文章目录
- 第 1 步:入口点与初始化 (`src/tui/app.py`)
- 第 3 步:查询执行 (`src/tui/query.py`)
- 第 4 步:引擎核心 (`src/core/engine.py`)
- 第 5 步:LLM 客户端 (`src/core/llm.py`)
- 系统提示 (`src/core/context.py`)
- 工具基类 (`src/core/tool.py`)
- 工具执行流程 (`src/core/engine.py`)
本文档对 claude-code-python 项目架构进行全面剖析,重点关注用户输入在系统中的完整流转过程。完整流程: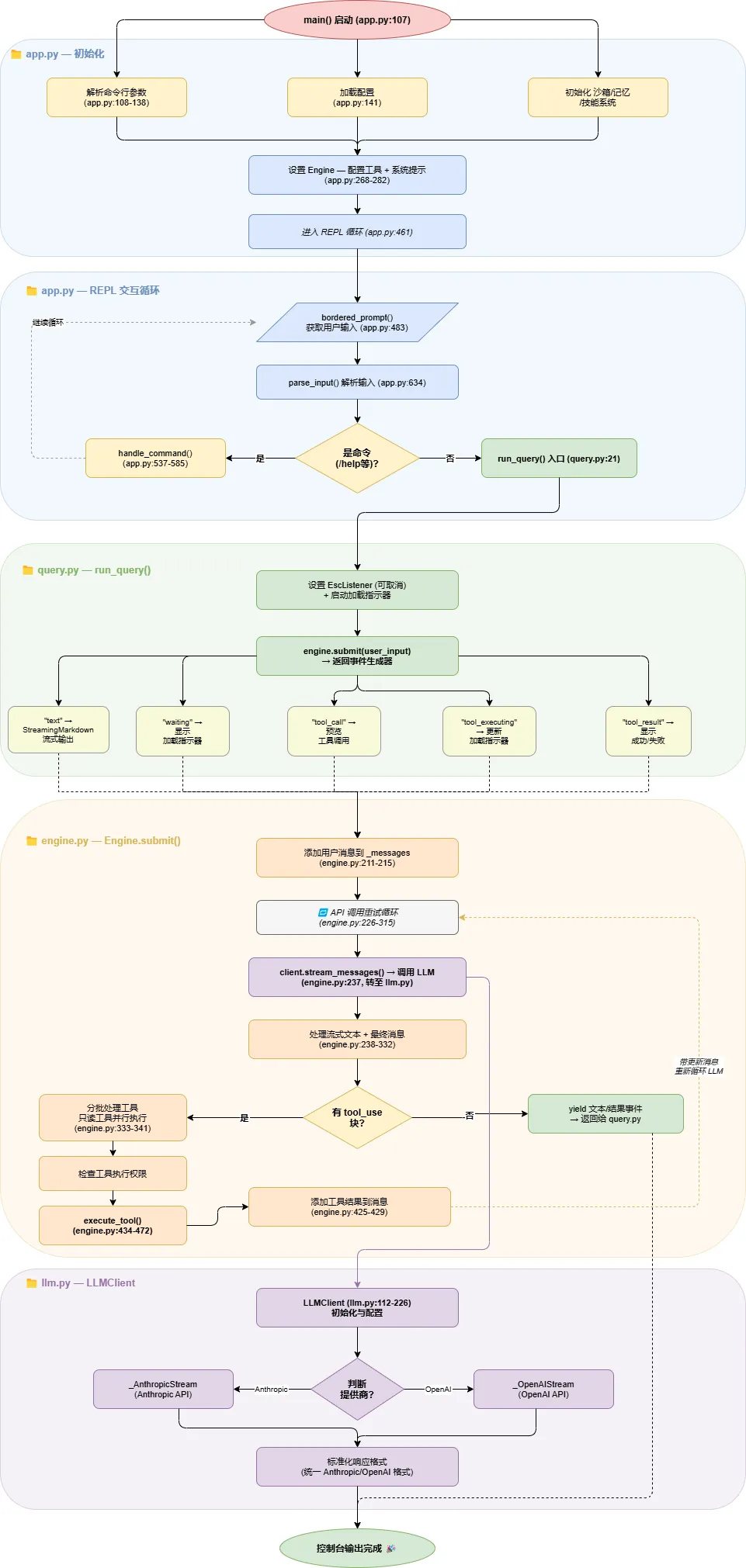 页面设计:
页面设计: 
1. 项目概述
claude-code-python 是一个用 Python 构建的极简 claude-code AI 编程助手。在节省token方面,做了改造,解决用户输入你好,就要花几w token的问题,项目具有以下特性:
2. 完整流程(用户输入 → 最终输出)
第 1 步:入口点与初始化 (src/tui/app.py)
应用从 app.py:107 的 main() 函数启动。它会:
解析命令行参数 (app.py:108-138)
加载配置 (app.py:141)
初始化沙箱、记忆、技能系统
设置 Engine,配置工具和系统提示 (app.py:268-282)
进入交互式 REPL 循环 (app.py:461)
第 2 步:用户输入处理
在交互式 REPL 中:
用户通过 bordered_prompt() 输入内容 (app.py:483-490)
使用 parse_input() 解析输入 (app.py:634)
如果是命令(/help、/buddy 等),通过 parse_command() 和 handle_command() 处理 (app.py:537-585)
否则,进入 run_query() 流程 (app.py:634)
第 3 步:查询执行 (src/tui/query.py)
run_query() (query.py:21-145) 协调整个回合:
第 4 步:引擎核心 (src/core/engine.py)
Engine.submit() (engine.py:195-432) 是主循环:
将用户消息添加到 self._messages (engine.py:211-215)
进入 API 调用重试循环 (engine.py:226-315)
通过 self._client.stream_messages() 调用 LLM (engine.py:237)
处理流式文本和最终消息
如果存在 tool_use 块:
- 分批处理工具(只读工具并行执行)(
engine.py:333-341) - 通过
self._execute_tool() 执行工具 (engine.py:434-472) - 将工具结果添加到消息中 (
engine.py:425-429)
第 5 步:LLM 客户端 (src/core/llm.py)
LLMClient (llm.py:112-226) 处理 API 通信:
3. 提示词构建逻辑
系统提示 (src/core/context.py)
build_system_prompt() (context.py:288-321) 组装以下部分:
静态部分:
_get_intro_section()_get_system_section()_get_doing_tasks_section()_get_actions_section()_get_using_tools_section()_get_tone_and_style_section()_get_output_efficiency_section()
动态部分:
_get_env_section()_get_git_section()_get_claude_md_section()
计划模式提示注入
当处于计划模式时 (features/plan.py):
4. 工具选择与执行机制
工具基类 (src/core/tool.py)
所有工具都继承自抽象 Tool 类 (tool.py:13-41):
class Tool(ABC): @property @abstractmethod def name(self) -> str: ... @property @abstractmethod def description(self) -> str: ... @property @abstractmethod def input_schema(self) -> dict: ... @abstractmethod def execute(self, **kwargs) -> ToolResult: ...
工具注册与模式
工具在 app.py 中通过 _build_tools_for_mode() 注册
每个工具的 to_api_schema() 转换为 LLM 兼容格式
模式包含 name、description、input_schema
工具执行流程 (src/core/engine.py)
LLM 返回 tool_use 块
引擎分批处理工具 (engine.py:333-341):
- 只读工具:并行执行(
ThreadPoolExecutor)
对于每个工具:
- 通过
PermissionChecker 检查权限 - 如获批准,发出
"tool_executing" 并调用 tool.execute(**input) - 发出带有
ToolResult 的 "tool_result"
将 tool_result 块添加到消息中并循环回到 LLM
5. 代码文件与关键函数参考
| | |
|---|
| 入口点 | src/tui/app.py | main() |
| 输入处理 | src/tui/query.py | run_query() |
| 引擎核心 | src/core/engine.py | Engine.submit() (195)、Engine._execute_tool() (434) |
| LLM 客户端 | src/core/llm.py | LLMClient.stream_messages() |
| 系统提示 | src/core/context.py | build_system_prompt() |
| 工具基类 | src/core/tool.py | Tool |
| 计划模式 | src/features/plan.py | PlanModeManager.enter() (110)、PlanModeManager.exit() (180) |
| 计划工具 | src/tools/plan_tools.py | EnterPlanModeTool |
6. 示例用户旅程
让我们通过一个简单的交互来完整走一遍流程:
用户输入:“读取 README.md”
app.py:REPL 获取输入,调用 parse_input(),然后调用 run_query(engine, "读取 README.md")
query.py:设置监听器,调用 engine.submit("读取 README.md")
engine.py:
- LLM 决定使用
Read 工具,参数为 {"file_path": "README.md"} - 引擎执行
FileReadTool.execute()
query.py:将摘要流式输出到控制台
app.py:触发伙伴观察者、提取记忆标签等
7. 技能系统
技能(Skills)是预定义的专业能力,用于处理特定类型的任务。
技能发现与注册
register_bundled_skills()discover_skills(cwd)build_skills_prompt_section()
技能提示注入
技能信息会被添加到系统提示中(app.py:174-175),使 LLM 了解可用的专业能力。
内置技能示例
项目包含多个预定义技能:
- LifeWisdomGuide: 基于 100+ 经典生活故事的逆向思维与处世智慧
- ai-life-post-writer
- frontend-design
8. 记忆系统层级结构
记忆系统采用 4 层架构,基于 src/features/memory.py 实现:
8.1 存储层(底层)
文件系统结构:
- 每日日志:
logs/YYYY/MM/YYYY-MM-DD.md - 追加式时间戳记录 - 记忆索引:
MEMORY.md - 不超过 200 行的索引文件,只包含链接+简短描述 - 结构化记忆文件:
*.md - 带 frontmatter 的记忆文件(name/description/type) - 会话持久化:
sessions/SESSION_ID.jsonl - JSONL 格式的完整会话记录
关键函数:
ensure_memory_dir()daily_log_path()save_session()
8.2 提取层(实时层)
实时记忆捕获:
<memory> 标签提取:extract_memory_tags() 自动从 LLM 响应中提取- 追加机制:
append_to_daily_log() 将提取的内容时间戳化后追加到当日日志
在 app.py 中的集成(第 688-690 行):
# Post-turn: extract <memory> tagstext = engine.last_assistant_text()for mem in extract_memory_tags(text): append_to_daily_log(memory_dir, mem)
8.3 整合层(梦境层)
4 阶段梦境整合流程:
表格转换结果
| | |
|---|
| | Glob 列文件、读 MEMORY.md、浏览现有记忆 |
| Phase 2 - Gather recent signal | | |
| | 合并新信号到现有文件、转换相对日期为绝对日期、删除矛盾事实 |
| Phase 4 - Prune and index | | 更新 MEMORY.md(<200 行、<25KB)、移除过期指针、添加新记忆 |
并发控制:
- 锁文件:
.consolidate-lock - 记录持有者 PID
自动触发条件(should_auto_dream()):
- 新会话数 ≥ min_sessions(默认 5 个)
8.4 访问层(接口层)
系统提示注入:build_memory_system_section() - 将记忆系统指令和 MEMORY.md 内容注入到系统提示中
4 种记忆类型:
| | |
|---|
user | | |
feedback | | |
project | | |
reference | | |
命令接口:
/dream/remember <text>/memory
9. 上下文压缩系统层级结构
上下文压缩系统采用 5 层架构,基于 src/features/compact.py 实现:
9.1 监控层
阈值判断:
关键函数:
estimate_tokens()should_compact() - 判断是否需要压缩(优先用 API 返回的实际 token 数)
在 app.py 中的集成(第 595-605 行):
# Auto-compact when approaching token limitsifshould_compact(engine.get_messages(), model=app_config.model, last_input_tokens=cost_tracker.last_input_tokens): console.print("[dim]Auto-compacting conversation…[/dim]") try: new_msgs, _ = compact_service.compact(...) engine.set_messages(new_msgs) ...
9.2 拆分层
消息智能拆分(_split_recent()):
| |
|---|
| |
| |
| tool_use / tool_result 配对 |
拆分逻辑:
- 如果切分点落在纯 tool_result 的用户消息上,往前多切一条(包含 tool_use)
9.3 处理层
预处理操作:
| | |
|---|
| _strip_media() | 将 image/document 块替换为 [image]/[document] 标记,节省 token |
| _fix_alternation() | 确保严格 user/assistant 交替,合并连续同角色消息 |
9.4 压缩层
LLM 摘要生成:
固定提示结构(COMPACT_PROMPT):
系统提示(COMPACT_SYSTEM):
- “你是一个对话摘要器。按照用户要求的格式生成结构化、详细的摘要。”
9.5 重组层
新消息列表构建:
[用户:摘要消息] ↓[助手:确认消息] ↓[近期保留的消息(6条+)]
摘要消息格式:
[This is a summary of the conversation so far — the original messages have been compacted to save context space.][结构化摘要内容]
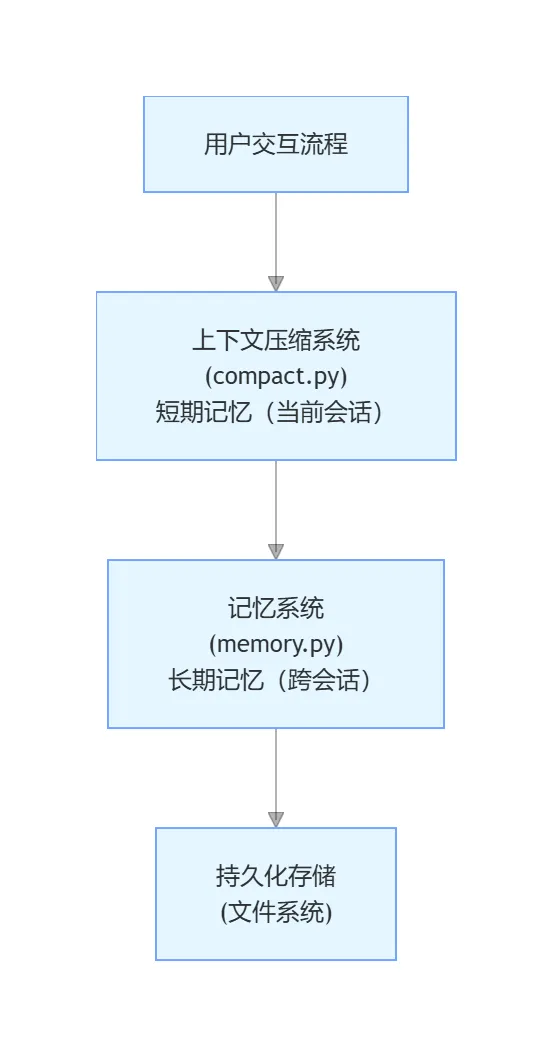
10. 记忆与压缩系统协作关系
维度对比表格
11. 工作模式总结
正常工作模式
用户输入 → 解析 → run_query()
Engine.submit() 添加消息 → 调用 LLM
LLM 生成响应(可能包含工具调用)
执行工具 → 添加结果 → 再次调用 LLM
循环直到无工具调用
输出最终响应
计划模式
用户触发计划模式 → EnterPlanModeTool 调用
PlanModeManager 保存状态 → 注入计划提示 → 切换到只读工具
LLM 探索代码库 → 编写计划文件
用户确认计划 → ExitPlanModeTool 调用
恢复原始状态 → 开始执行计划
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
