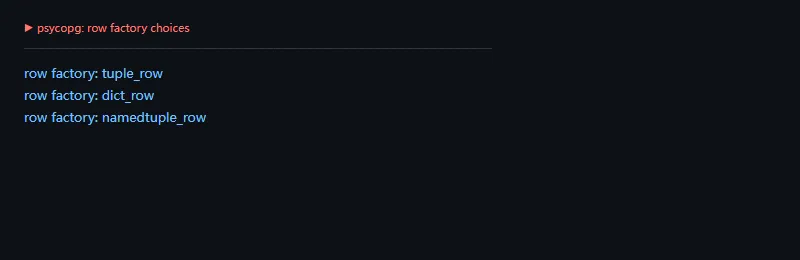
进阶一点看行工厂。服务层常常希望拿 dict,脚本里可能 tuple 就够了;把返回形态集中配置,比到处手动转换更稳。
frompsycopg.rowsimportdict_row,namedtuple_row,tuple_rowforfactoryin[tuple_row,dict_row,namedtuple_row]:print("row factory:",factory.__name__)
环境与版本信息
本文示例使用 Python 3.11,psycopg 版本为 3.3.4,psycopg-binary 版本为 3.3.4。当前包声明 Python 版本要求为 3.10 及以上。
适用场景
适合 PostgreSQL 项目、需要自己掌控 SQL 的服务、内部数据脚本,以及需要在同步和异步访问之间保留选择空间的团队。
不适用场景
如果你想要完整 ORM,应该看 SQLAlchemy、Django ORM 或 SQLModel。若团队成员不熟 SQL,直接暴露驱动层可能会让业务代码变散。
上线检查
- 使用参数化查询,表名字段名用
psycopg.sql 组合。
总结
psycopg 是 PostgreSQL 和 Python 之间非常可靠的一层。它不会替你设计 SQL,但能让连接、参数、结果和安全边界更可控。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
