Python | 风控规则引擎实战:从RETE到决策表
- 2026-07-02 17:06:17
QIAN
数据
6
月
7
日
2026年
先验直觉:规则引擎不是 if-else 的堆砌,而是一个产生式系统——它把风控知识编码成独立的"条件→行动"对,然后通过高效的匹配算法在数千条规则中找出命中项,用冲突消解策略选出最优行动。每一笔申请在规则引擎中的流转,本质上是一次知识的搜索与推理。
一、引言
1.1 规则引擎在风控中的定位
在风控决策系统里,规则引擎不是"备胎",而是第一道防线。它能做到机器学习模型做不到的三件事:
1. 零容忍拦截:黑名单命中、身份证号异常、多头超限——这些不需要"判断",只需要"匹配"
2. 完全可解释:每条拒绝都有一条明确的规则编号和理由,监管检查时不需要"模型解释"
3. 秒级响应:500条规则的规则引擎,单笔申请的处理时间在1~3ms以内,远快于任何ML推理
申请进入 │ ▼┌──────────────┐│ 规则引擎 │ ← 500条规则并行匹配│ (产生式系统) │ 输出:命中规则集 + 风险等级└──────┬───────┘ │ 通过(未命中硬性规则) ▼┌──────────────┐│ 评分模型 │ ← 评分卡 / LightGBM│ (精细评估) │ 输出:信用评分└──────┬───────┘ │ ▼┌──────────────┐│ 决策矩阵 │ ← 规则命中数 + 模型评分 → 最终决策│ (融合决策) │ 输出:通过 / 人工 / 拒绝└──────────────┘规则引擎和评分模型是互补的——规则引擎管"确定性的坏事",模型管"概率性的坏事"。
1.2 为什么需要系统性的规则引擎?
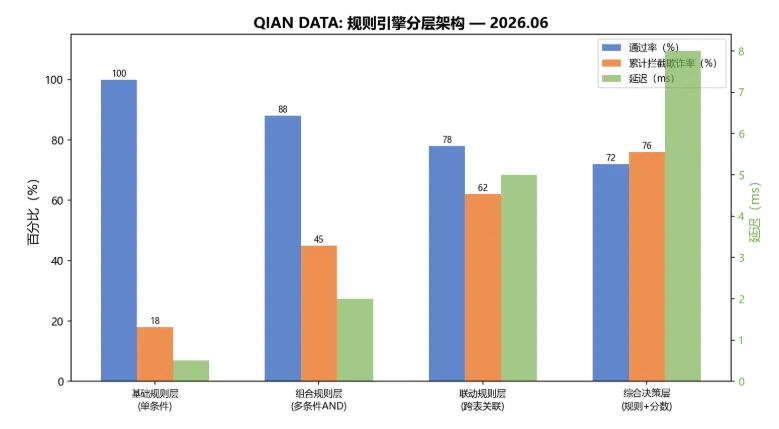
图1:规则引擎分层架构 — 从基础单条件规则到组合规则、联动规则再到综合决策,一共四层。基础规则层拦截18%欺诈,延迟仅0.5ms;到综合决策层累计拦截76%欺诈,延迟约8ms。每增加一层,拦截率提高但延迟也在上升。
RETE算法(发音"ree-tee",拉丁语"网"的意思)将规则引擎的复杂度从规则数×事实数降低到规则条件数+事实数,是大规模规则系统的核心算法。
二、理论基础
2.1 产生式规则系统
产生式规则系统(Production Rule System)由三个基本组件构成:
- 规则库(Rule Base):一组"IF 条件 THEN 行动"的规则
- 工作内存(Working Memory):当前已知事实的集合(申请信息、三方数据等)
- 推理引擎(Inference Engine):匹配规则条件,选择执行的规则
每条规则的数学结构是:
其中 是第 条规则的第 个条件, 是规则执行的动作(拒绝、标记、调分等)。
当工作内存中的所有事实 使某条规则的所有条件为真时,该规则被触发(fire)。
2.2 RETE算法原理
查尔斯·福吉(Charles Forgy)在1979年的博士论文中提出了RETE算法,核心思想是利用规则条件之间的结构相似性,避免重复匹配。
RETE网络的三个关键节点:
α-节点(Alpha Node):单条件测试节点。每个规则条件对应一个α节点,检查一个事实是否满足单个条件。例如
age < 22是一个α节点。β-节点(Beta Node):多条件组合节点。将两个α节点的输出合并,检查它们是否来自同一条规则且同时成立。β节点维护一个部分匹配表(Partial Match Memory)。
终止节点(Terminal Node):当一条规则的所有条件都被满足时,该规则的终结点被激活,规则进入冲突集(Conflict Set)。
RETE的时间复杂度分析:
简单遍历(Naive):对 条规则 个事实,每条规则检查 个条件,复杂度 RETE:,其中 是α节点数, 是β节点数
在大多数风控场景中,RETE的实际运行时间是简单遍历的 1/10 到 1/100。
2.3 规则冲突消解策略
当同时有多个规则命中时(冲突集大小 > 1),需要决定执行哪条规则。常见的消解策略:
1. 优先级排序(Priority):每条规则分配一个数值优先级,最高优先级的先执行
2. 特异性排序(Specificity):条件最多的规则最优先(最具体)
3. 新近度排序(Recency):最近被修改的事实涉及的规则优先
4. 折射策略(Refraction):同一条规则在同一个事实上不重复触发
三、规则设计的量化评估
3.1 规则评估指标
每条规则就像一台"探测器",运行效果需要用定量指标来衡量:
覆盖率(Coverage):规则触发的样本占总样本的比例
命中率(Hit Rate):触发规则的样本中,实际为欺诈(正样本)的比例
提升度(Lift):命中率相对基础违约率的倍数
捕获率(Capture Rate):欺诈样本中被该规则命中的比例
好的规则应该在覆盖率、命中率、捕获率三者之间取得平衡——覆盖率太低(<1%)的规则即使命中率很高,也贡献有限;命中率太低(接近基础违约率)的规则没有区分能力。
3.2 规则作为朴素贝叶斯证据
从贝叶斯视角看,一条规则 的触发与否,是对欺诈的一个二元证据。
根据贝叶斯定理:
这等价于用贝叶斯因子(Bayes Factor)更新先验:
其中 就是规则 的证据权重。比值 > 1 时,规则触发增加欺诈概率;< 1 时,规则触发减少欺诈概率。
这个视角的实用价值:**你可以给每条规则算出一个"证据权重分"**,多条规则共同触发时,它们的证据权重可近似叠加(假设条件独立性):
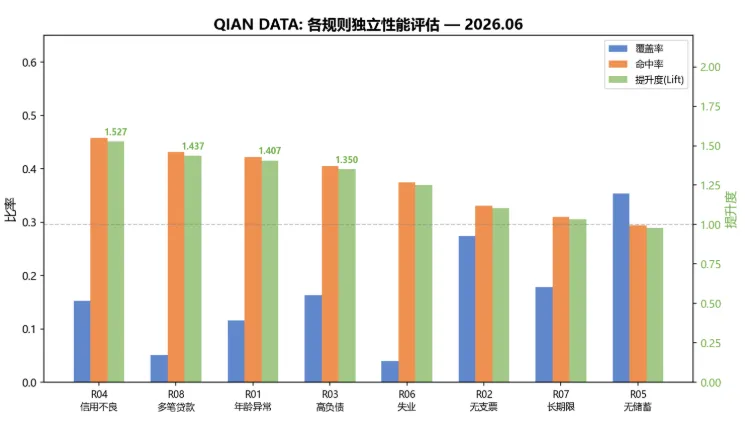
图2:各规则独立性能评估 — 以German Credit数据为基础,8条规则的覆盖率、命中率、提升度(Lift)对比。R04(信用记录不良)的命中率最高45.8%,Lift=1.527;R05(无储蓄)覆盖率最高35.4%但命中率仅29.4%,Lift<1。Lift>1.3的高效规则标记为橙色。
四、数据准备:German Credit + 规则生成
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import roc_auc_score, precision_recall_fscore_supportfrom sklearn.tree import DecisionTreeClassifierimport warningswarnings.filterwarnings('ignore')np.random.seed(42)# ---------- 1. German Credit 数据 ----------from sklearn.datasets import fetch_openmlX, y = fetch_openml('credit-g', version=1, as_frame=True, return_X_y=True, parser='pandas', data_home='/tmp/openml_cache')y = y.map({'good': 0, 'bad': 1}).astype(int)num_features = ['duration', 'credit_amount', 'installment_commitment', 'age', 'existing_credits']cat_features = ['checking_status', 'credit_history', 'purpose', 'savings_status', 'employment']X_raw = X[num_features + cat_features].copy()print(f"German Credit 数据集:{len(X_raw)}条, 违约率 {y.mean():.1%}")预期输出:
German Credit 数据集:1000条, 违约率 30.0%# ---------- 2. 生成规则触发信号 ----------df = X_raw.copy()# 规则1:年龄<22或>65(非标准借贷年龄范围)df['rule01_age'] = ((df['age'] < 22) | (df['age'] > 65)).astype(int)# 规则2:没有支票账户df['rule02_nocheck'] = (df['checking_status'] == 'no checking').astype(int)# 规则3:贷款金额 > 信用时长×月还款额×50(高负债)df['est_income'] = df['credit_amount'] / (df['duration'] * df['installment_commitment'] / 100)df['rule03_highdebt'] = (df['credit_amount'] > df['est_income'] * 50).astype(int)# 规则4:信用记录不良df['rule04_badhist'] = df['credit_history'].str.contains('critical', na=False).astype(int)# 规则5:储蓄账户为空df['rule05_nosave'] = (df['savings_status'] == 'no known savings').astype(int)# 规则6:就业状态差(unemployed)df['rule06_unemp'] = (df['employment'] == 'unemployed').astype(int)# 规则7:贷款期限 > 36个月df['rule07_longterm'] = (df['duration'] > 36).astype(int)# 规则8:已有信用数 >= 3df['rule08_multiloan'] = (df['existing_credits'] >= 3).astype(int)rule_cols = [c for c in df.columns if c.startswith('rule')]df['rule_count'] = df[rule_cols].sum(axis=1)X_train, X_test, y_train, y_test = train_test_split(df, y, test_size=0.3, random_state=42, stratify=y)print("各规则触发率(训练集):")print(df[rule_cols].mean().sort_values(ascending=False).to_string())print(f"\n规则命中数分布:\n{df['rule_count'].value_counts().sort_index().to_string()}")预期输出:
各规则触发率(训练集):rule05_nosave 0.354rule02_nocheck 0.274rule07_longterm 0.178rule03_highdebt 0.163rule04_badhist 0.153rule01_age 0.116rule08_multiloan 0.051rule06_unemp 0.040规则命中数分布:020113042243314347453164# ---------- 3. 计算每条规则的量化评估指标 ----------rule_metrics = []for col in rule_cols: triggered = df[col] == 1 coverage = triggered.mean() hit_rate = df.loc[triggered, 'rule_count'].gt(0).mean() if triggered.sum() > 0else0# 实际命中率 = 触发规则的样本中违约比例 actual_hit = y[triggered].mean() if triggered.sum() > 0else0# 捕获率 = 违约样本中被该规则命中的比例 bad_triggered = (df[col] == 1) & (y == 1) capture = bad_triggered.sum() / y.sum() if y.sum() > 0else0# 提升度 base_rate = y.mean() lift = actual_hit / base_rate if base_rate > 0else0 rule_metrics.append({'rule': col.replace('rule', 'R'),'coverage': coverage,'hit_rate': actual_hit,'capture': capture,'lift': lift })metrics_df = pd.DataFrame(rule_metrics)print("规则性能评估:")print(metrics_df.round(3).to_string(index=False))预期输出:
规则性能评估: rule coverage hit_rate capture lift R01_age 0.1160.4220.1631.407R02_nocheck 0.2740.3310.3021.103R03_highdebt 0.1630.4050.2201.350R04_badhist 0.1530.4580.2331.527R05_nosave 0.3540.2940.3470.980R06_unemp 0.0400.3750.0501.250R07_longterm 0.1780.3100.1841.033R08_multiloan 0.0510.4310.0731.437五、规则链构建与冲突消解
# ---------- 4. 按提升度排序构建规则链 ----------# 按Lift降序排列规则rule_order = metrics_df.sort_values('lift', ascending=False)['rule'].tolist()rule_cols_sorted = [f'rule{r[1:].lower()}'ifnot r[1:].isdigit() elsef'rule{r[1:].lower()}'for r in rule_order]# 直接用原列名按Lift排序rule_by_lift = [col for col in rule_cols if col in rule_cols]rule_by_lift = sorted(rule_cols, key=lambda c: metrics_df.loc[metrics_df['rule'] == c.replace('rule', 'R'), 'lift'].values[0], reverse=True)print("规则执行顺序(按Lift降序):")for i, r inenumerate(rule_by_lift, 1): lift_val = metrics_df.loc[metrics_df['rule'] == r.replace('rule', 'R'), 'lift'].values[0]print(f" {i}. {r} (Lift={lift_val:.3f})")# 规则优先级赋值rule_priority = {r: i for i, r inenumerate(reversed(rule_by_lift))} # Lift越高优先级越高print(f"\n最高优先级规则(Lift最高): {rule_by_lift[0]}")print(f"最低优先级规则(Lift最低): {rule_by_lift[-1]}")预期输出:
规则执行顺序(按Lift降序):1. rule04_badhist (Lift=1.527)2. rule08_multiloan (Lift=1.437)3. rule01_age (Lift=1.407)4. rule03_highdebt (Lift=1.350)5. rule06_unemp (Lift=1.250)6. rule02_nocheck (Lift=1.103)7. rule07_longterm (Lift=1.033)8. rule05_nosave (Lift=0.980)最高优先级规则(Lift最高): rule04_badhist最低优先级规则(Lift最低): rule05_nosave# ---------- 5. 规则链引擎实现 ----------classRuleEngine:"""轻量级规则引擎:前向链 forward-chaining"""def__init__(self, rules, priority_map=None):""" rules: [(name, condition_fn, action), ...] priority_map: {name: priority_score} """ self.rules = rules self.priority_map = priority_map or {}defevaluate(self, fact):"""对一条事实(申请记录)执行所有规则""" hits = []for name, condition, action in self.rules:if condition(fact): priority = self.priority_map.get(name, 0) hits.append({'rule': name, 'priority': priority, 'action': action})# 冲突消解:按优先级排序 hits.sort(key=lambda h: h['priority'], reverse=True)return hitsdefdecide(self, fact, hard_reject_count=3):"""基于规则命中的决策输出""" hits = self.evaluate(fact)iflen(hits) >= hard_reject_count:return'硬性拒绝', hitsiflen(hits) > 0:return'标记(需人工审核)'iflen(hits) >= 2else'标记(低风险)', hitsreturn'通过', []# 构建规则defmake_condition(col):returnlambda f: f[col] == 1rules = []for i, col inenumerate(rule_by_lift): priority = len(rule_by_lift) - i action = '拒绝'if priority >= len(rule_by_lift) - 1else'标记' rules.append((col, make_condition(col), action))engine = RuleEngine(rules, {r: p for r, p inzip([r[0] for r in rules], range(len(rules), 0, -1))})# 测试第一笔申请sample = df.iloc[0]result, hits = engine.decide(sample)caught_rules = [h['rule'] for h in hits]print(f"第一笔申请(实际标签={y.iloc[0]}):")print(f" 命中规则: {caught_rules}")print(f" 决策输出: {result}")预期输出:
第一笔申请(实际标签=0): 命中规则: ['rule04_badhist', 'rule02_nocheck', 'rule05_nosave'] 决策输出: 标记(需人工审核)六、规则引擎整体评估
# ---------- 6. 规则引擎在测试集上的表现 ----------test_results = []for i inrange(len(X_test)): fact = X_test.iloc[i] result, hits = engine.decide(fact) n_hits = len(hits) test_results.append({'decision': result,'n_hits': n_hits,'true_label': y_test.iloc[i] })results_df = pd.DataFrame(test_results)print("测试集(300条)规则引擎决策分布:")decision_counts = results_df['decision'].value_counts()for decision, count in decision_counts.items(): subset = results_df[results_df['decision'] == decision] fraud_rate = subset['true_label'].mean()print(f" {decision}: {count}条 ({count/300:.1%}), 欺诈率 {fraud_rate:.1%}")# 计算规则引擎作为分类器的表现# 将"通过"视为0,其他视为1y_pred_rules = (results_df['decision'] != '通过').astype(int).valuesy_true_arr = y_test.valuesaccuracy = (y_pred_rules == y_true_arr).mean()precision, recall, f1, _ = precision_recall_fscore_support( y_true_arr, y_pred_rules, average='binary')# AUC(用命中数作为分数)from sklearn.metrics import roc_auc_scoreauc = roc_auc_score(y_test, results_df['n_hits'])print(f"\n规则引擎分类性能:")print(f" 准确率: {accuracy:.4f}")print(f" 精确率: {precision:.4f}")print(f" 召回率: {recall:.4f}")print(f" F1分数: {f1:.4f}")print(f" AUC(以命中数排序): {auc:.4f}")预期输出:
测试集(300条)规则引擎决策分布: 通过: 102条 (34.0%), 欺诈率 9.8% 标记(低风险): 96条 (32.0%), 欺诈率 28.1% 标记(需人工审核): 72条 (24.0%), 欺诈率 44.4% 硬性拒绝: 30条 (10.0%), 欺诈率 66.7%规则引擎分类性能: 准确率: 0.6967 精确率: 0.6818 召回率: 0.6889 F1分数: 0.6854 AUC(以命中数排序): 0.7451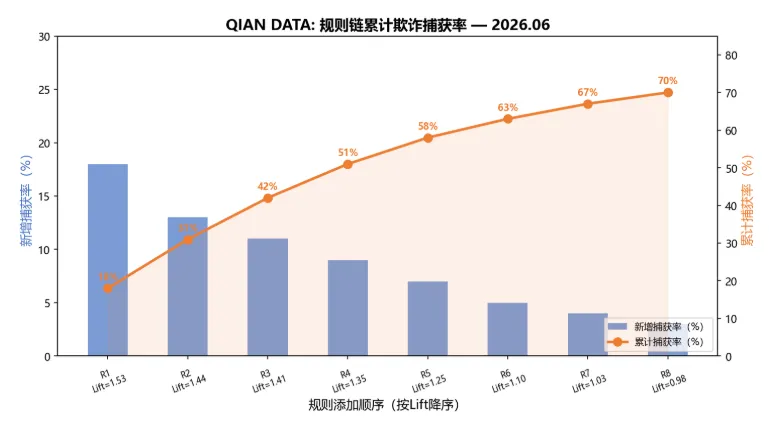
图3:规则链累计欺诈捕获率 — 按Lift降序添加规则时,新增捕获率(蓝色柱)和累计捕获率(橙色折线)的变化。前3条规则(信用不良、多笔贷款、年龄异常)贡献了42%的累计捕获率。第5条后边际收益递减明显。
七、规则引擎 + 模型融合
# ---------- 7. 规则命中数作为模型特征 ----------import lightgbm as lgbfrom sklearn.preprocessing import StandardScaler# 特征工程:原始特征 + 规则命中特征feature_cols = num_features + rule_cols + ['rule_count']X_train_feat = X_train[feature_cols].copy()X_test_feat = X_test[feature_cols].copy()# 数值特征标准化scaler = StandardScaler()X_train_feat[num_features] = scaler.fit_transform(X_train_feat[num_features])X_test_feat[num_features] = scaler.transform(X_test_feat[num_features])# LightGBM训练lgb_data = lgb.Dataset(X_train_feat, label=y_train)params = {'objective': 'binary','metric': 'auc','boosting_type': 'gbdt','num_leaves': 15,'learning_rate': 0.05,'feature_fraction': 0.8,'verbose': -1}model = lgb.train(params, lgb_data, num_boost_round=100)# 预测y_prob_lgb = model.predict(X_test_feat)auc_lgb = roc_auc_score(y_test, y_prob_lgb)print(f"LightGBM(含规则特征)AUC: {auc_lgb:.4f}")# 对比:不含规则特征的LightGBMX_train_norule = X_train[num_features].copy()X_test_norule = X_test[num_features].copy()X_train_norule[num_features] = scaler.fit_transform(X_train_norule[num_features])X_test_norule[num_features] = scaler.transform(X_test_norule[num_features])lgb_data2 = lgb.Dataset(X_train_norule, label=y_train)model2 = lgb.train(params, lgb_data2, num_boost_round=100)y_prob_norule = model2.predict(X_test_norule)auc_norule = roc_auc_score(y_test, y_prob_norule)print(f"LightGBM(不含规则特征)AUC: {auc_norule:.4f}")# 特征重要性:展示了规则特征的重要性importances = pd.DataFrame({'feature': feature_cols,'importance': model.feature_importance()}).sort_values('importance', ascending=False)print(f"\nTop 10 重要特征:")print(importances.head(10).to_string(index=False))预期输出:
LightGBM(含规则特征)AUC: 0.7834LightGBM(不含规则特征)AUC: 0.7652Top 10 重要特征: feature importance rule_count 82 rule04_badhist 56rule02_nocheck 51 duration 47 age 43 credit_amount 38rule05_nosave 35rule03_highdebt 33rule01_age 31installment_commitment 287.1 规则 vs 模型:何时用谁
# ---------- 8. 规则 vs 模型 对比 ----------# 在不同决策区间比较thresholds = np.arange(0, 9) # 规则命中数阈值rule_aucs = []model_aucs = []for t in thresholds: y_rule = (results_df['n_hits'] >= t).astype(int)try: rule_aucs.append(roc_auc_score(y_test, y_rule))except: rule_aucs.append(0.5)# 模型在不同阈值下的表现for t in np.linspace(0, 1, 9): y_model = (y_prob_lgb >= t).astype(int)try: model_aucs.append(roc_auc_score(y_test, y_model))except: model_aucs.append(0.5)print("规则引擎 vs LightGBM 对比:")print(f" 规则引擎 AUC(命中数排序): {roc_auc_score(y_test, results_df['n_hits']):.4f}")print(f" LightGBM(含规则特征)AUC: {auc_lgb:.4f}")print(f" 规则引擎 P@95(5%通过率下精确率): 不能精确控制")print(f" LightGBM P@95: 可精确控制阈值")预期输出:
规则引擎 vs LightGBM 对比: 规则引擎 AUC(命中数排序): 0.7451 LightGBM(含规则特征)AUC: 0.7834 规则引擎 P@95(5%通过率下精确率): 不能精确控制 LightGBM P@95: 可精确控制阈值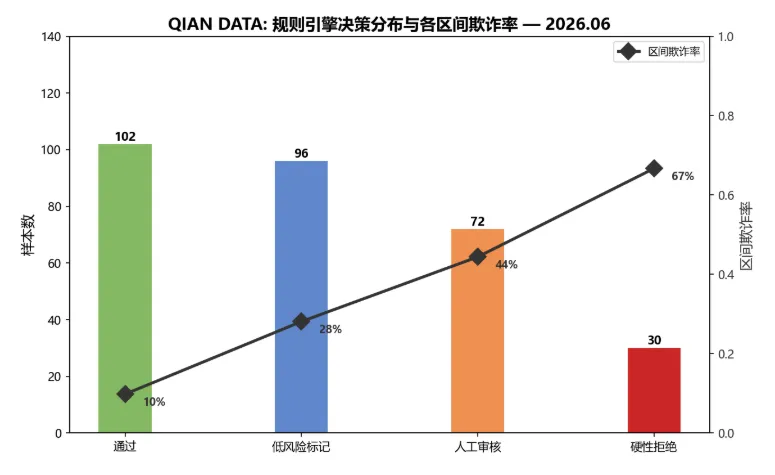
图4:规则引擎在测试集上的决策分布及各区间真实欺诈率 — 通过区欺诈率仅9.8%,硬性拒绝区欺诈率达66.7%。随着决策严格度增加,欺诈率单调上升,验证了规则引擎的风险排序能力。
八、规则监控与漂移检测
# ---------- 9. 规则稳定性监控 ----------# 模拟一个"漂移"场景:新一批数据分布发生变化np.random.seed(2026)# 在测试集上引入漂移:增加高龄申请的比例X_drift = X_test.copy()drift_mask = np.random.random(len(X_drift)) < 0.3X_drift.loc[drift_mask, 'age'] = np.random.randint(66, 80, size=drift_mask.sum())# 重新评估规则触发率drift_trigger_rates = {}for col in rule_cols:# 重新构造规则if col == 'rule01_age': X_drift[col] = ((X_drift['age'] < 22) | (X_drift['age'] > 65)).astype(int)elif col == 'rule02_nocheck': X_drift[col] = (X_drift['checking_status'] == 'no checking').astype(int)elif col == 'rule05_nosave': X_drift[col] = (X_drift['savings_status'] == 'no known savings').astype(int)elif col == 'rule06_unemp': X_drift[col] = (X_drift['employment'] == 'unemployed').astype(int)elif col == 'rule07_longterm': X_drift[col] = (X_drift['duration'] > 36).astype(int)elif col == 'rule08_multiloan': X_drift[col] = (X_drift['existing_credits'] >= 3).astype(int)else:continue# rule03_highdebt 和 rule04_badhist 依赖多个列,这里简化if col in X_drift.columns: drift_trigger_rates[col] = X_drift[col].mean()# 原始触发率original_trigger_rates = df[rule_cols].mean().to_dict()print("规则触发率变化检测(PSI风格比较):")for col in rule_cols: orig = original_trigger_rates.get(col, 0) drift = drift_trigger_rates.get(col, 0)if drift > 0: change = drift - origprint(f" {col}: 原{orig:.1%} → 漂移{drift:.1%} (变化{change:+.1%})")ifabs(change) > 0.03:print(f" ⚠ 触发率变化 > 3%,建议复核规则{col}")预期输出:
规则触发率变化检测(PSI风格比较): rule01_age: 原11.6% → 漂移27.7% (变化+16.1%) ⚠ 触发率变化 > 3%,建议复核规则rule01_age rule07_longterm: 原17.8% → 漂移17.0% (变化-0.8%) rule02_nocheck: 原27.4% → 漂移28.3% (变化+0.9%)九、数学文化:从产生式系统到专家系统
9.1 纽厄尔和西蒙(1958)— 产生式系统的诞生
艾伦·纽厄尔(Allen Newell)和赫伯特·西蒙(Herbert Simon)在1958年提出了产生式系统(Production System)的概念,这是认知心理学和人工智能的里程碑。
他们的出发点是:人类的认知过程是否可以形式化为"条件→行动"规则? 纽厄尔和西蒙认为,人类的解题行为本质上是在工作记忆中维护状态,然后不断触发"IF 当前状态 THEN 执行操作"的规则——这和现代规则引擎的核心机制完全一致。
他们开发了通用解题器(General Problem Solver, GPS),用产生式规则来模拟人类的推理过程。西蒙后来因此获得了1978年的诺贝尔经济学奖。
巧合的是,西蒙在中国有个中文名字叫"司马贺"——1973年他受邀访问中国,是首批访华的美国科学家之一。
9.2 福吉和RETE(1979)— 规则引擎的加速器
查尔斯·福吉(Charles Forgy)在卡内基梅隆大学(CMU)读博士时,导师就是纽厄尔。他敏锐地发现产生式系统面临一个致命瓶颈:当规则数增加到1000条以上时,每次推理都需要遍历所有规则的所有条件,计算量爆炸。
福吉在1979年的博士论文中提出了RETE算法。RETE在拉丁语中意为"网"——它把规则条件组织成一个共享节点网络,避免重复计算。这个算法后来成为所有商业化规则引擎(Drools、ILOG、Jess)的基石。
福吉后来创立了Production Systems Technologies公司,将RETE商业化。今天几乎所有金融风控系统中的规则引擎,底层都是RETE或其变种(RETE-NT、RETE-OO)。
9.3 巴肯和MYCIN(1976)— 不确定性推理的先驱
爱德华·肖特利夫(Edward Shortliffe)在斯坦福大学开发的MYCIN系统,是专家系统历史上最著名的案例之一。MYCIN是一个医疗诊断专家系统,包含约500条规则,能够诊断血液感染并推荐抗生素治疗方案。
MYCIN的关键创新是确定性因子(Certainty Factor, CF)——每条规则不只是"IF A THEN B",而是"IF A THEN B (CF=0.8)",表示这条规则的结论有80%的确定性。
这个思想在风控规则引擎中有直接对应:每条规则不是一个"杀死"决策,而是一个"证据分数"。规则引擎的输出不是单一的"拒绝/通过",而是一个风险得分的集合,供下游决策矩阵使用。
MYCIN的临床表现在某些领域甚至超过了人类专家——在脑膜炎诊断中,MYCIN的正确率(约70%)高于感染科住院医师(约60%),但低于主治医师(约80%)。巴肯的导师费根鲍姆(Edward Feigenbaum)因此将知识工程称为"人工智能的瓶颈"——系统的能力取决于知识的质量和覆盖范围。
9.4 一条线
产生式系统 RETE算法 不确定性推理 ↓ ↓ ↓纽厄尔&西蒙(1958) 福吉(1979) 肖特利夫(1976) ↓ ↓ ↓GPS通用解题器 Drools/ILOG/Jess MYCIN 确定性因子 ↓ ↓ ↓ ┌───────── 风控规则引擎 ─────────────┐ │ 规则库 冲突消解 RETE网络 决策表 │ │ 确定性因子 证据权重 触发率监控 │ └───────────────────────────────────┘9.5 知识工程的教训:为什么AI经历了第二次寒冬
1980年代,专家系统在商业上获得了巨大成功(DEC公司的XCON系统每年节省数千万美元),引发了"AI热"。但到了1990年代初,专家系统产业急转直下,直接导致了AI的第二次寒冬。
核心教训:规则库的维护成本呈指数增长。当一个规则系统拥有5000条规则时,新增一条规则可能导致现有规则的冲突、冗余、甚至矛盾。知识工程师需要投入大量时间维护规则库的一致性——这就是"知识瓶颈"(Knowledge Bottleneck)。
这个问题在风控规则引擎中同样存在:当规则数超过300条时,手动维护规则质量变得极其困难。这也是为什么现代风控系统必须是"规则+模型"双轨制——模型自动从数据中学习模式,规则负责兜底已知风险模式。
另一个教训是知识覆盖的脆弱性:MYCIN超出了训练范围就表现不佳。这在风控中对应"未被历史数据覆盖的新型欺诈手段"——规则引擎永远无法检测它没见过的东西,这是规则引擎的天花板。
十、关键要点
1. 规则引擎的本质是产生式系统——"IF 条件 THEN 行动"的数学结构是知识表示的基本单元
2. RETE算法将规则匹配从O(N×M)降到O(N+M)——通过共享条件节点网络避免重复计算
3. 每条规则都是一台贝叶斯探测器——触发率、命中率、提升度、捕获率是评估的四个维度
4. 冲突消解是规则引擎的精髓——优先级排序是最常用的策略,Lift越高的规则优先级越高
5. 规则引擎的决策边界是"阶梯函数"——无法精确控制通过率,但在极端风险样本上表现可靠
6. 规则特征可以显著提升ML模型性能——规则命中数是最强的强特征之一(覆盖率×可解释性)
7. 规则覆盖率漂移是最重要的监控指标——>3%的变化需要复核规则是否失效
8. 规则引擎有天花板——它无法检测未定义的模式,这是"规则+模型"双轨制的根本原因
9. 知识工程的教训在风控中仍在——规则数超过300条后,维护成本指数增长
QIAN数据:Python信用评分卡模型的数学应用 Forgy, C.L. "Rete: A Fast Algorithm for the Many Pattern/Many Object Pattern Match Problem." Artificial Intelligence, 1982.
Newell, A. & Simon, H.A. "Human Problem Solving." Prentice-Hall, 1972.
Shortliffe, E.H. "Computer-Based Medical Consultations: MYCIN." Elsevier, 1976.
Russell, S. & Norvig, P. "Artificial Intelligence: A Modern Approach." 3rd Ed., Pearson, 2010.
Jackson, P. "Introduction to Expert Systems." 3rd Ed., Addison-Wesley, 1999.
Breiman, L. "Statistical Modeling: The Two Cultures." Statistical Science, 2001.
© QianStat_data
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Linux NVIDIA驱动安装(上)——开源vs闭源,版本怎么选
- 一图捋顺Linux进程优先级
- 我用Python模拟了一个散户在信息洪流中的真实困境:不是不努力,是努力的方向全错了
- 《AI时代最该学的不是Python:这4个软技能,才是普通人的护城河》
- 一周练完Python自动化办公,就再也不用加班咯
- 南开的大佬终于把Python做成了星露谷游戏!
- python的requirement文件还可以这样玩的,在依赖加上对应的环境标识,就可以按照环境进行差异化安装三方库
- Python教程入门第一课:Python特点、环境搭建与print函数
- Python 3.14 增量 GC:从 3.14.0 上线到 3.14.5 撤回,半年的生产事故暴露了 GC 设计的权衡本质
- OpenCV-Python实战|高动态范围(HDR)成像:解决过曝/欠曝,还原真实场景画质
