CFS 气候预报数据python下载
- 2026-07-02 19:13:55
CFS 气候预报数据python下载
CMC 全球确定性预报数据下载指南 低空经济的核心是气象保障 CMA-GFS气象数据转换到Zarr格式技术解析 全球气候变暖让飞机更颠簸了吗? 电离层对地基雷达测量精度的影响分析与校正方法
数据集介绍
CFS(Climate Forecast System,气候预报系统)是由美国国家环境预报中心(NCEP)开发的新一代全球气候预报系统。它基于耦合的大气-海洋-陆地-海冰模式,提供从次季节到季节尺度(最长9个月)的预测产品。
CFSv2(第二版)于2011年业务化运行,每天运行四次(00、06、12、18 UTC),但通常只有12 UTC循环输出完整的日平均/日累积场,是最常用的数据版本。
数据集特点
时间范围:预报时长0–9个月(逐日输出)
空间分辨率:约0.5°×0.5°(T382谱截断,高斯网格)
变量丰富:包含大气、海洋、陆面、海冰等数百个要素
数据格式:GRIB2(二进制格点格式)
数据量:单日全部变量约10–15 GB,常用表层变量约500 MB
常用要素详解
数据获取
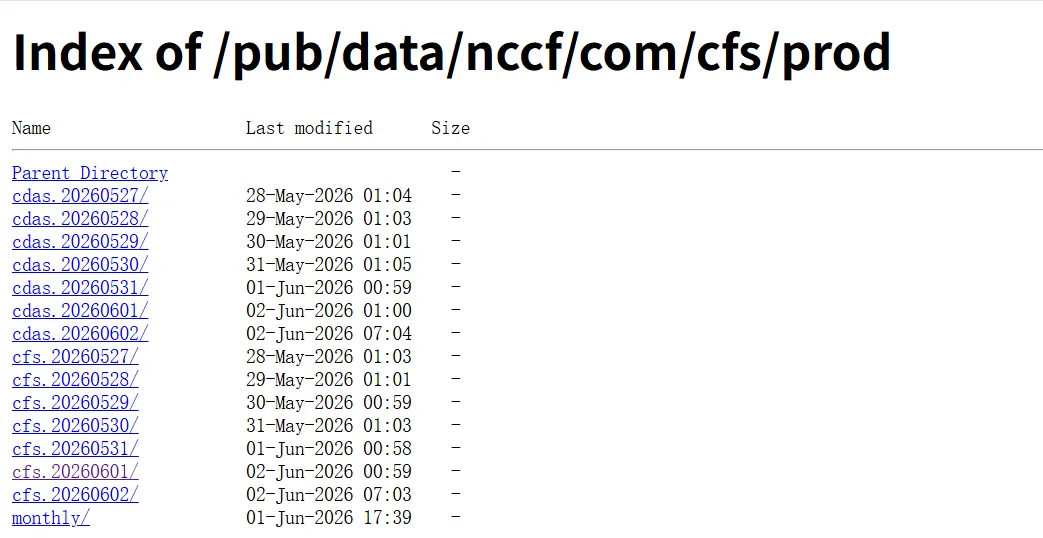
CFS数据通过NCEP的NOMADS(NOAA Operational Model Archive and Distribution System)服务器公开提供:
点击数据下载官网
文件名规则
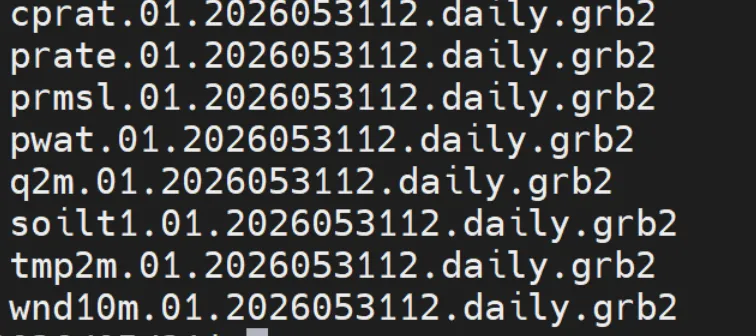
变量名.01.YYYYMMDDHH.daily.grb2
01表示预报成员(CFSv2仅一个成员)YYYYMMDDHH:起报时间和时次(HH=12)daily:日平均(对连续场)或日累积(对通量场)
手动下载
# 进入目标目录wget https://nomads.ncep.noaa.gov/pub/data/nccf/com/cfs/prod/cfs.20260531/12/time_grib_01/wnd10m.01.2026053112.daily.grb2
批量下载
date=20260531hour=12base_url="https://nomads.ncep.noaa.gov/pub/data/nccf/com/cfs/prod/cfs.${date}/${hour}/time_grib_01"for var in wnd10m prmsl cprat pwat tmp2m soilt1 q2m prate; dowget ${base_url}/${var}.01.${date}${hour}.daily.grb2done
python下载
#!/usr/bin/env python3"""CFS数据下载器 - 精简版从 NOAA NOMADS 服务器下载指定日期的CFS日平均/日累积GRIB2文件。支持断点续传、自动重试、本地按年/月/日目录归档。"""import osimport sysimport argparseimport requestsfrom datetime import datetime, timedeltafrom pathlib import Pathfrom typing import List, Optional# ==================== 配置区域(可根据需要修改) ====================DEFAULT_VARS = ['wnd10m', 'prmsl', 'cprat', 'pwat','tmp2m', 'soilt1', 'q2m', 'prate']BASE_URL = "https://nomads.ncep.noaa.gov/pub/data/nccf/com/cfs/prod"CYCLE_HOUR = 12 # 固定使用12 UTC循环(日平均数据最完整)LOCAL_ROOT = "./cfs_data" # 本地存储根目录RETRY_TIMES = 3TIMEOUT = 60# ================================================================def get_target_date(date_str: Optional[str]) -> datetime:"""解析日期参数,默认前一天"""if date_str:return datetime.strptime(date_str, '%Y%m%d')# 默认前一天(因为当天数据可能未完全生成)return datetime.now() - timedelta(days=1)def build_local_path(date: datetime, filename: str) -> Path:"""本地存储路径:LOCAL_ROOT/YYYY/MM/DD/filename"""target_dir = Path(LOCAL_ROOT) / date.strftime('%Y/%m/%d')target_dir.mkdir(parents=True, exist_ok=True)return target_dir / filenamedef build_remote_url(date: datetime, var: str) -> str:"""构建远程文件URL"""date_str = date.strftime('%Y%m%d')hour_str = f"{CYCLE_HOUR:02d}"filename = f"{var}.01.{date_str}{hour_str}.daily.grb2"url = f"{BASE_URL}/cfs.{date_str}/{hour_str}/time_grib_01/{filename}"return urldef download_file(url: str, local_path: Path) -> bool:"""下载单个文件(支持重试、临时文件保护)"""for attempt in range(1, RETRY_TIMES + 1):try:print(f"[{attempt}/{RETRY_TIMES}] 下载: {url}")resp = requests.get(url, stream=True, timeout=TIMEOUT)resp.raise_for_status()# 先写入临时文件,避免不完整文件tmp_path = local_path.with_suffix('.tmp')with open(tmp_path, 'wb') as f:for chunk in resp.iter_content(chunk_size=8192):f.write(chunk)tmp_path.rename(local_path)file_size = local_path.stat().st_sizeprint(f"成功: {local_path} ({file_size} bytes)")return Trueexcept Exception as e:print(f"下载失败: {e}")if attempt < RETRY_TIMES:wait = 2 ** (attempt - 1) # 指数退避: 1s,2s,4sprint(f"等待 {wait} 秒后重试...")import timetime.sleep(wait)print(f"最终失败: {url}")return Falsedef clean_old_files(days: int = 30):"""删除超过指定天数的本地CFS文件"""cutoff = datetime.now() - timedelta(days=days)deleted = 0for root, _, files in os.walk(LOCAL_ROOT):for f in files:if not f.endswith('.daily.grb2'):continue# 从文件名提取日期:变量.01.YYYYMMDDHH.daily.grb2parts = f.split('.')if len(parts) >= 4:date_part = parts[2][:8] # YYYYMMDDtry:file_date = datetime.strptime(date_part, '%Y%m%d')if file_date < cutoff:os.remove(os.path.join(root, f))deleted += 1except ValueError:passprint(f"清理完成: 删除 {deleted} 个超过 {days} 天的文件")def main():parser = argparse.ArgumentParser(description='CFS数据下载器(精简版)')parser.add_argument('-d', '--date', help='下载指定日期,格式 YYYYMMDD(默认前一天)')parser.add_argument('-v', '--vars', nargs='+', default=DEFAULT_VARS,help=f'要下载的变量名,默认: {" ".join(DEFAULT_VARS)}')parser.add_argument('--clean', type=int, metavar='DAYS', default=30,help='清理超过DAYS天的本地文件(默认30天)')parser.add_argument('--no-clean', action='store_true', help='跳过清理步骤')args = parser.parse_args()target_date = get_target_date(args.date)print(f"目标日期: {target_date.strftime('%Y-%m-%d')} (UTC+0, 循环时次 {CYCLE_HOUR:02d}Z)")success = 0total = len(args.vars)for var in args.vars:url = build_remote_url(target_date, var)local_path = build_local_path(target_date, url.split('/')[-1])if local_path.exists() and local_path.stat().st_size > 0:print(f"跳过已存在: {local_path}")success += 1continueif download_file(url, local_path):success += 1print(f"下载完成: 成功 {success}/{total}")if not args.no_clean:clean_old_files(args.clean)if __name__ == '__main__':main()
下载案例
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

