大家好,我是木木。
今天给大家分享一个高速的 Python 库,redis-py。
redis-py
redis-py 是 Redis 官方维护的 Python 客户端,也是很多缓存、队列和限流方案的基础入口。它支持连接池、pipeline、事务、Pub/Sub、Redis Cluster 和异步接口。写业务时,Redis 很容易被当成“更快的字典”,但真正上线要考虑 key 设计、超时、连接池、序列化和过期策略,这些才决定它稳不稳。
项目地址:https://github.com/redis/redis-py
官方文档:https://redis.readthedocs.io/en/stable/
三大特点
官方客户端
Redis 官方维护,接口覆盖面广,适合长期项目和生产服务。
连接复用
内置连接池和超时配置,高并发服务可以更好控制资源。
批量高效
pipeline 能减少往返次数,适合批量写入、计数和短事务。
最佳实践
安装方式:pip install redis。
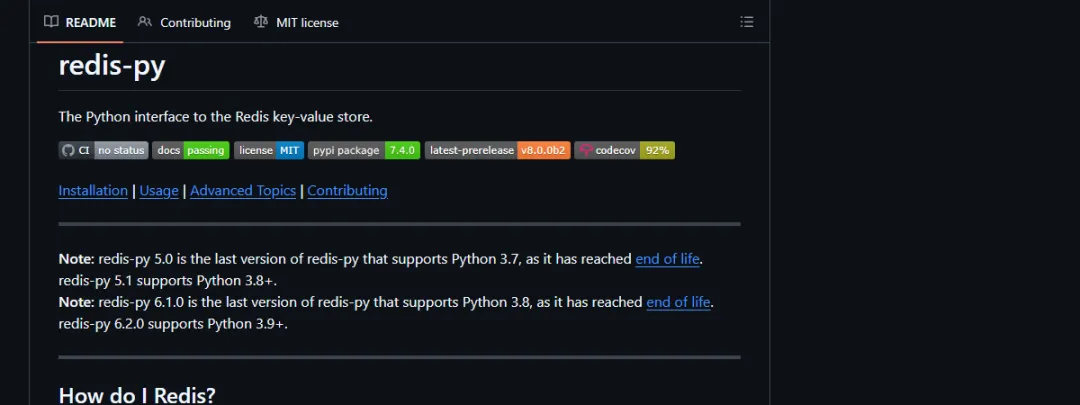
第一段代码解决的问题是:创建 Redis 客户端但不立即连接,先检查连接池参数、库编号和解码策略。
importredisfromimportlib.metadataimportversionclient=redis.Redis.from_url("redis://:secret@localhost:6379/2",decode_responses=True,health_check_interval=30,)kwargs=client.connection_pool.connection_kwargsprint("package:",version("redis"))print("host:",kwargs["host"])print("port:",kwargs["port"])print("db:",kwargs["db"])print("decode:",kwargs["decode_responses"])print("health check:",kwargs["health_check_interval"])
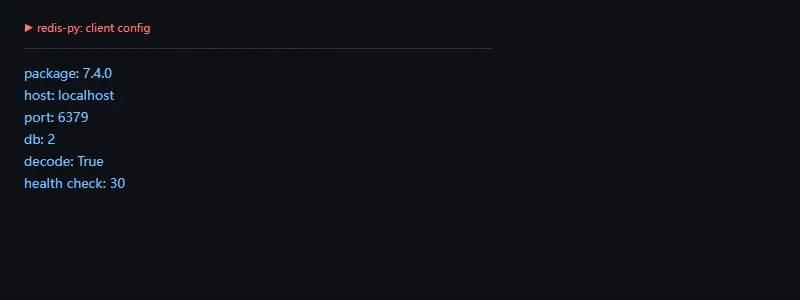
第二段代码解决的问题是:把多条命令先放进 pipeline,减少网络往返,并明确是否使用事务。
importredisclient=redis.Redis(host="localhost",port=6379,db=0,decode_responses=True)pipe=client.pipeline(transaction=True)pipe.set("user:42:name","Alice")pipe.expire("user:42:name",60)print("transaction:",pipe.transaction)print("queued:",len(pipe.command_stack))print("commands:",[cmd[0][0]forcmdinpipe.command_stack])
环境与版本信息
本文示例使用 Python 3.11,redis 7.4.0。示例只检查客户端配置、pipeline 队列和 key slot,不依赖真实 Redis 服务。
高级功能
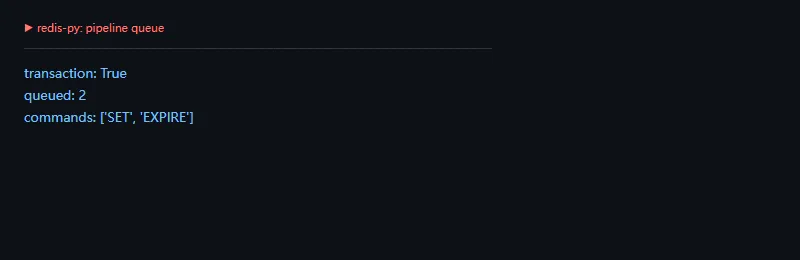
进阶一点看 Cluster key slot。带相同 hash tag 的 key 会落到同一个槽位,适合需要原子操作的相关数据。
fromredis.clusterimportkey_slotforkeyin["user:1000:name","user:{1000}:name","order:{1000}:items"]:print(key,"=> slot",key_slot(key.encode()))
适用场景
适合缓存、会话、排行榜、限流计数、任务状态、短期热点数据和 Redis Cluster 场景。
不适用场景
如果数据必须强一致、需要复杂查询或长期审计,Redis 不应该替代主数据库;大对象也不适合无节制塞进 Redis。
上线检查
- 所有客户端都设置 socket timeout 和连接池上限。
- Cluster 场景下提前设计 hash tag,避免跨槽操作失败。
总结
redis-py 简单但不随便。把连接池、pipeline、TTL 和 key 设计做好,它才会真正成为系统的加速层。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
