Python爬虫入门连载01:开篇介绍 + 环境准备 + 爬虫能做什么
恭喜学完 Python零基础22期 + 办公自动化10期!简单说:
不用手动复制粘贴,让代码自动去网页上抓取文字、图片、视频、资讯、商品数据。
一、Python爬虫到底是什么?
大白话解释:
模拟人打开浏览器,自动访问网页、自动把网页里的内容抓下来的程序,就是爬虫。你手动:打开网页→看内容→复制→保存
爬虫代码:自动访问→自动解析→自动抓取→自动保存
二、爬虫能做什么?
1. 资讯数据抓取
·抓取新闻头条、热点资讯
·抓取公众号文章、论坛帖子
·自动整理行业资讯
2. 电商商品抓取
·抓取商品名称、价格、销量
·自动比价、监控价格变动
·整理商品榜单数据
3. 图片壁纸爬取
·批量爬取壁纸、头像、表情包
·一键下载整页所有图片
4. 办公 & 数据分析
·批量采集公开网页表格数据
·自动保存为Excel,直接做分析报表
5. 学习 & 练手
练编程逻辑、练网络请求,提升Python实战能力非常快。
三、爬虫学习必备基础
你已经完全达标:
✅ 学完Python基础语法(变量、循环、列表字典、函数)
✅ 看得懂简单代码、会运行、会改参数
✅ 不用懂高深网络知识,跟着敲就能学会
零基础也能直接跟着本系列入门,全程实战、案例、手把手。
四、爬虫必备两大核心库安装
后续全程就靠这两个库:
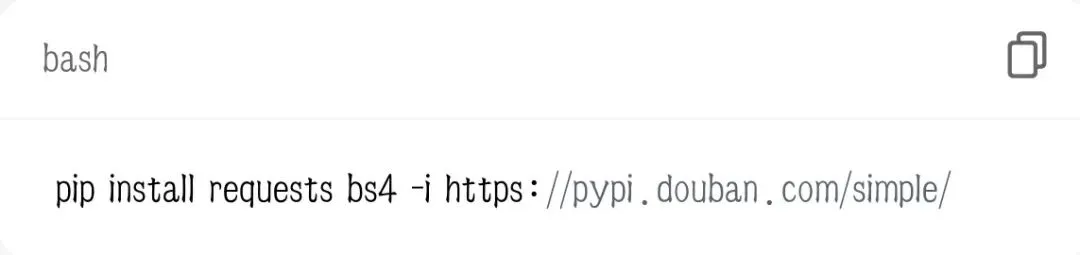
1.requests:发送网络请求,访问网页(相当于代码版浏览器)
2.bs4(BeautifulSoup):解析网页,提取想要的文字、图片、链接
打开 CMD / 终端,执行安装命令:
安装成功就可以开始写爬虫了。
五、爬虫法律与安全提醒(必看)
✅ 可以爬:公开、非隐私、非涉密的网页资讯、公开数据
❌ 不要爬:个人隐私、登录才能看的内容、付费资源、敏感网站
❌ 不要高频疯狂请求,给网站造成压力,合理礼貌爬取
我们全程只教学合规公开网页练手,安全合法学习。
六、本整套爬虫连载学习路线预告
1.环境准备 + requests库基础用法
2.零基础抓取网页源码
3.BeautifulSoup解析网页、提取文字/链接
4.爬取新闻标题、正文实战
5.批量爬取网页图片并自动下载保存
6.分页爬取:自动翻页抓取多页数据
7.爬取数据保存到Excel
8.简单伪装浏览器、反爬基础绕过
9.综合实战小项目:新闻爬虫、图片爬虫
全程不学废话理论,学一期、会一期、能用一期。
本期小结
1.爬虫就是代码自动抓取网页数据
2.可以抓新闻、商品、图片、公开资讯
3.必备库:requests、bs4,已安装好就能学
4.坚持合规爬取公开数据,不碰隐私和敏感内容
5.接下来从零开始手把手写第一个爬虫
下期预告
Python爬虫连载02:requests零基础入门,获取网页源代码教你用几行代码,自动访问网页、拿到完整网页源码,正式踏入爬虫大门!
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
