生成一个 10×10 的随机整数矩阵,元素范围在 1~100 之间。- 将矩阵的四周边缘(第一行,最后一行,第一列,最后一列)元素全部设为 0。
- 计算内部 8×8 子矩阵(即去除边缘后的矩阵)的最大值,最小值,平均值。
掩码(Mask) 通常指一个布尔型数组,其形状与原数组相同(或可广播),用于条件性地选择、标记或操作数组中的元素。arr = np.random.randint(1,101,(10,10))arr[:,0] = 0arr[:,-1] = 0arr[0,:] = 0arr[-1,:] = 0print(arr)arr1 = arr[1:-1,1:-1] #切片print("内部最大值:",np.max(arr1))print("内部最小值:",np.min(arr1)) print("内部平均值:",np.mean(arr1))print("大于50的元素个数:",np.sum(arr>50)) # 统计整个矩阵中大于 50 的元素的个数
编程题 2:基于广播的学生成绩标准化(广播+标准化)有一个 30 名学生、5 门课程的成绩矩阵 scores(30 行,5 列),每门课满分 100 分。- 对成绩进行标准化:(原始分 - 平均分) / 标准差,得到标准化后的矩阵(形状不变)。
- 将标准化后的成绩限制在 [-3, 3] 之间(小于 -3 的设为 -3,大于 3 的设为 3)。
scores = np.random.normal(75,10,(30,5))#1.计算课程和平均分标准差 mean_per_course = np.mean(scores,axis = 0)std_per_course = np.std(scores,axis = 0)print('每门课程平均分:',mean_per_course)print('每门课程标准差:',std_per_course)#2.标准化:normalized = (scores-mean_per_course)/std_per_courseprint(normalized)#3.裁剪到[-3, 3]normalized_clipped = np.clip(normalized,-3,3)print(normalized_clipped)#4.输出标准化且裁剪后形状和前两行数据 print(normalized_clipped.shape) #shape在NumPy中是一个属性,不是方法,因此.shape不需要加括号 print(normalized_clipped[:2,:])
注:shape在NumPy中是属性,不是方法,因此.shape不需要加括号;normalized_clipped=np.clip(normalized,-3,3) : 裁剪方法,将normalized裁剪到[-3, 3]编程题 3:使用掩码筛选并修改数组(掩码+索引)
创建一个一维数组 data,包含 200 个随机整数,范围 0~100。- 找出数组中所有能被 3 整除但不能被 5 整除的数的索引位置。
- 统计替换后数组中仍大于 50 的元素个数,并输出这些元素的和。
data = np.random.randint(0,100,200)mask = (data%3==0)&(data%5!=0)print('满足条件的索引:',np.where(mask))data[mask] = -1print(data)mask1 = data>50print('大于50的个数是:',np.sum(mask1))print('大于50的和是:',np.sum(data[mask1]))
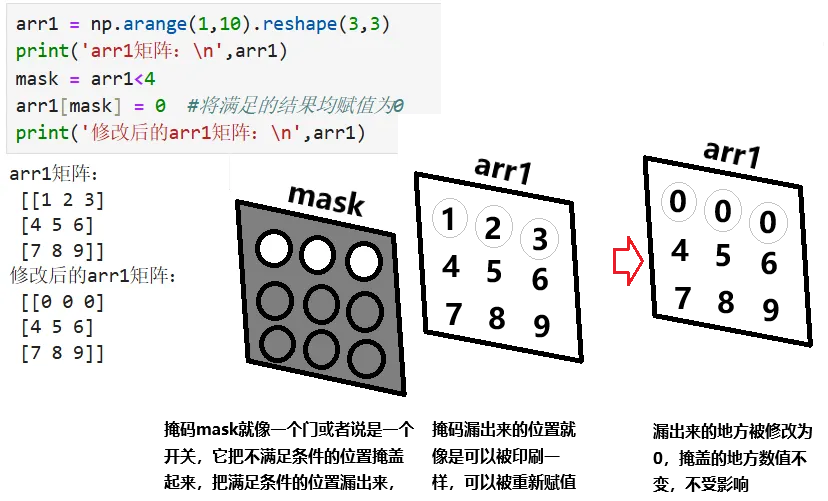
注:掩码mask是一种布尔数组,是对原数组的每个元素的一种判断,它的形状和原数组相同,不同的是它的每个元素只有True 或者False两种,我画了以下图示以增强对掩码的理解:给定两个矩阵 A (3×4) 和 B (4×2),元素均为随机浮点数(范围 0~1)。- 计算矩阵乘积 C = A @ B(即 np.dot(A, B))。
- 计算 D = A * B(这里会出错,请说明原因并修正,使得 A 和 B 可以逐元素相乘)。(提示:需要调整矩阵的形状,利用广播机制)
a = np.random.rand(3,4)b = np.random.rand(4,2)c = np.dot(a,b)a = a.reshape(1,12) #这里必须赋值因为直接reshape不改变原数组的值b = b.reshape(8,1) #这里必须赋值因为直接reshape不改变原数组的值d= a*bprint(d)
注:在 NumPy 中生成随机浮点数最常用的方法有几种,区别在于分布和形状。下面列出最实用的函数:- np.random.rand(3,2):3行2列的均匀浮点数,均匀分布在[0,1)区间,参数是各维度长度(形状)
- np.random.random((3,2)):作用和上面一样,3行2列均匀分布在[0,1)区间的浮点数,不同点在于参数是一个size元组指定形状。
- np.random.uniform(2,5,size = (2,3)):[2,5)区间的浮点数,形状(2,3)
- np.random.randn(100):标准的正态分布,均值为0,方差为1, 100指数据量
- np.random.normal(loc=5,scale=2,size=(10,)):可自定义均值和标准差的正态分布,这里表示:均值5,标准差2,10个值的数组。
模拟 10000 次抛硬币(0 表示反面,1 表示正面)。- 计算连续出现 5 个及以上正面的次数(即 5 个或更多连续的 1 为一组,每组只计一次)。(提示:可以使用卷积或遍历差分法)
方案1:连续为1可以理解成相邻两个值和为2,不为2了就代表不连续了import numpy as nparr1 = np.random.randint(0,2,10000) print(np.sum(arr1))num = 0active = 0time = 0for num in range(0,len(arr1)-1): b = arr1[num]+arr1[(num+1)] if b==2: active += 1 else: if active >=4: time += 1 active = 0print(time)
import numpy as np# 1. 抛硬币结果flips = np.random.randint(0, 2, 10000)# 2. 查找连续5个及以上正面的次数# 方法:对数组进行差分,标记连续块的开始和结束# 为方便处理,在头尾加0padded = np.concatenate(([0], flips, [0]))diff = np.diff(padded)starts = np.where(diff == 1)[0] # 从0变1的位置ends = np.where(diff == -1)[0] # 从1变0的位置lengths = ends - startscount_long = np.sum(lengths >= 5)print("出现连续5个及以上正面的次数:", count_long)# 3. 正面比例与0.5的误差prob_heads = np.mean(flips)error = abs(prob_heads - 0.5)print("正面比例:", prob_heads)print("与0.5的绝对误差:", error)
以上五组简单的NumPy相关的编程题用以加强对NumPy语法的理解,是上一篇NumPy基础知识篇的一个补充。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
