Python爬虫入门连载04:实战爬取新闻标题+正文,保存到文本文件
前面我们已经掌握:
·requests 访问网页拿源码
·BeautifulSoup 解析网页、提取标签、文字、链接今天直接来完整实战案例:
从零写一个新闻爬虫,爬取新闻标题 + 新闻正文并且自动保存到本地 txt 文本文件,走完「请求→解析→提取→保存」完整爬虫流程。
一、本次爬虫完整流程
1.目标新闻网页地址
2.requests 发送请求获取源码
3.BeautifulSoup 解析网页
4.精准提取:新闻标题、新闻正文
5.去掉多余空行、空格
6.自动保存到本地 txt 文件
二、选一个简单适合练手的新闻页
我们用公开新闻网页做教学,合规练手:
示例思路通用,你换任意新闻网址都能用。
三、完整可直接运行源码
四、关键知识点讲解
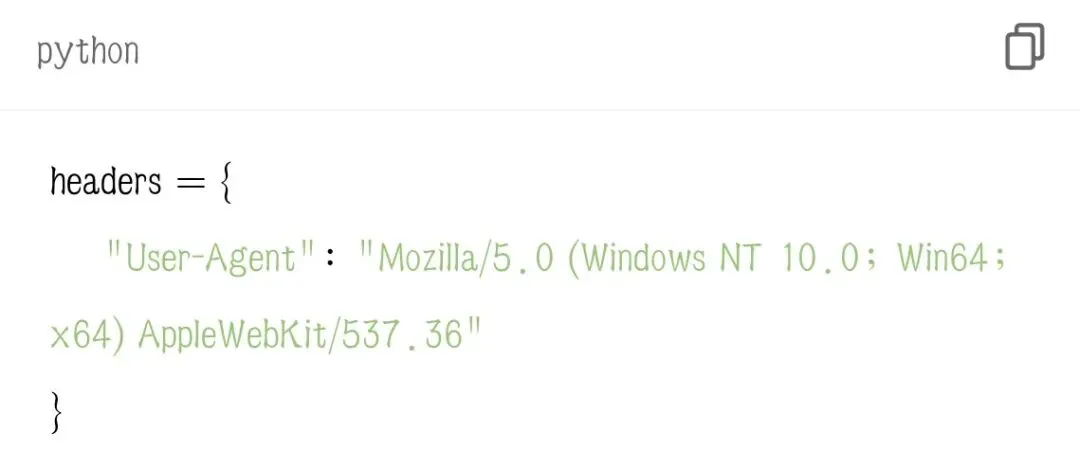
1. 加请求头 headers 伪装浏览器
很多网站直接爬虫访问会拒绝,加上 User-Agent 伪装成真实浏览器:
以后写爬虫必加,防拦截基础操作。
2. 提取网页标题
所有网页都有 title 标签,直接拿就是网页标题。
3. 批量抓取所有正文段落 p 标签
新闻正文大多都放在 <p> 标签里,
循环取出每一段文字,拼接成完整正文。
4. 保存到 txt 文件
指定 encoding="utf-8" 防止保存后中文乱码。
五、遇到不同网页怎么适配?
1.右键网页 → 检查元素
2.看标题在哪个标签、哪个 class
3.把 soup.find() 里的标签和类名改成对应即可
套路完全一样,只是标签名字稍微改一下。
六、新手常见问题
❌ 不加 headers,容易被网站拦截访问
❌ 保存文件不指定 utf-8,中文乱码
❌ 不 strip() 导致文字有大量空格空行
❌ 复制别人网址少了 http/https,请求报错
本期小结
1.爬虫标准流程:发请求 → 解析 → 提取 → 保存
2.加 User-Agent 伪装浏览器,基础反爬必备
3.title 取标题,p 标签批量取正文
4.循环拼接正文,过滤空行空格
5.一键自动保存为本地 txt 文档
小作业
换一个你喜欢的公开新闻网址,改写代码,爬取标题和正文并保存为新的txt文件。
下期预告
Python爬虫连载05:批量爬取网页图片,自动下载保存到本地文件夹不用手动另存为,代码一键爬取整页所有图片、自动新建文件夹、批量下载保存!



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
