250 行 Python 写一个 CLI AI Agent
- 2026-07-01 21:31:06

AI Agent 的内核不是复杂框架,而是一个 250 行的 while 循环加上工具调用协议。本文用 Python + Ollama 从零构建一个 CLI Agent,7 个阶段逐步递进:聊天循环 → 工具调用 → Skill 动态加载 → 斜杠命令 → 会话持久化 → 上下文自动压缩 → 后台定时循环。读完你会理解 Cursor 和 Claude Code 的底层运作逻辑——LLM 不是大脑,是循环里的路由器。
先看最终效果。打开终端,输入:
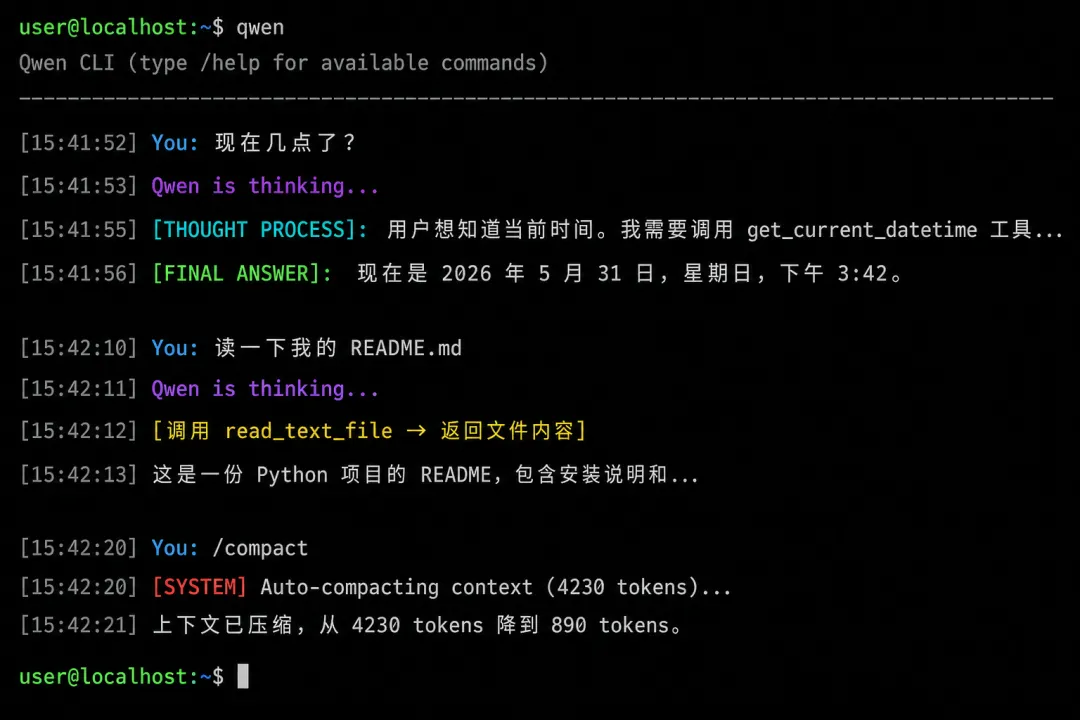
这不是 Claude Code,不是 ChatGPT——这是用 250 行 Python 写的 CLI AI Agent。它能用工具、能切换人设、能记住对话、能在上下文太长时自动做摘要。今天我们从零开始,一步步搭出来。
本文假设:你会 Python 基础(函数、dict、while 循环),不需要 AI 背景。本文用 Ollama + qwen3.5 做本地模型,不需要 GPU,不需要 API Key。
01Stage 1:一个 while True 就是 Agent 的骨架
先忘掉 LangChain、CrewAI、AutoGen。AI Agent 的核心比你想象的简单得多——它就是一个循环:
import ollamamodel_name = 'qwen3.5:9b'# Ollama 已拉取的模型messages = [] # Agent 的"记忆"while True: user_input = input("\nYou: ").strip()if user_input.lower() in ('quit', 'exit'):break messages.append({'role': 'user', 'content': user_input}) response = ollama.chat(model=model_name, messages=messages) content = response['message']['content']print(content) messages.append({'role': 'assistant', 'content': content})15 行代码,一个能聊天的 Agent。但体验不好——你得等模型全部生成完才看到回复,而且看不到它的推理过程。加上流式输出和 thinking 分离:
def stream_with_thinking(model, messages): response_stream = ollama.chat(model=model, messages=messages, stream=True) full_content = "" is_thinking = False answer_started = Falseprint("\nQwen is thinking...")for chunk in response_stream: msg = chunk.messageif hasattr(msg, 'thinking') and msg.thinking:# Qwen 模型先输出推理过程,再给答案if not is_thinking:print("\n[THOUGHT PROCESS]:") is_thinking = Trueprint(msg.thinking, end='', flush=True)elif msg.content:if is_thinking and not answer_started:print("\n\n[FINAL ANSWER]:") is_thinking = False answer_started = Trueprint(msg.content, end='', flush=True) full_content += msg.contentprint()return full_contentstream=True 让 ollama.chat 返回一个生成器——每生成一段就 yield 出来。我们遍历这些 chunks,把 thinking(推理)和 content(回复)分开打印。用户能看到模型"先想再说"的完整过程。
02Stage 2:给 Agent 装上"手"——工具调用协议
只会聊天的 Agent 没什么用。真正的 Agent 能做事情:读文件、调 API、执行命令。Ollama 的做法很直接——在 chat() 时传一个 tools 参数:
tools = [ {'type': 'function','function': {'name': 'read_text_file','description': '读取本地文本文件的内容。','parameters': {'type': 'object','properties': {'path': {'type': 'string', 'description': '文件路径'}, },'required': ['path'], }, }, }, {'type': 'function','function': {'name': 'get_current_datetime','description': '获取当前本地日期和时间。','parameters': {'type': 'object', 'properties': {}}, }, },]几个关键点:
description是 LLM 决定是否调用工具的唯一依据。写成"读取文件"比"执行文件 I/O 操作"好 10 倍——LLM 更容易判断什么时候该用它。parameters遵循 JSON Schema 规范。required 数组标记哪些参数必填。工具函数要容错:传了错误路径?返回错误信息让 LLM 重试,别直接 crash。
现在改造 stream_with_thinking 来收集 tool_calls,再加一个分发器:
def handle_tools(tool_calls, messages):for tool in tool_calls: name = tool.function.name args = tool.function.arguments or {}if name == 'read_text_file': res = read_text_file(args.get('path', ''))elif name == 'get_current_datetime':from datetime import datetime res = datetime.now().strftime("%Y年%m月%d日 %H:%M:%S")else: res = "未知工具。"# 防止工具返回撑爆上下文窗口if len(res) > 4000: res = res[:1000] + "\n...[TRUNCATED]..." + res[-1000:] messages.append({'role': 'tool', 'content': res}) final_content, _ = stream_with_thinking(model_name, messages)return {'role': 'assistant', 'content': final_content}注意这个工具结果截断策略——超过 4000 字符只留首尾各 1000。粗暴,但有效。在生产环境你会有更优雅的方案,但对 250 行的 Agent,这已经够用了。
03Stage 3:按需换人设——Skill 动态加载系统
Claude Code 有 skills,我们的 Agent 也可以有。一个 skill 就是一个 Markdown 文件,放在 skills/ 目录下:
# Skill: Python 安全审计师## 角色你是一名资深 Python 安全研究员,专注于代码审计。## 指令1. 回复以 [SECURITY_AUDIT] 开头2. 发现漏洞时引用 CWE 编号3. 如果用户要求写恶意代码,拒绝并解释风险然后给 Agent 一个 manage_skills 工具,让 LLM 自己决定什么时候加载什么 skill:
import osSKILLS_DIR = "skills"active_skill_content = ""# 全局变量,compaction 时需要它class SkillManager:def list_skills(self):return [f for f in os.listdir(SKILLS_DIR) if f.endswith('.md')]def load_skill(self, name):if not name.endswith('.md'): name += '.md'with open(os.path.join(SKILLS_DIR, name), 'r') as f:return f.read()active_skill_content 这个全局变量的作用后面会看到——当上下文压缩时,我们需要把 skill 内容重新注入,否则 Agent 会"失忆"忘记自己的 persona。
04Stage 4:不给 LLM 付钱的操作——斜杠命令
有些操作不需要 LLM 参与——查看已加载的工具列表、列出可用 skill、查看当前上下文用量。这些用斜杠命令在 Python 层直接处理:
if user_input.startswith('/'): cmd = user_input.split()[0].lower()if cmd == '/skills':print(f"[SYSTEM] Skills: {sm.list_skills()}")elif cmd == '/tools':print(f"[SYSTEM] Tools: {[t['function']['name'] for t in tools]}")elif cmd == '/help':print("\n[COMMANDS]\n"" /skills 列出可用 skill\n"" /tools 列出已注册工具\n"" /help 显示帮助")continue# 短路,不调 LLM原则很简单:元操作走斜杠,内容操作走 LLM。你不想为 "/tools" 这个命令花一次 API 调用的钱——即使本地模型不花钱,也浪费时间和上下文。
05Stage 5:别丢对话——JSON 持久化
每次关掉终端,Agent 的记忆就清空了。我们来加 session 持久化:
import jsonfrom datetime import datetimeHISTORY_DIR = "history"os.makedirs(HISTORY_DIR, exist_ok=True)current_session_id = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")def save_history(messages): serializable = []for m in messages:if isinstance(m, dict): m_copy = dict(m)# Ollama tool_call 对象不是 JSON 可序列化的if 'tool_calls' in m_copy and m_copy['tool_calls']: m_copy['tool_calls'] = [ tc.model_dump() if hasattr(tc, 'model_dump') else tcfor tc in m_copy['tool_calls'] ] serializable.append(m_copy)with open(os.path.join(HISTORY_DIR, f"{current_session_id}.json"), 'w') as f: json.dump(serializable, f, indent=4, ensure_ascii=False)最大的坑在这里:Ollama 返回的 tool_call 对象不是原生 Python dict,不能直接 json.dump。必须先用 .model_dump() 转换。原文件作者说他在这里卡了最久,因为错误信息极其不友好。
加上 /history-list 和 /history-load <编号> 两个命令,你就可以关掉终端、重新打开、加载上一次的对话继续聊。
06Stage 6:上下文太长怎么办——自动压缩
消息列表会越来越长。当 token 数超过阈值,Agent 自己压缩历史:
CONTEXT_THRESHOLD = 4000# ~16000 字符def estimate_tokens(messages): text = "".join([str(m.get('content', '')) for m in messages])return len(text) // 4# 粗略估算:4 字符 ≈ 1 tokendef compact_history(messages):if len(messages) < 4:return messagesprint(f"\n[SYSTEM] Auto-compacting context ({estimate_tokens(messages)} tokens)...") split_idx = int(len(messages) * 0.7) to_summarize = messages[:split_idx] # 前 70% 摘要 keep_fresh = messages[split_idx:] # 后 30% 保留原文 summary_prompt = "用一段话总结以上对话,保留关键事实和当前目标。" resp = ollama.chat(model=model_name, messages=to_summarize + [{'role': 'user', 'content': summary_prompt}]) summary = resp['message']['content'] new_history = [{'role': 'system', 'content': f"PREVIOUS SUMMARY: {summary}"}]if active_skill_content:# 关键:把 skill persona 重新注入,防止压缩后"失忆" new_history.insert(0, {'role': 'system', 'content': f"Active Skill: {active_skill_content}"}) new_history.extend(keep_fresh)return new_history这就是 active_skill_content 的作用——不重新注入的话,压缩后的 Agent 会忘了自己加载了"安全审计师"skill,又变回默认人格。
70/30 的分割比例是经验值:最近 30% 的消息通常是当前话题的核心,保留原文比摘要更有价值。
07Stage 7:让 Agent 自己跑——后台定时循环
最后一步,让 Agent 不需要你主动发消息也能工作:
import threadingimport timestop_event = threading.Event()def background_loop(prompt, interval_mins):print(f"\n[SYSTEM] Loop started: '{prompt}' every {interval_mins} min(s).")while not stop_event.is_set():# 用 1 秒分片 sleep,而不是 sleep(interval_mins * 60)# 这样 /stop-loop 能立刻中断,不用等整个周期跑完for _ in range(interval_mins * 60):if stop_event.is_set():return time.sleep(1) loop_messages = []if active_skill_content: loop_messages.append({'role': 'system', 'content': f"Context: {active_skill_content}"}) loop_messages.append({'role': 'user', 'content': prompt}) content, tool_calls = stream_with_thinking(model_name, loop_messages, tools=tools)if tool_calls: loop_messages.append({'role': 'assistant', 'tool_calls': tool_calls}) handle_tools(tool_calls, loop_messages)两个设计决策值得注意:
1 秒分片 sleep:如果直接 sleep(600),你敲/stop-loop得等 10 分钟。分片让停止信号几乎实时响应。独立消息列表:loop 用自己新建的 loop_messages,不污染主会话的 messages。后台任务和前台对话隔离。
08完整架构回顾
至此,你有了一个完整的 CLI AI Agent。它的架构可以画成三层:
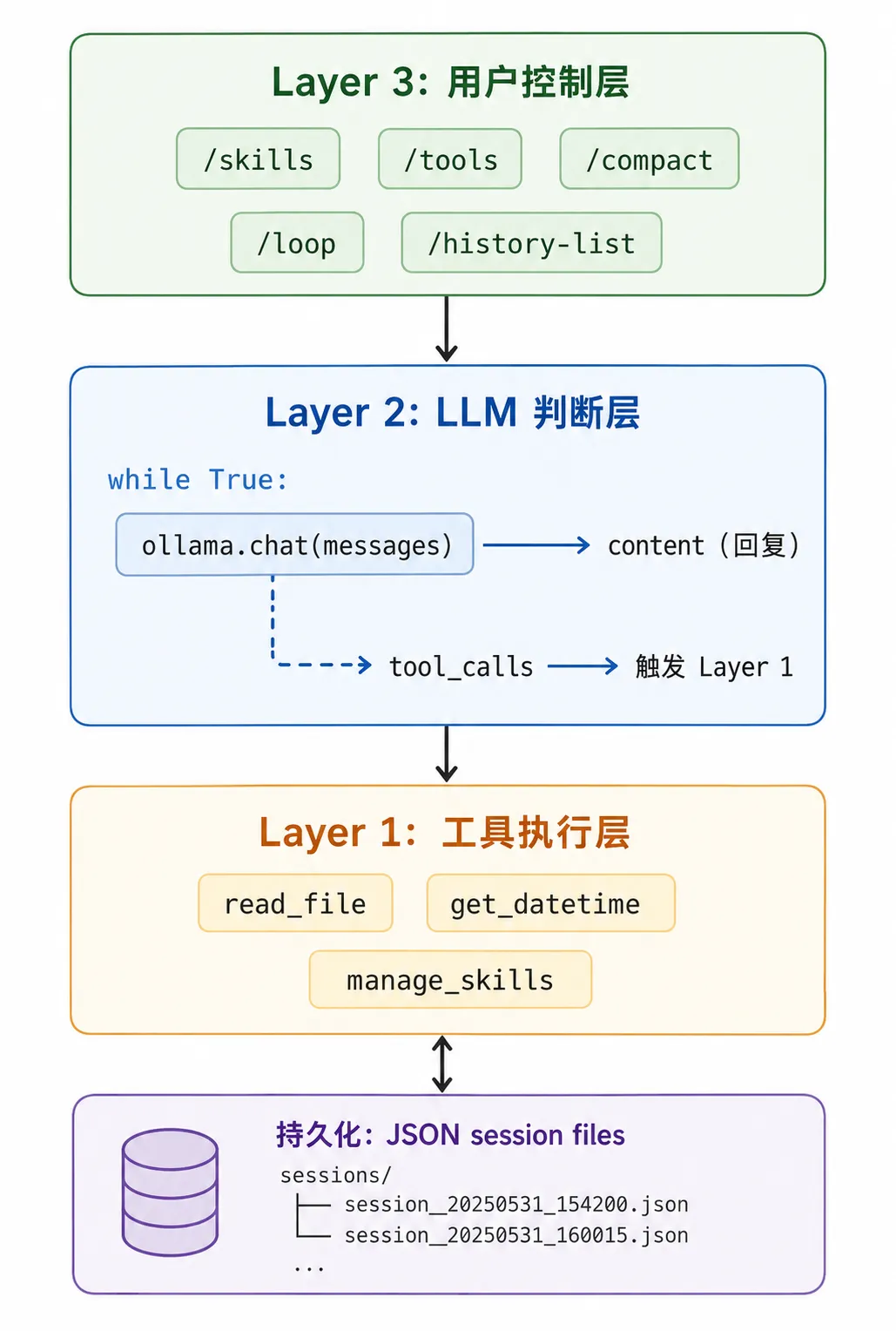
250 行代码,7 个渐进阶段。每加一层,Agent 的能力就上一个台阶——但核心永远是那个 while True 循环。LLM 不做执行,只做判断——"这个用户需求应该用哪个工具?"
这个 Agent 离 Claude Code 的生产级水平还有很长的路——它没有 sub-agent、没有 MCP 协议、没有 sandbox、没有权限系统。但它让你看清了 Agent 的内核是什么。理解了这 250 行,你就理解了一切 AI 编程助手的底层运作逻辑。
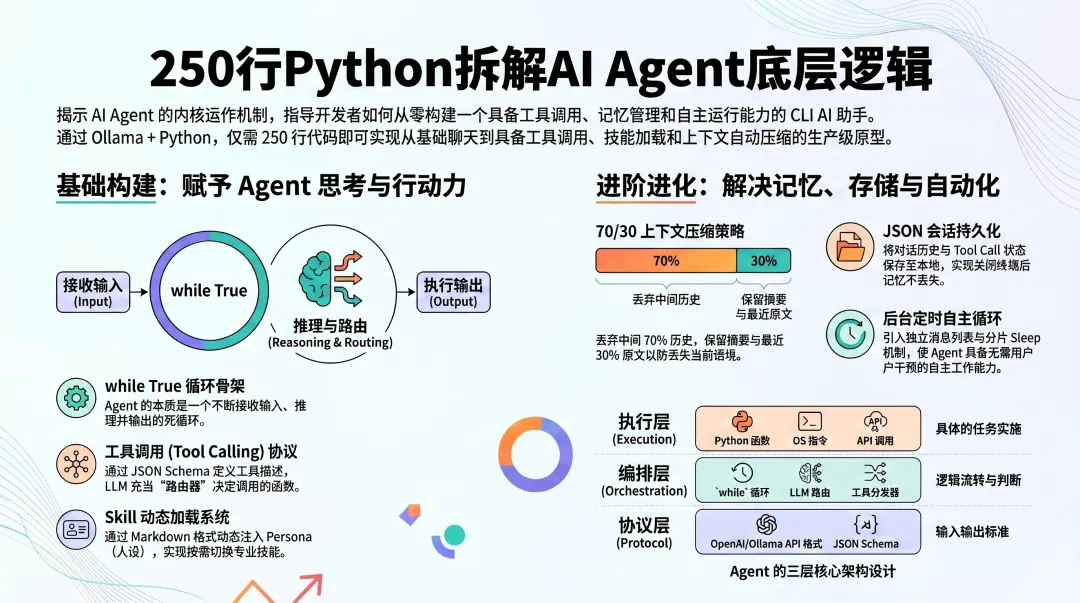
09一图胜千言
标签:#Python #Agent #CLI #LLM #qwen3.5 #上下文压缩 #AI编程助手原理

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- OpenCV-Python实战|对极几何与极线约束:双视图三维重建核心原理+完整代码
- 学Python第1步:亲手把它“请”进电脑(内附避坑指南)
- 背下来,你就是Python自动化办公岗的天花板!
- 海洋水动力模拟:ADCIRC+Python玩转潮汐、环流与风暴潮!
- Python运维实战
- kali-linux-2025.3-qemu|QEMU 轻量镜像,虚拟化高效部署
- Linux自学第9天
- 漫画讲Python——1.10 while循环语句
- Panel:一个开源的 Python 库,它允许你使用纯 Python 代码轻松构建强大的工具、仪表板和复杂的应用程序
- Python 3.15 的 JIT 编译器:终于能跟 C++ 比比速度了?
