分组、透视后生成多级索引结构,常规方式难以筛选与导出,拆解重组实现灵活数据提取与格式标准化。场景:地区+品类双层索引数据表,按层级筛选数据、拆分索引为独立字段、重新编排结构。核心知识点:swaplevel索引层级互换、unstack/stack行列转换、多级索引条件筛选、索引扁平化。① 生成测试数据
import pandas as pdimport numpy as np# 构造多级索引原始数据raw = pd.DataFrame({ "region": np.random.choice(["华东","华北","华南"], 120), "category": np.random.choice(["数码","家居","美妆"], 120), "sales": np.random.randint(200, 5000, 120), "profit": np.random.randint(50, 1200, 120)})# 生成分组多级索引表multi_df = raw.groupby(["region", "category"]).agg({"sales":"sum", "profit":"mean"})multi_df.to_excel("multi_index.xlsx")print("多级索引测试数据生成完成")
查看表格数据
② 核心代码
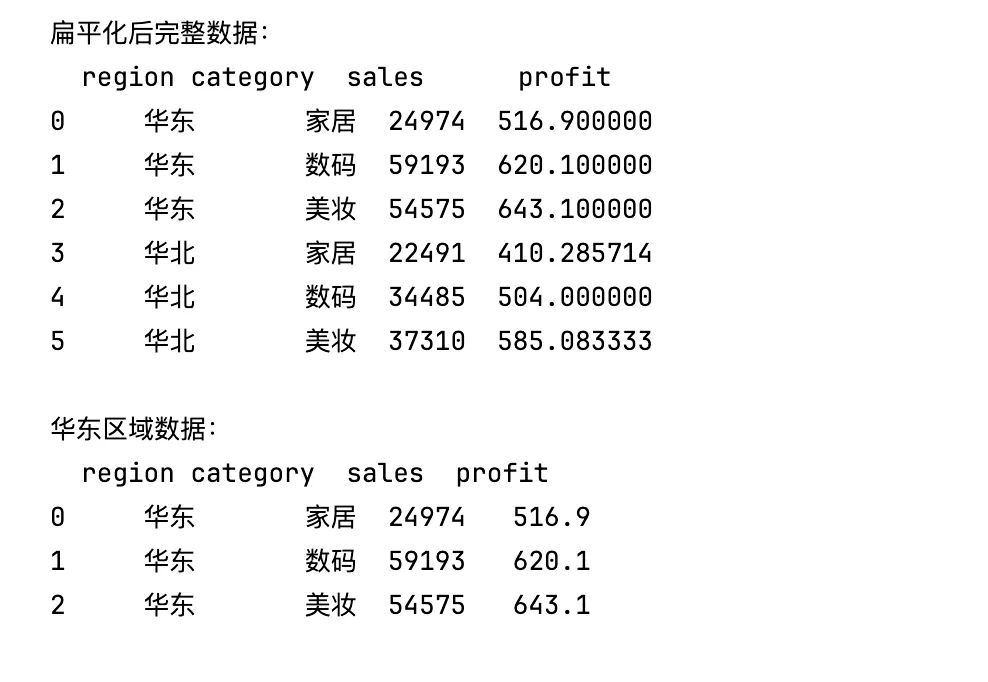
import pandas as pd# region 合并单元格了# 1. 先读取全部数据,不指定索引df = pd.read_excel("multi_index.xlsx")# 2. 填充Excel合并单元格带来的空值(向下补全区域名称)df["region"] = df["region"].ffill()# 3. 手动设置多级索引df = df.set_index(["region", "category"])# 1. 索引层级互换df_swap = df.swaplevel("region", "category")# 2. 多级索引扁平化,转为普通列df_flat = df.reset_index()# 3. 按上层索引筛选数据filter_data = df_flat[df_flat["region"] == "华东"]print("扁平化后完整数据:")print(df_flat.head(6))print("\n华东区域数据:")print(filter_data)
总结
多级索引是复杂多维分析的产物,熟练拆解与重组,可解决层级数据筛选、导出、对接下游系统的各类问题,是进阶数据分析必备技能。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
