大家好,我是木木。
今天给大家分享一个轻快的 Python 库,duckdb。
duckdb
duckdb 是一个嵌入式分析型数据库,常被称作“分析场景里的 SQLite”。它不需要单独服务,Python 进程里就能直接执行 SQL、聚合数据、跑窗口函数,也能处理本地文件。对数据脚本、报表任务和探索分析来说,DuckDB 的体验非常顺滑;但它更偏 OLAP,不应该拿来替代高并发在线事务数据库。
项目地址:https://github.com/duckdb/duckdb
官方文档:https://duckdb.org/docs/stable/clients/python/overview
三大特点
嵌入运行
无需单独部署服务,Python 里 connect 就能跑 SQL。
分析友好
聚合、窗口函数和列式执行很强,适合本地数据分析。
文件直连
可直接读 Parquet、CSV 等文件,减少中间导入步骤。
最佳实践
安装方式:pip install duckdb。
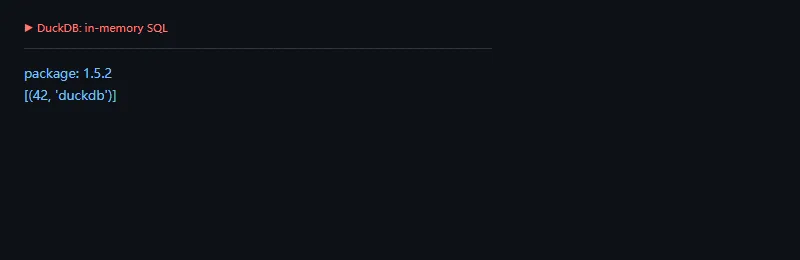
第一段代码解决的问题是:创建内存 DuckDB 连接,并验证 Python 里可以直接执行 SQL。
importduckdbfromimportlib.metadataimportversioncon=duckdb.connect(":memory:")print("package:",version("duckdb"))print(con.execute("select 42 as answer, 'duckdb' as engine").fetchall())
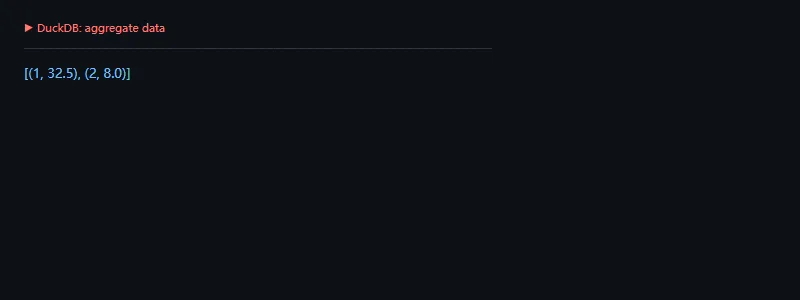
第二段代码解决的问题是:把小批数据写入表后,用 SQL 聚合出用户维度指标。
importduckdbcon=duckdb.connect(":memory:")con.execute("create table events(user_id integer, amount double, channel varchar)")con.executemany("insert into events values (?, ?, ?)",[(1,12.5,"web"),(2,8.0,"app"),(1,20.0,"web")],)rows=con.sql("select user_id, sum(amount) total from events group by user_id order by total desc").fetchall()print(rows)
环境与版本信息
本文示例使用 Python 3.11,duckdb 1.5.2。示例全部运行在内存数据库里,不依赖外部服务或文件。
高级功能
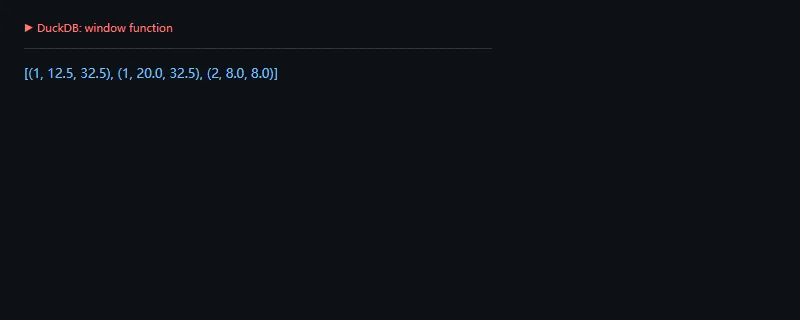
进阶一点看窗口函数。很多报表逻辑用 Python 循环写会变复杂,用 SQL 反而更清楚。
importduckdbcon=duckdb.connect(":memory:")con.execute("create table events(user_id integer, amount double, channel varchar)")con.executemany("insert into events values (?, ?, ?)",[(1,12.5,"web"),(2,8.0,"app"),(1,20.0,"web")],)rows=con.sql("select user_id, amount, sum(amount) over(partition by user_id) as user_total ""from events order by user_id, amount").fetchall()print(rows)
适用场景
适合本地数据分析、报表脚本、Parquet/CSV 探索、离线聚合和需要 SQL 表达力的数据处理任务。
不适用场景
如果业务是高并发在线写入、复杂权限管理或多服务共享事务,仍然应该选择 PostgreSQL、MySQL 等服务型数据库。
上线检查
- 生产任务固定 DuckDB 版本,避免 SQL 行为随版本变化。
总结
duckdb 的魅力是把 SQL 分析能力塞进一个轻量 Python 进程。做数据脚本时,它经常能少写很多胶水代码。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
