Python爬虫入门连载03:BeautifulSoup解析网页,提取标题、文字、超链接
上一期我们用 requests 拿到了整页密密麻麻的网页源码今天教大家爬虫第二核心神器:BeautifulSoup(bs4)作用就是:
把杂乱的HTML源码格式化、拆解,精准提取我们想要的标题、正文、链接、图片地址。
一、BeautifulSoup 作用大白话
·requests:负责敲门、拿到整页源码
·BeautifulSoup:负责拆房子、挑出你想要的家具(标题、文字、链接)
分工明确,爬虫标配组合。
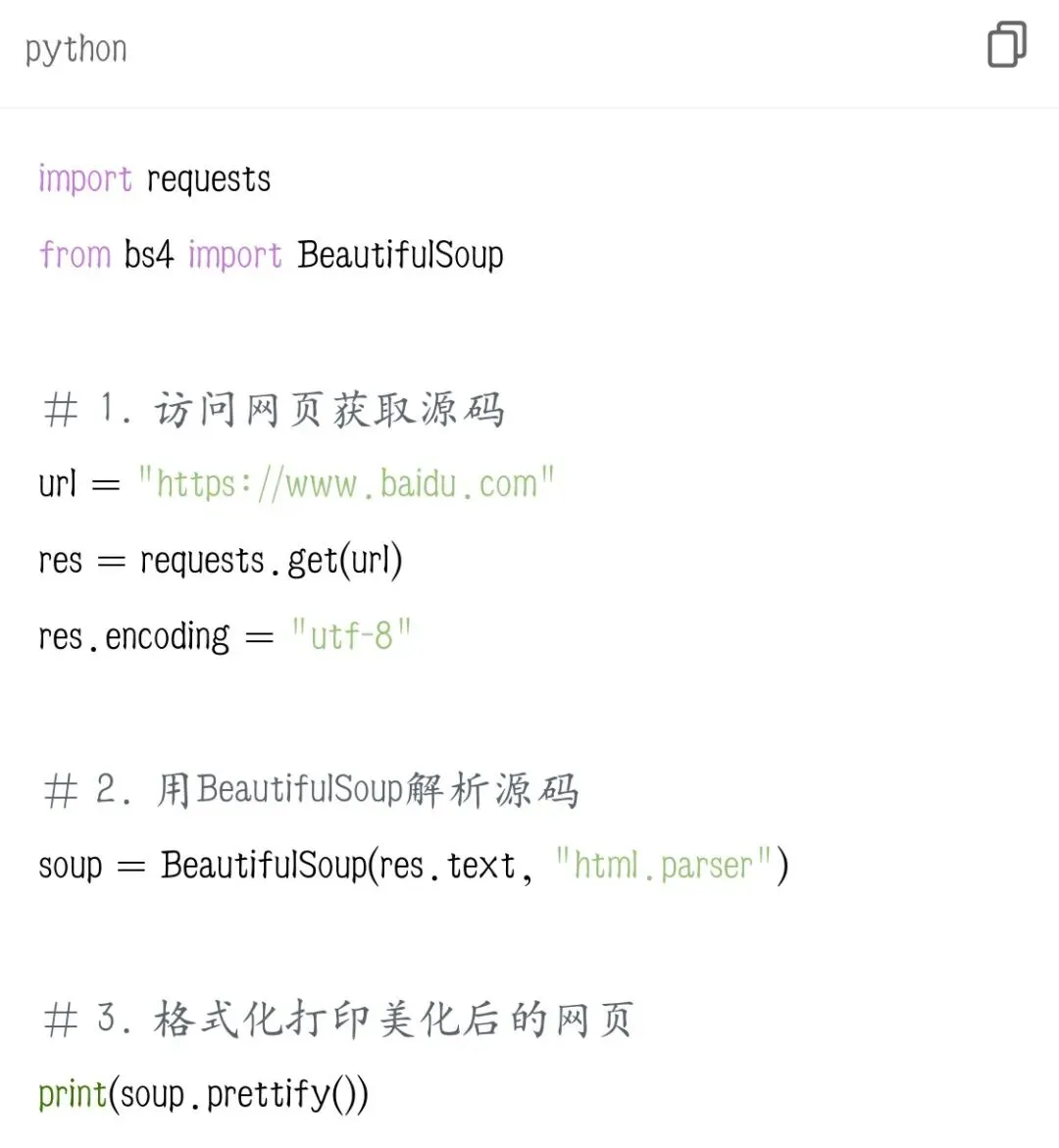
二、导入库 + 基础解析流程
固定三步走
1.requests 获取网页源码
2.用 BeautifulSoup 加载源码
3.通过标签、类名查找提取内容完整基础代码
·html.parser:Python自带解析器,不用额外装插件
·soup.prettify():把杂乱代码自动缩进排版,看着很清晰
三、四大常用查找方法(必记)
1. find() 找第一个匹配标签
2. find_all() 找所有匹配标签,返回列表
3. 获取标签里面的文字 .text
4. 获取标签里的属性 比如链接href
四、实战:提取网页所有超链接+文字
完整可直接运行:
运行效果:
自动把页面所有可点击链接、链接文字全部抓取打印出来。
五、按 class 类名精准查找(最常用)
网页很多标签名字一样,只能靠class类名区分:
语法:
示例:
注意:
class 是Python关键字,所以要用 class_ 带下划线。
六、新手必记核心口诀
1.BeautifulSoup(源码, "html.parser") 生成解析对象
2.find() 拿第一个,find_all() 拿全部
3..text 拿标签内纯文字
4.["href"] 拿链接、地址等属性
5.按类名查找:class_="类名"
七、新手避坑
❌ 标签名大小写不能乱,网页是小写就写小写
❌ class类名要和网页源码里完全一模一样
❌ 相对链接不是完整网址,后面要拼接域名
❌ 不要乱复制多余空格,匹配会失败
本期小结
1.bs4 用来解析HTML、精准提取内容
2.find / find_all 是最核心两个方法
3..text 取文字,["href"] 取链接
4.支持按标签、按class类名精准筛选
5.可以批量提取整页标题、链接、文本
小作业
找一个新闻首页,用代码爬取页面所有新闻标题和对应链接,打印出来。
下期预告
Python爬虫连载04:实战爬取新闻标题+正文,保存到文本文件手把手完整案例:爬取一条新闻的标题、正文,自动保存成txt文档,真正做完整爬虫流程!







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
