Linux 磁盘分区、挂载与磁盘读写异常排查流程
- 2026-06-29 19:34:49
写在前面
磁盘是 Linux 服务器上"出问题最多、影响最大、也最容易被忽视"的组件。新人排查故障容易陷入两个极端:
看到 No space left on device就rm -rf删日志,结果把业务数据也删了。看到 IO 慢就换盘,结果是文件系统参数或内核脏页配置问题。
这篇文章把磁盘相关的内容拆成三块:
基础:分区、文件系统、挂载、LVM、SWAP、卷标。 排查:磁盘 IO 慢、磁盘满、inodes 耗尽、磁盘只读、SMART 报警。 实战:5 个真实生产故障案例的完整闭环。
读完能落地的事情:
看懂 fdisk -l、lsblk、blkid、df -h、du -sh的输出。区分 MBR / GPT、ext4 / xfs、逻辑卷 / 物理盘。 在不丢数据的情况下做扩容、修复、紧急下线。 拿到一份能直接执行的排错 Runbook。
适用读者:负责 Linux 服务器日常运维的初中级工程师、DBA、DevOps。
一、磁盘与分区基础
1.1 块设备到底长什么样
Linux 把"磁盘"抽象为块设备(block device),统一在 /sys/block/ 下:
# 块设备清单
ls -l /sys/block/
# sda sdb nvme0n1 loop0 dm-0 ...
# 含义
# sda, sdb: SCSI / SATA 盘,第一、二块
# nvme0n1: NVMe 盘
# dm-0: device mapper,多用于 LVM / LUKS
# loop*: loop 设备,挂 ISO / img 文件
每块物理盘又可以划分分区(partition),分区表两种主流格式:
MBR(Master Boot Record):传统格式,支持最多 4 个主分区,单盘最大 2 TiB。 GPT(GUID Partition Table):UEFI 时代格式,分区数几乎无限,单盘最大 18 EiB(Zettabyte)。
风险提示:2 TiB 限制是 MBR 的硬伤。盘 ≤ 2T 还能用 MBR,> 2T 必须 GPT,否则只能识别前 2T。
1.2 磁盘工具一览
# 列出所有块设备
lsblk
# NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
# sda 8:0 0 200G 0 disk
# ├─sda1 8:1 0 1G 0 part /boot
# ├─sda2 8:2 0 100G 0 part /
# └─sda3 8:3 0 99G 0 part /data
# sdb 8:16 0 500G 0 disk
# nvme0n1 259:0 0 1.8T 0 disk
# └─nvme0n1p1 259:1 0 1.8T 0 part /data2
# 看磁盘型号、容量、是不是 SSD
lsblk -d -o NAME,SIZE,MODEL,ROTA,TRAN
# ROTA 1: 机械盘
# ROTA 0: SSD / NVMe
# TRAN: 传输类型 (sata, nvme, usb, ...)
# 看磁盘详情
fdisk -l /dev/sda
# 看分区表类型(gpt / dos)
parted /dev/sda print | grep "Partition Table"
# Partition Table: gpt
# 看 UUID 和 LABEL
blkid
# /dev/sda1: UUID="xxx-xxx" TYPE="ext4" PARTUUID="..."
# /dev/sda2: UUID="yyy-yyy" TYPE="xfs" PARTUUID="..."
# 看具体磁盘的 SMART
smartctl -i /dev/sda
smartctl -A /dev/sda
lsblk 是日常最常用的工具,能看到整块盘、分区、LVM、loop 的层级关系,比 fdisk -l 直观。
1.3 扇区、块、页
这块很多人搞混:
扇区(sector):磁盘的最小读写单位,传统 512 字节,Advanced Format 4K。 块(block):文件系统层面的最小单位,常见 4 KB。 页(page):内核的内存管理单位,常见 4 KB。
fdisk -l 默认按 512 字节扇区显示大小,文件系统的 block size 可以独立配置。
# 看文件系统 block size
xfs_info /dev/sda1
# ...
# data = bsize=4096
# ...
tune2fs -l /dev/sda1 | grep "Block size"
# Block size: 4096
block size 不是越大越好:
大 block:吞吐高、顺序 IO 快,但小文件浪费空间。 小 block:节省空间,但元数据多、IO 放大。
二、分区工具实战
2.1 fdisk
fdisk 是 MBR 时代的分区工具,只支持 MBR,单盘 ≤ 2T 还能用。
# 交互式
fdisk /dev/sdb
# 命令:m(帮助), p(打印分区表), n(新建), d(删除), t(改类型), w(写入), q(不保存退出)
# 命令行模式
fdisk -l /dev/sdb
新建一个分区示例:
# 1. 进交互
fdisk /dev/sdb
# 2. 创建主分区
Command: n
Partition type: p # primary
Partition number: 1
First sector: 2048 # 默认
Last sector: +100G # 100G 大小
# 3. 改类型(可选,Linux 默认 83)
Command: t
Partition type: 8e # Linux LVM
# 4. 写盘
Command: w
风险提示:w 写盘是不可逆操作,会重写分区表。生产环境操作前必须确认盘符正确,先 fdisk -l /dev/sdb 看一遍。如果有数据,先 df -h 看盘是否挂载了,正在使用的盘不能改分区表。
2.2 gdisk
gdisk 是 GPT 时代的分区工具,替代 fdisk 的 GPT 版本。
# 安装
yum install -y gdisk
apt-get install -y gdisk
# 使用
gdisk /dev/sdc
# ? # 帮助
# o # 建新 GPT
# n # 新建分区
# p # 打印
# w # 写入
新建分区示例:
gdisk /dev/sdc
# 1. 新建 GPT
Command: o
This option deletes all partitions and creates a new GPT.
Proceed? (Y/N): Y
# 2. 新建分区
Command: n
Partition number: 1
First sector: 2048
Last sector: +500G
Hex code or GUID: 8300 # Linux filesystem
# 3. 写入
Command: w
Do you want to proceed? (Y/N): Y
2.3 parted
parted 同时支持 MBR 和 GPT,是脚本化分区的首选。
# 装
yum install -y parted
# 打印
parted /dev/sdb print
# 创建 GPT
parted /dev/sdb mklabel gpt
# 创建分区(推荐用 MiB/GiB 单位)
parted /dev/sdb mkpart primary xfs 0% 100%
# 0% 100% 表示整个盘
# 改对齐
parted /dev/sdb mkpart primary xfs 1MiB 100%
# 删
parted /dev/sdb rm 1
# 改大小
parted /dev/sdb resizepart 1 200GiB
parted 在脚本里比 fdisk 友好,因为它支持命令行直接传参,不需要 expect。
2.4 选择哪个工具
MBR 盘:随便。 GPT 盘: gdisk或parted。脚本化: parted。改分区表前必须备份数据。
三、文件系统选择
3.1 ext4
最成熟的 Linux 文件系统。 单文件最大 16 TiB,文件系统最大 1 EiB。 日志功能稳定,老牌首选。 CentOS 7 默认 xfs 之外的最常见选择。
# 格式化
mkfs.ext4 /dev/sdb1
# 或带参数
mkfs.ext4 -L data -m 1 /dev/sdb1
# -L:卷标
# -m:保留块百分比(默认 5%,数据库盘建议 1%)
# 调参
tune2fs -l /dev/sdb1
tune2fs -o journal_data_writeback /dev/sdb1
# 调日志模式,需 unmount
# 改卷标
tune2fs -L newlabel /dev/sdb1
风险提示:tune2fs 改 has_journal / 日志模式是高危操作,需要在 unmount 状态操作,且不能改 mount 中的文件系统。
3.2 xfs
CentOS 7+ / RHEL 7+ 默认文件系统。 单文件最大 8 EiB,文件系统最大 8 EiB。 性能优于 ext4,尤其大文件、高并发场景。 只能扩不能缩(缩只能用备份还原的方式)。
# 格式化
mkfs.xfs /dev/sdc1
mkfs.xfs -L data -f /dev/sdc1 # 强制格式化
mkfs.xfs -d agcount=16 -l size=128m /dev/sdc1
# agcount:allocation group 数量,影响并发度
# 扩
xfs_growfs /data
# 自动识别底层设备扩到的容量
# 看参数
xfs_info /dev/sdc1
# 修复(必须在 unmount 状态)
xfs_repair /dev/sdc1
# -L:强制清空日志(高危,会丢最近的事务)
# 碎片查看
xfs_db -c frag -r /dev/sdc1
xfs 的几个核心概念:
AG(Allocation Group):xfs 内部的并行单元,多个 AG 可以并行分配。 日志(xlog):xfs 的元数据日志,类似 WAL。 RT(Real-Time):可挂载独立 RT 设备用于视频流场景,生产用得少。
3.3 btrfs
B 树文件系统,类 ZFS 设计。 支持 snapshot、subvolume、压缩、RAID。 CentOS / RHEL 在 7.4+ 提供,但生产慎用,稳定性比 ext4 / xfs 差一截。
# 格式化
mkfs.btrfs /dev/sdd1
# 创建 subvolume
mount /dev/sdd1 /mnt
btrfs subvolume create /mnt/data
umount /mnt
mount -o subvol=data /dev/sdd1 /data
# 快照
btrfs subvolume snapshot /mnt/data /mnt/data-snap
# 压缩
mount -o compress=zstd /dev/sdd1 /data
生产数据库盘还是 ext4 / xfs 优先。btrfs 在 OpenSUSE / 桌面场景用得多。
3.4 文件系统选型建议
四、挂载与 fstab
4.1 临时挂载
# 手动挂载
mount /dev/sdb1 /data
mount -t ext4 /dev/sdb1 /data
mount -o noatime,nodiratime /dev/sdb1 /data
# 卸载
umount /data
umount /dev/sdb1
# 强制卸载(unmount 不掉时慎用)
umount -f /data
# 强制卸载并释放引用(很凶,用 lsof 找占用进程)
fuser -km /data
挂载选项常用:
defaults:包含rw, suid, dev, exec, auto, nouser, async。noatime:不更新访问时间戳,提升性能(数据库盘强烈推荐)。nodiratime:目录访问时间戳不更新。ro/rw:只读 / 读写。noexec:禁止执行二进制。nosuid:禁止 setuid。_netdev:网络设备,网络挂载后才挂载。nofail:挂不上不阻塞启动。
4.2 fstab 永久挂载
/etc/fstab 6 列:
<fs_spec> <fs_file> <fs_vfstype> <fs_mntopts> <fs_freq> <fs_passno>
实际例子:
# <file system> <mount point> <type> <options> <dump> <pass>
UUID=xxxxx-xxxxx-xxx / xfs defaults,noatime 0 1
UUID=yyyyy-yyyyy-yyy /boot xfs defaults 0 2
UUID=zzzzz-zzzzz-zzz /data xfs defaults,noatime 0 0
LABEL=backup /backup ext4 defaults,noatime,nofail 0 0
10.20.0.100:/nfs /nfs nfs defaults,_netdev 0 0
字段解释:
fs_spec:设备、UUID、LABEL、网络地址。**生产用 UUID,不要用/dev/sdX**(盘符会变)。fs_file:挂载点。fs_vfstype:文件系统类型。fs_mntopts:挂载选项,逗号分隔。fs_freq:dump 备份频率,0 表示不备份。fs_passno:fsck 顺序,根 1,其他 2,0 不检查。
# 拿 UUID
blkid /dev/sdb1
# /dev/sdb1: UUID="xxxxx-xxxxx-xxx" TYPE="xfs"
# 编辑 fstab
vim /etc/fstab
# 验证 fstab(不改写,只检查)
mount -a -f -v
# -f:模拟挂载(不真挂)
# -v:verbose
# 真挂载
mount -a
风险提示:fstab 写错会导致重启后系统起不来。改完 fstab 必须先 mount -a 验证 OK 再重启。
4.3 UUID vs 盘符 vs LABEL
/dev/sdX | ||
UUID | ||
LABEL |
生产永远用 UUID。盘符变了的常见场景:
加了新盘,老盘从 sdb 变 sdc。 内核重启,盘枚举顺序变了。 虚拟机克隆。
# 找 UUID
ls -l /dev/disk/by-uuid/
# 软链到具体的 /dev/sdX
# 找 LABEL
ls -l /dev/disk/by-label/
4.4 开机 mount 不上
如果 fstab 里有一行挂不上:
系统启动会卡在 emergency mode。 此时需要 root 密码进 maintenance 模式。
生产建议加 nofail:
UUID=xxx /data xfs defaults,nofail 0 0
nofail 表示挂不上不阻塞启动。但要清楚业务数据可能在另一个盘,挂不上时业务可能数据没读到。
风险提示:nofail + mount -a 在内核里表现是"不阻塞启动",但挂载点下访问会 Input/output error 或 No such file or directory。业务层要做容错。
五、LVM 逻辑卷
5.1 LVM 概念
LVM(Logical Volume Manager)在物理盘和文件系统之间加一层抽象:
物理盘 (PV, Physical Volume)
↓
卷组 (VG, Volume Group):一个或多个 PV 组成的资源池
↓
逻辑卷 (LV, Logical Volume):从 VG 里"切"出来的虚拟盘
↓
文件系统(mkfs / mount)
LVM 的好处:
在线扩容:底层加盘 → PV → VG → LV → 文件系统,不用停业务。 跨盘整合:把多块物理盘合成一个 VG,再切 LV。 快照:通过 lvcreate -s做快照(COW),适合做备份。
LVM 的代价:
多一层 I/O,性能下降 1~5%。 增加故障域(一个 PV 坏可能影响整个 VG)。 复杂度高,出问题排查链路长。
5.2 LVM 部署实战
# 1. 装 LVM 工具
yum install -y lvm2
# 2. 创建 PV(物理盘)
pvcreate /dev/sdb /dev/sdc
# 3. 创建 VG
vgcreate data-vg /dev/sdb /dev/sdc
# 4. 创建 LV
lvcreate -L 200G -n data-lv data-vg
# -L:大小
# -n:LV 名
# 5. 格式化
mkfs.xfs /dev/data-vg/data-lv
# 6. 挂载
mount /dev/data-vg/data-lv /data
# 写 fstab
echo"UUID=xxx /data xfs defaults,noatime 0 0" >> /etc/fstab
mount -a
5.3 关键命令
# 看 PV
pvs
pvdisplay /dev/sdb
# 看 VG
vgs
vgdisplay data-vg
# 看 LV
lvs
lvdisplay /dev/data-vg/data-lv
# 设备路径
/dev/data-vg/data-lv
/dev/mapper/data--vg-data--lv
# 两种写法等价
5.4 扩容流程
场景:data-vg 容量不够,要扩。
# 1. 加新盘(物理操作:插盘 / 加云盘)
# 2. 识别新盘
lsblk
# 假设新盘是 /dev/sdd
fdisk -l /dev/sdd
# 3. 创建 PV
pvcreate /dev/sdd
# 4. 扩 VG
vgextend data-vg /dev/sdd
# 5. 扩 LV
lvextend -L +500G /dev/data-vg/data-lv
# 或扩到 100% 剩余空间
lvextend -l +100%FREE /dev/data-vg/data-lv
# 6. 扩文件系统
# xfs:
xfs_growfs /data
# ext4:
resize2fs /dev/data-vg/data-lv
风险提示:
扩文件系统是相对安全的,在线可做。 xfs_growfs不用 unmount。resize2fs扩 LV 时需要 unmount 或在挂载状态下都可以(ext4 4.x+)。缩 文件系统是高危操作,必须先 umount + fsck + resize2fs。xfs 不支持缩。
5.5 删除 LVM
# 顺序:卸载 → 删 LV → 删 VG → 删 PV
umount /data
lvremove /dev/data-vg/data-lv
vgremove data-vg
pvremove /dev/sdb /dev/sdc
风险提示:以上每一步都不可逆,执行前确认数据已备份、业务已停。
六、SWAP 交换分区
6.1 SWAP 是什么
SWAP 是 Linux 的虚拟内存后端,物理内存不够时把冷数据写到磁盘。生产机器一般配 4~16 GB SWAP(云服务器常不配)。
# 看 SWAP
free -h
# total used free shared buff/cache available
# Mem: 62G 20G 30G 1.0G 12G 40G
# Swap: 4.0G 100M 3.9G
# 看 SWAP 设备
swapon -s
# Filename Type Size Used Priority
# /dev/sda3 partition 4194300 102400 -2
# /swapfile file 2097148 0 -3
6.2 创建 SWAP 分区
# 1. 创建分区或逻辑卷
fdisk /dev/sdb
# 建一个 8G 的分区,类型 82 (Linux swap)
# 2. 格式化
mkswap /dev/sdb1
# 3. 启用
swapon /dev/sdb1
# 4. 写 fstab
echo"UUID=xxx none swap sw 0 0" >> /etc/fstab
6.3 创建 SWAP 文件(不分区)
# 1. 建一个 8G 文件
dd if=/dev/zero of=/swapfile bs=1M count=8192
# 风险提示:dd 写错设备名会清空整块盘!先确认 /swapfile 路径正确
# 2. 改权限
chmod 600 /swapfile
# 3. 格式化
mkswap /swapfile
# 4. 启用
swapon /swapfile
# 5. 持久化
echo"/swapfile none swap sw 0 0" >> /etc/fstab
6.4 SWAP 调优
# 看 swappiness(0~100)
# 0:尽量不用 swap
# 100:积极用 swap
cat /proc/sys/vm/swappiness
# 默认 30,数据库机器建议 1~10
# 临时调
sysctl vm.swappiness=10
# 永久
echo"vm.swappiness = 10" >> /etc/sysctl.conf
sysctl -p
风险提示:swappiness=0 在 OOM 时可能直接杀进程而不换出,要根据业务权衡。
七、磁盘 IO 排查工具
7.1 iostat
iostat 是磁盘 IO 的头号工具,看的是每块设备的统计。
# 装
yum install -y sysstat
# 基础用法
iostat
# avg-cpu: %user %nice %system %iowait %steal %idle
# 5.0 0.0 2.0 10.0 0.0 83.0
# Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
# sda 0.00 1.00 2.00 5.00 64.00 100.00 40.00 0.50 5.00 3.00 5.00 2.00 2.50
# 详细 + 1 秒一次
iostat -x 1
# 注意:iostat 输出是"从启动到现在的平均",要看瞬时必须 -x 1 持续看
iostat -x 关键指标:
r/sw/s | ||
rkB/swkB/s | ||
rareq-szwareq-sz | ||
aqu-sz | ||
await | ||
r_awaitw_await | ||
%util | ||
svctm |
7.2 看 IO 满 / 慢的判断
# 持续看 1 秒一次
iostat -xz 1
# -x:扩展
# -z:忽略 0 活动的设备
# 1:每秒一次
# 看哪块盘最忙
iostat -xz 1 | grep -A1 "Device"
判断逻辑:
%util高(> 80%)但await低(< 10ms):设备接近满载但还能响应。%util高 +await高(> 50ms):严重 IO 瓶颈。aqu-sz持续 > 1:IO 队列积压。r_await>>w_await:读慢,可能是 page cache 失效。w_await>>r_await:写慢,可能是磁盘写盘慢、fsync 排队。
7.3 iotop
iotop 是 top 的 IO 版本,按进程看 IO。
# 装
yum install -y iotop
# 跑
iotop
# 看累计 IO
iotop -ao
# -a:累计
# -o:只显示有 IO 的进程
输出:
Total DISK READ: 0.00 B/s | Total DISK WRITE: 50.00 K/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO COMMAND
500 be/3 root 0.00 B/s 50.00 K/s 0.00 % 5.00 % mysqld --datadir=/data/mysql
800 be/4 mysql 0.00 B/s 20.00 K/s 0.00 % 1.00 % mysqld --datadir=/data/mysql
iotop 能直接定位到"哪个进程在狂打 IO",是排查磁盘满 / 写爆的关键。
7.4 vmstat
# 1 秒一次
vmstat 1
# procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
# r b swpd free buff cache si so bi bo in cs us sy id wa st
# 2 1 0 100000 5000 800000 0 0 20 100 1000 2000 5 2 83 10 0
关键字段:
b:阻塞进程数(等 IO)。> 0 说明有进程在等 IO。bi/bo:每秒从块设备读 / 写多少 KB。wa:IO 等待占比。> 30% 说明 IO 严重。
7.5 dstat
yum install -y dstat
# 组合输出
dstat -cdngym 1
# c: cpu
# d: disk
# n: net
# g: page
# y: sys
# m: mem
dstat 是 vmstat + iostat + netstat 的综合体,用着方便。
7.6 pidstat
# 看每个进程的 IO
pidstat -d 1
# 02:30:00 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
# 02:30:01 PM 27 1234 0.00 5.00 0.00 0 mysqld
pidstat -d 1 比 iotop 更轻,能长时间跑。
7.7 /proc/diskstats
cat /proc/diskstats
# 8 0 sda 1234 100 56789 5678 2345 200 12345 5678 0 1234 5678
# 主设备号 次设备号 设备名 读次数 合并读次数 读扇区数 读时间(ms) 写次数 合并写次数 写扇区数 写时间(ms) ...
这个文件记录从启动到现在的累计值,要做差分看增量。iostat 就是从这里读的。
7.8 sar
# 看历史
sar -d
# 看 1 秒一次
sar -d 1
# 看历史 IO(需要 sysstat 收集器在跑)
ls /var/log/sa/
# sa13: 13 号的二进制数据
# sar13: 13 号的文本报告
sar 是回看历史 IO 的关键工具,能跟 Prometheus 互补。
八、SMART 监控
8.1 smartctl
yum install -y smartmontools
# 启用 SMART
smartctl -s on /dev/sda
# 看健康
smartctl -H /dev/sda
# === START OF READ SMART DATA SECTION ===
# SMART overall-health self-assessment test result: PASSED
# 看所有属性
smartctl -A /dev/sda
# 关键属性(不同厂商编号可能不一样)
# 5 Reallocated_Sector_Ct:重映射扇区数,> 0 说明有坏块
# 187 Reported_Uncorrectable:无法纠正的错误
# 188 Command_Timeout:命令超时
# 197 Current_Pending_Sector:待映射扇区
# 198 Offline_Uncorrectable:脱机不可纠正
# 199 UDMA_CRC_Error_Count:数据线 CRC 错误(线缆问题)
8.2 smartd 守护
# 装
yum install -y smartmontools
# 改配置
vim /etc/smartd.conf
# 默认扫描所有盘
DEVICESCAN -a -o on -S on -n never,q
# -a:监控所有属性
# -o on:开启自动测试
# -S on:自动保存 attribute
# -n never,q:从不在 running test 时跳过(一般用 never)
# 起服务
systemctl enable smartd
systemctl start smartd
风险提示:smartd 自检(short / long test)会加重磁盘 IO 压力,生产一般不开启 -o on。
九、文件系统层问题
9.1 错误信息
内核会在 dmesg / journalctl 里报文件系统错误:
# 常见错误
dmesg | grep -E "EXT4|XFS"
# EXT4-fs error (device sda1): __ext4_get_inode_loc: unable to read inode block - ...
# XFS (dm-0): Corruption of in-memory data (0x8) detected at xfs_inode_claim ...
# 看日志
journalctl -k --since "1 hour ago" | grep -E "EXT4|XFS"
可能的原因:
磁盘坏块。 RAID 卡电池没电,写缓存丢失。 内核 bug(极少见)。 突然断电(write-back 模式下可能元数据不一致)。
9.2 fsck / xfs_repair
# ext4 修复(必须 unmount)
umount /data
fsck.ext4 -y /dev/sda1
# -y:自动 yes
# -f:强制检查(即使认为没问题)
# xfs 修复(必须 unmount)
umount /data
xfs_repair /dev/sda1
# -L:清空日志(高危,可能丢最近事务)
风险提示:
修复前先备份: dd if=/dev/sda1 of=/data/sda1.backup bs=4M。不要在 mount 状态做 fsck。 xfs_repair -L是大杀器,会把最近没刷盘的元数据全丢。
9.3 文件系统切到 read-only
常见原因:
fstab配错,启动时挂载失败。文件系统损坏,自动 remount ro。 mount -o remount,ro主动切。
# 看是不是 ro
mount | grep /data
# /dev/sda1 on /data type ext4 (ro,relatime,seclabel)
# 切回 rw
mount -o remount,rw /data
# 如果切不回去
# 1. 看 dmesg
dmesg | tail
# 2. 强制检查
umount /data
fsck.ext4 -y /dev/sda1
mount /data
十、实战案例
10.1 案例 1:磁盘写满,业务报错
现象:
业务写文件失败: No space left on device。监控告警: /data使用率 100%。
初步判断:
df -h看实际使用率。df -i看 inodes。du -sh看哪个目录占空间大。
命令检查:
df -h
# Filesystem Size Used Avail Use% Mounted on
# /dev/sda1 50G 50G 0 100% /
df -i
# Filesystem Inodes IUsed IFree IUse% Mounted on
# /dev/sda1 3276800 3276800 0 100% /
du -sh /*
# 1.5G /bin
# 8.0G /usr
# 35G /var
du -sh /var/* | sort -h | tail
# 30G /var/log
# 3.0G /var/lib
du -sh /var/log/* | sort -h | tail
# 28G /var/log/messages
# 1.2G /var/log/nginx
根因定位:
/var/log/messages28G,单文件超大,日志没切。多数情况是 logrotate没配好,或服务持续刷日志(比如printk风暴)。
修复:
# 1. 先看 messages 在刷什么
tail -F /var/log/messages
# 大量 "kernel: TCP: out of memory -- consider tuning tcp_mem"
# 2. 紧急腾空间(不删业务数据,只清日志)
# 风险提示:直接 rm 日志后空间不一定释放,因为进程还在 hold
> /var/log/messages
# 用 > 重定向清空,不删 inode
# 3. 找 hold 进程
lsof | grep messages
# 找出 syslog / rsyslog 进程
# 4. 优雅重启日志服务
systemctl restart rsyslog
# 5. 验证空间释放
df -h /
# 6. 长期方案:配 logrotate
cat > /etc/logrotate.d/messages << 'EOF'
/var/log/messages
{
daily
rotate 7
missingok
notifempty
compress
delaycompress
postrotate
/usr/bin/systemctl reload rsyslog > /dev/null 2>/dev/null || true
endscript
}
EOF
# 7. 手动触发
logrotate -f /etc/logrotate.conf
验证:
df -h /
# Filesystem Size Used Avail Use% Mounted on
# /dev/sda1 50G 22G 28G 45% /
复盘:
日志类问题反复出现,必须配 logrotate。 rm删大文件在生产不可用,用>清空更安全。lsof+fuser找 hold 进程。加监控: disk usage > 80%告警。
10.2 案例 2:磁盘 IO 高,%util 100%
现象:
应用慢,MySQL 查询 P99 从 50ms 涨到 2s。 监控报 disk_io_utilization > 95%。
初步判断:
iostat看是不是磁盘饱和。iotop看哪个进程在打 IO。
命令检查:
iostat -xz 1
# Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s await %util
# sda 0.00 50.00 10.00 200.00 100.00 800.00 150.00 100.00
iotop -ao
# Total DISK WRITE: 50.00 M/s
# PID USER DISK WRITE COMMAND
# 1234 mysql 50.00 M/s mysqld
根因定位:
await150ms,%util 100%,MySQL 在狂写 redo log。看 MySQL 是不是有大事务、长事务、批量写入。
# 进 MySQL 看 processlist
mysql -uroot -p -e "SHOW PROCESSLIST"
# 看长事务
mysql -uroot -p -e "SELECT * FROM information_schema.INNODB_TRX WHERE trx_started < NOW() - INTERVAL 60 SECOND"
# 看 innodb status
mysql -uroot -p -e "SHOW ENGINE INNODB STATUS\G" | grep -A 50 "LOG"
修复:
杀掉长事务。 拆批写(如果是一次性脚本)。 业务方加 innodb_io_capacity调整。如果是日常高 IO,加 SSD / 加内存 / 拆库。
验证:
# 杀完长事务
iostat -xz 1
# Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s await %util
# sda 0.00 10.00 5.00 50.00 50.00 200.00 10.00 30.00
复盘:
写密集业务监控 IOPS 和吞吐。 数据库盘要单独用 SSD。 长事务监控: trx_started < NOW() - INTERVAL 60 SECOND告警。配置 innodb_io_capacity让 IO 配额可预期。
10.3 案例 3:磁盘 read-only
现象:
业务报 Read-only file system。mount看挂载点是 ro。
初步判断:
看是不是 fstab 配错。 看 dmesg 是不是有 ext4 错误。 看是不是 mount -o remount,ro主动切的。
命令检查:
mount | grep /data
# /dev/sda1 on /data type ext4 (ro,relatime,seclabel)
dmesg | tail -30
# EXT4-fs error (device sda1): ext4_find_entry: reading directory lblock 0
# Aborting journal on device sda1.
# EXT4-fs (sda1): Remounting filesystem read-only
# 看磁盘 SMART
smartctl -A /dev/sda
# 5 Reallocated_Sector_Ct: 100 ← 坏块多
根因定位:
磁盘有坏块,内核把文件系统切到 ro 保护数据。 这是 Linux 的保护机制,不让坏块继续写脏。
修复:
# 1. 备份数据(ro 状态下还能读)
# 重要:ro 不影响读,dd 能拷出数据
dd if=/dev/sda1 of=/backup/sda1.img bs=4M conv=noerror,sync
# noerror:出错不中断
# sync:出错位置补 0(让 offset 准确)
# 2. umount
umount /data
# 3. fsck 修复
fsck.ext4 -y /dev/sda1
# 4. 切回 rw
mount /data
mount -o remount,rw /data
# 5. 验证
touch /data/testfile && rm /data/testfile
# 6. 如果坏块多,建议换盘
# 通过 RAID 卡或云盘快照重建
验证:
mount | grep /data
# /dev/sda1 on /data type ext4 (rw,relatime,seclabel)
复盘:
监控 SMART 关键字段。 备盘是底线:磁盘坏块突袭,没有备份就完蛋。 重要数据盘一定要 RAID / 云盘多副本。
10.4 案例 4:inodes 耗尽
现象:
df -h看磁盘还有空间,但写文件报No space left on device。df -i看 inodes 已 100%。
初步判断:
文件系统 inodes 用完。 大量小文件(几十 KB 以下)。
命令检查:
df -i
# Filesystem Inodes IUsed IFree IUse% Mounted on
# /dev/sda1 3276800 3276800 0 100% /data
# 找哪个目录小文件多
for i in /data/*; do
echo"$i: $(find $i -type f 2>/dev/null | wc -l) files"
done
# /data/cache: 3000000 files
# /data/log: 100 files
根因定位:
/data/cache300 万个小文件,inodes 耗尽。一般是缓存 / 临时文件 / session 等场景没清理。
修复:
# 1. 看什么文件最大量
find /data/cache -type f | head -20
# 2. 批量删除(注意速度,太多可能卡)
# 风险提示:直接 rm 几百万文件可能让 ls / du 卡死
# 推荐用 find -delete 串行删
find /data/cache -type f -mtime +1 -delete
# -mtime +1:1 天前
# -delete:删文件
# 3. 看 inodes 释放
df -i /data
# 4. 长期:配清理脚本
cat > /etc/cron.daily/clean-cache.sh << 'EOF'
#!/bin/bash
find /data/cache -type f -mtime +1 -delete
find /data/cache -type d -empty -delete
EOF
chmod +x /etc/cron.daily/clean-cache.sh
# 5. 监控 inodes 使用率
echo"Disk inodes usage check" >> /etc/zabbix/zabbix_agentd.d/...
验证:
df -i /data
# Filesystem Inodes IUsed IFree IUse% Mounted on
# /dev/sda1 3276800 500000 2776800 15% /data
复盘:
inodes 监控要跟空间监控分开。 小文件场景用对象存储(OSS / S3)替代本地 FS。 ext4 的 inodes 是格式化时定的,格式化后改不了。xfs 动态分配,理论上不会耗尽。
10.5 案例 5:LVM 扩容失败
现象:
加了新盘,做 LVM 扩容 lvextend报Insufficient free space。
命令检查:
pvs
# PV VG Fmt Attr PSize PFree
# /dev/sdb data-vg lvm2 a-- 500.00g 0
# /dev/sdd data-vg lvm2 a-- 200.00g 200.00g ← 新加的
vgs
# VG #PV #LV #SN Attr VSize VFree
# data-vg 2 1 0 wz--n- 699.99g 200.00g
lvextend -l +100%FREE /dev/data-vg/data-lv
# Insufficient free space in the volume group
根因定位:
错误信息可能误导,实际是 PE(Physical Extent)大小问题。 VG 创建时默认 PE 是 4 MB,剩余空间不足一次 PE 分配。 比如 VG 200G 全部被一个 LV 占满,剩 2 MB,加 100MB 新盘还是不够 PE。
# 看 PE
vgdisplay data-vg | grep -E "PE Size|Total PE|Alloc PE|Free PE"
# PE Size: 4.00 MiB
# Total PE: 4999
# Alloc PE: 4998
# Free PE: 1 ← 剩 1 个 PE = 4 MiB
# LV 占满了
lvs
# LV VG Attr LSize
# data-lv data-vg -wi-ao---- 499.00g
修复:
# 方案 1:缩 LV(高危,缩 ext4 也行,xfs 不行)
# ext4:
umount /data
fsck.ext4 -f /dev/data-vg/data-lv
resize2fs /dev/data-vg/data-lv 480G
lvreduce -L 480G /dev/data-vg/data-lv
# 风险提示:缩 LV 顺序是 先缩 FS → 再缩 LV,反过来会丢数据
# 方案 2:加盘加 PE
# 加一个 ≥ 4 MB 的 PV(任何盘都行)
pvcreate /dev/sde
vgextend data-vg /dev/sde
lvextend -l +100%FREE /dev/data-vg/data-lv
xfs_growfs /data
验证:
lvs
# LV VG Attr LSize
# data-lv data-vg -wi-ao---- 480.00g
df -h /data
复盘:
LV 扩容前先看 vgdisplay剩余空间。lvextend顺序:扩 LV → 扩 FS。lvreduce顺序:缩 FS → 缩 LV(反过来灾难)。缩 LV 操作是高危,生产前先备份。
十一、磁盘性能基线与监控
11.1 性能基线
# 顺序写测试
dd if=/dev/zero of=/data/test bs=1M count=1024 oflag=direct
# 1024+0 records in
# 1024+0 records out
# 1073741824 bytes (1.1 GB) copied, 2.123 s, 506 MB/s
# 风险提示:dd 写生产盘要确认路径,先看 df 是不是对的盘
# 顺序读
dd if=/data/test of=/dev/null bs=1M count=1024 iflag=direct
# 随机 IO
yum install -y fio
fio --filename=/data/test --direct=1 --rw=randread --bs=4k --size=1G --runtime=60 --time_based --name=randread
# 解释:
# --direct=1:绕过 page cache
# --rw=randread:随机读
# --bs=4k:4K 块
# --size=1G:测试文件 1G
# --runtime=60 --time_based:跑 60 秒
# 删测试文件
rm /data/test
11.2 node_exporter + Prometheus 监控
# 装 node_exporter
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
tar xzf node_exporter-1.7.0.linux-amd64.tar.gz
cp node_exporter-1.7.0.linux-amd64/node_exporter /usr/local/bin/
node_exporter 默认带磁盘指标(node_filesystem_*、node_disk_*)。
Prometheus 抓取配置:
scrape_configs:
-job_name:'node_exporter'
static_configs:
-targets:['10.20.0.11:9100','10.20.0.12:9100','10.20.0.13:9100']
11.3 告警规则
groups:
-name:disk_alerts
rules:
-alert:DiskSpaceUsageHigh
expr:(node_filesystem_avail_bytes{mountpoint="/"}/node_filesystem_size_bytes{mountpoint="/"})<0.1
for:5m
labels:
severity:warning
annotations:
summary:"挂载点 {{ $labels.mountpoint }} 剩余空间 < 10%"
-alert:DiskSpaceUsageCritical
expr:(node_filesystem_avail_bytes{mountpoint="/"}/node_filesystem_size_bytes{mountpoint="/"})<0.05
for:1m
labels:
severity:critical
annotations:
summary:"挂载点 {{ $labels.mountpoint }} 剩余空间 < 5%"
-alert:DiskInodesUsageHigh
expr:(node_filesystem_files_free{mountpoint="/"}/node_filesystem_files{mountpoint="/"})<0.1
for:5m
labels:
severity:warning
annotations:
summary:"挂载点 {{ $labels.mountpoint }} 剩余 inodes < 10%"
-alert:DiskIOUtilHigh
expr:100-(avgby(instance)(irate(node_disk_io_now[1m])*100)<50)
for:10m
labels:
severity:warning
annotations:
summary:"磁盘 IO util 持续高"
-alert:DiskReadErrors
expr:increase(node_disk_read_errors_total[5m])>0
labels:
severity:warning
annotations:
summary:"磁盘读错误增多"
-alert:DiskSMARTReallocated
expr:node_smart_reallocated_sector_count>0
labels:
severity:warning
annotations:
summary:"磁盘开始出现重映射扇区"
阈值要按业务调。生产别拍脑袋定阈值。
十二、内核参数调优
12.1 脏页相关
# 内核参数
vm.dirty_ratio = 20
# 系统总内存占比 > 20% 时,写进程开始同步写
vm.dirty_background_ratio = 10
# 系统总内存占比 > 10% 时,pdflush 开始回写
vm.dirty_expire_centisecs = 3000
# 脏页超过 30 秒强制回写
vm.dirty_writeback_centisecs = 100
# pdflush 唤醒间隔 1 秒
# 数据库盘可以调大
# /etc/sysctl.conf
vm.dirty_ratio = 40
vm.dirty_background_ratio = 10
风险提示:脏页参数调大会导致断电丢数据多,调小会让 IO 频繁。
12.2 IO 调度器
# 看当前调度器
cat /sys/block/sda/queue/scheduler
# [noop] deadline cfq [bfq]
# 括号内是当前
# 改
echo deadline > /sys/block/sda/queue/scheduler
# 持久化
echo'ACTION=="add|change", KERNEL=="sd[a-z]|vd[a-z]", ATTR{queue/scheduler}="deadline"' > /etc/udev/rules.d/60-ioschedulers.rules
# 调度器选择
# noop:NVMe / SSD 虚拟化场景
# deadline:通用默认
# cfq:已废弃
# bfq:桌面场景
数据库盘一般用 noop 或 deadline。
12.3 read_ahead_kb
# 预读大小
cat /sys/block/sda/queue/read_ahead_kb
# 128
# 顺序读场景调大
echo 2048 > /sys/block/sda/queue/read_ahead_kb
# 数据库盘一般 256
十三、容量规划与生命周期
13.1 容量规划
磁盘总容量:业务数据 × 1.5(一年增长)× 1.5(备份 / 日志 / buffer)= 规划容量。 监控保留期:30 天数据 + 30 天 Prometheus。 LVM / 云盘:预留 30% 给扩容。 单盘不超过 80% 警戒线。
13.2 扩容决策
# 评估当前使用率
df -h
# 评估增长趋势
# 看 30 天曲线,找增长率
# 例:每天增长 10GB,剩余 100GB
# 100/10 = 10 天后满
# 需要 7 天内扩容
# 扩容方案
# 1. 物理盘:插盘 / 加云盘
# 2. LVM:vgextend + lvextend + xfs_growfs
# 3. 文件系统迁移:数据从老盘拷到新盘(停机或在线)
13.3 数据生命周期
热数据(最近 7 天):高性能 SSD。 温数据(7~30 天):普通 SSD。 冷数据(> 30 天):对象存储 / 归档。 备份:单独存储,独立 RAID 或异地。
十四、运维操作清单
14.1 加盘
# 1. 确认新盘
lsblk
fdisk -l /dev/sdd
# 2. 分区
parted /dev/sdd mklabel gpt
parted /dev/sdd mkpart primary xfs 0% 100%
# 3. 建文件系统
mkfs.xfs /dev/sdd1
# 4. 临时挂载
mkdir -p /data2
mount /dev/sdd1 /data2
df -h /data2
# 5. 持久化
blkid /dev/sdd1
# 拿 UUID
echo"UUID=xxx /data2 xfs defaults,noatime,nofail 0 0" >> /etc/fstab
mount -a
14.2 LVM 扩容
# 1. 加新盘
lsblk
# 2. 创建 PV
pvcreate /dev/sdd
# 3. 扩 VG
vgextend data-vg /dev/sdd
# 4. 扩 LV
lvextend -l +100%FREE /dev/data-vg/data-lv
# 5. 扩 FS
xfs_growfs /data
# 或 ext4:
# resize2fs /dev/data-vg/data-lv
# 6. 验证
df -h /data
14.3 缩文件系统(高危,慎用)
# ext4
umount /data
fsck.ext4 -f /dev/sda1
resize2fs /dev/sda1 100G
# 然后改分区
fdisk /dev/sda
# 删旧分区,建新分区
# 最后
mount /dev/sda1 /data
# xfs 不支持缩
风险提示:缩文件系统是高危操作,任何中间步骤出错都可能导致数据丢失。生产别缩**。
14.4 删盘
# 1. 摘业务(umount + 改 fstab)
umount /data
vim /etc/fstab # 删掉对应行
# 2. 删 LVM(如果用了)
lvremove /dev/data-vg/data-lv
vgremove data-vg
pvremove /dev/sdd
# 3. 删分区
parted /dev/sdd rm 1
# 或 fdisk / gdisk
# 4. 物理摘盘 / 云盘 detach
十五、风险提示汇总
按危险程度从高到低排:
dd if=/dev/zero of=/dev/sdX | ||
fdisk w | lsblk + fdisk -l 确认 | |
mkfs | umount | |
lvreduce | ||
resize2fs | ||
xfs_repair -L | ||
mount -o remount,ro | ||
mount -a | ||
sysctl -w | sysctl -p 看错误 | |
chmod -R | -name 范围 | |
rm -rf /* | ||
> /var/log/messages |
十六、值班速查
16.1 一句话排查
# 一行命令看磁盘整体状况
df -h; df -i; iostat -xz 1 2 2>&1; mount | grep -E "ro,"
16.2 常用 5 条
# 1. 看哪个目录大
du -sh /* 2>/dev/null | sort -h | tail
# 2. 看 inodes
df -i
# 3. 看磁盘 IO
iostat -xz 1
# 4. 看谁在写
iotop -ao
# 5. 看文件系统错误
dmesg | grep -E "EXT4|XFS|Buffer I/O"
16.3 紧急操作
# 磁盘满紧急腾空间
> /var/log/messages
# 清空某大文件(必须用 >,不能 rm)
# 磁盘 read-only 强制切回 rw
umount /data
fsck.ext4 -y /dev/sda1
mount -o remount,rw /data
# inodes 满紧急清理
find /data/cache -type f -mtime +1 -delete
# 扩容(不停业务)
pvcreate /dev/sdd
vgextend data-vg /dev/sdd
lvextend -l +100%FREE /dev/data-vg/data-lv
xfs_growfs /data
十七、上线 Checklist
[ ] 磁盘型号 / 容量 / RAID / 云盘类型记录 [ ] 分区表类型记录(MBR / GPT) [ ] 文件系统类型记录(ext4 / xfs) [ ] 挂载点 + UUID 写进 fstab [ ] mount -a验证通过[ ] noatime/nofail等选项按需[ ] LVM 拓扑画出来(PV / VG / LV) [ ] logrotate 配好 [ ] 监控接上 Prometheus(空间、inodes、IO util、SMART) [ ] 告警阈值按业务调 [ ] 至少一次扩容演练 [ ] 至少一次数据恢复演练 [ ] 备份策略明确(全量 / 增量 / 异地) [ ] Runbook 写清楚紧急操作 [ ] 关键数据多副本 / RAID [ ] IO 调度器按业务调 [ ] 脏页参数调优 [ ] THP 关闭(数据库场景) [ ] 写盘压力测试 [ ] 应急联系人名单
十八、磁盘性能调优进阶
18.1 文件系统参数
# ext4
# 日志模式
mount -o data=writeback /dev/sda1 /data
# data=writeback:不写文件数据到 journal,最快但断电可能丢最新数据
# data=ordered(默认):只写元数据到 journal
# data=journal:全写,最慢但最安全
# barrier
mount -o barrier=0 /dev/sda1 /data
# 关闭 barrier,写性能会提升但断电丢数据风险
# xfs
# 关闭 barrier
mount -o nobarrier /dev/sdc1 /data
# 调日志 buffer
mount -o logbsize=256k /dev/sdc1 /data
# 默认 32k,调大减少日志写
风险提示:关闭 barrier 在 UPS / 写缓存电池保护下才能用,否则断电就丢数据。
18.2 文件系统碎片
# ext4 碎片
e4defrag /data
# e4defrag 在线整理,IO 压力中等
# xfs 碎片
xfs_fsr /data
# xfs_fsr 是定期整理工具
# 看碎片
xfs_db -c frag -r /dev/sdc1
# extent allocation ratio: 0.1234
# 越小碎片越少
碎片严重时 await 升高、%util 假性 100%(IO 放大)。数据库盘一般碎片少(顺序写),日志盘可能多。
18.3 page cache 调优
# 看 page cache
free -h
# buff/cache 行
# 释放 page cache
sync
echo 1 > /proc/sys/vm/drop_caches
# 1:释放 page cache
# 2:释放 dentries 和 inodes
# 3:都释放
# 调脏页比例
sysctl vm.dirty_ratio=20
sysctl vm.dirty_background_ratio=10
drop_caches 是临时释放,机器会自己回填。生产别**没事就 echo 3 > /proc/sys/vm/drop_caches,会引发一波冷启动。
18.4 队列深度
# 看队列深度
cat /sys/block/sda/queue/nr_requests
# 默认 128
# NVMe 可以调大
echo 1024 > /sys/block/nvme0n1/queue/nr_requests
# 看设备能力
cat /sys/block/sda/queue/queue_depth
# 物理设备能力
队列深度高 + 高并发 IO 性能好。但对单线程 IO 没帮助。
十九、特殊场景处理
19.1 大目录(百万级文件)
# ls 卡死?用 ls -f / stat
ls -f /data/bigdir | head
# -f:不排序,直接列
# find 比 ls 快
find /data/bigdir -maxdepth 1 -name "*.log" | head
# 看目录大小
stat /data/bigdir
# Size: 32768000 Blocks: 64000 IO Block: 4096 directory
# 目录大小 = 块大小 × 块数,文件越多目录越大
# 用 ls -laR 找文件太多卡死
# 用 find -printf 按格式输出
find /data/bigdir -type f -printf"%s %p\n" | sort -n | tail
大目录场景:建议改造为 hash 分桶(/data/bigdir/0/.../data/bigdir/1/...)或多级目录。
19.2 软链接与硬链接
# 软链接(symbolic link)
ln -s /data/file.txt /tmp/file.txt
# 软链是路径指向,可以跨文件系统
# 软链删了,原文件还在
# 原文件删了,软链失效(dangling symlink)
# 硬链接(hard link)
ln /data/file.txt /tmp/file.txt
# 硬链是 inode 引用,不能跨文件系统
# 硬链数和原文件共享 inode
# 删除一个不影响另一个
# 找软链断链
find /data -type l -xtype l
# -xtype l:目标不存在的软链
19.3 删除大量文件
# 风险提示:rm 几百万文件可能让 ls / df 卡死
# 推荐方案:
# 1. find -delete 串行
find /data/cache -type f -delete
# 2. rsync 清空(巧妙)
mkdir /tmp/empty_dir
rsync -a --delete /tmp/empty_dir/ /data/cache/
# rsync 内部优化过的 delete,比 rm 快几倍
# 3. perl 加速
perl -e 'opendir D, "/data/cache"; my @f = readdir D; closedir D; unlink @f'
# 4. python 脚本
python3 -c "import os; [os.unlink(os.path.join('/data/cache', f)) for f in os.listdir('/data/cache')]"
19.4 监控某个目录的写活动
# inotifywait
yum install -y inotify-tools
# 监控 /data 下的写
inotifywait -m -r -e modify,create,delete /data
# 看哪类操作多
inotifywait -m -r -e create --format '%w%f' /data | awk -F/ '{print $NF}' | sort | uniq -c | sort -rn | head
19.5 跨主机同步大文件
# rsync
rsync -avz --progress /data/bigfile user@remote:/data/
# -a:归档模式
# -v:详细
# -z:压缩
# 限速
rsync -avz --bwlimit=100m /data/ user@remote:/data/
# 断点续传
rsync -avzP /data/bigfile user@remote:/data/
# -P:--partial --progress
# 排除
rsync -avz --exclude='*.log' --exclude='cache/' /data/ user@remote:/data/
二十、磁盘 IO 问题深度排查
20.1 blktrace / btt
blktrace 是块设备 trace 工具,能看到 IO 究竟是怎么走的:
yum install -y blktrace
# 抓 30 秒 /dev/sda 的 trace
blktrace -d /dev/sda -w 30 -o trace
# 生成 trace.blktrace.0 文件
# 解析
btt -i trace.blktrace.0 | less
# 输出 Q(请求队列)、M(合并)、D(派发)、C(完成)等阶段
# 能看到 IO 在哪一阶段耗时最长
blktrace 是排查"IO 卡在哪个环节"的最细工具。生产慎用,会记录所有 IO,存储会暴涨。
20.2 bcc / bpftrace 工具
# biolatency:块设备 IO 延迟直方图
/usr/share/bcc/tools/biolatency 1 10
# 输出 latency 分布
# tcpconnect:实时连接请求
/usr/share/bcc/tools/tcpconnect
# opensnoop:跟踪 open 系统调用
/usr/share/bcc/tools/opensnoop
# 看哪些文件被频繁打开
bcc 工具能无侵入地看到应用层在做什么 IO。生产可以在问题复现时打开。
20.3 perf + 块设备
# 看块设备事件
perf stat -e block:block_rq_issue,block:block_rq_complete -a sleep 10
# 10 秒内 block IO 的派发/完成次数
# trace 单个进程
perf trace -p <pid> -e 'block:*'
perf 是内核级工具,能配合 bcc 一起用做深度排查。
20.4 队列阻塞在哪
# 看哪个进程在等 IO
cat /proc/<pid>/stack
# 如果停在以下位置,就是 IO 等:
# [<ffff...]>] __blk_queue_enter
# [<ffff...]>] blk_queue_enter
# [<ffff...]>] generic_make_request
# 用 ps 看进程状态
ps -eo pid,stat,wchan,comm
# STAT 列 D:不可中断睡眠(多数是等 IO)
# WCHAN 列:等待的内核函数
D 状态的进程(uninterruptible sleep)一般是等 IO,常见的进程状态还有 R(运行)、S(睡眠)、Z(僵尸)、T(停止)。
二十一、备份与恢复
21.1 dd 整盘备份
# 全盘备份
dd if=/dev/sda of=/backup/sda.img bs=4M status=progress
# bs=4M:4MB 块
# status=progress:显示进度
# 压缩备份
dd if=/dev/sda bs=4M status=progress | gzip > /backup/sda.img.gz
# 还原(高危,确认目标盘)
gunzip -c /backup/sda.img.gz | dd of=/dev/sda bs=4M status=progress
风险提示:dd 是字节级操作,写错盘全废。操作前反复确认 of 目标。
21.2 rsync 增量备份
# 全量
rsync -aAXv /data/ /backup/data-$(date +%F)/
# 增量
rsync -aAXv --delete --link-dest=/backup/data-2026-06-12 /data/ /backup/data-2026-06-13/
# --link-dest:硬链到上次备份,节省空间
21.3 LVM 快照
# 创建快照
lvcreate -L 10G -s -n data-snap /dev/data-vg/data-lv
# -s:snapshot
# -L 10G:快照大小
# 挂载快照
mkdir -p /mnt/snap
mount -o ro /dev/data-vg/data-snap /mnt/snap
# 备份快照(不影响原数据)
rsync -a /mnt/snap/ /backup/data-snap/
# 删快照
umount /mnt/snap
lvremove /dev/data-vg/data-snap
风险提示:快照满了会变成无效(/dev/mapper/data--vg-data--snap: read failed)。监控快照使用率。
21.4 备份策略
3-2-1 原则:3 份数据,2 种介质,1 份异地。 全量:每周一次。 增量:每天一次。 备份窗口:业务低峰期。 演练:每月一次恢复演练。
二十二、跨主机磁盘方案
22.1 NFS
# 服务端
yum install -y nfs-utils
mkdir -p /nfs/data
chmod 777 /nfs/data
vim /etc/exports
# /nfs/data 10.20.0.0/24(rw,sync,no_root_squash)
# 10.20.0.0/24:允许访问的网段
# rw:读写
# sync:同步写(更安全但慢)
# async:异步写(快但有数据丢失风险)
# no_root_squash:root 不降权
exportfs -a
systemctl start nfs
systemctl enable nfs
# 客户端
mount -t nfs 10.20.0.100:/nfs/data /mnt/nfs
# 写 fstab
echo"10.20.0.100:/nfs/data /mnt/nfs nfs defaults,_netdev 0 0" >> /etc/fstab
风险提示:NFS 跨机房延迟敏感场景表现差,不建议挂数据库。
22.2 iSCSI
# 服务端
yum install -y targetd targetcli
# 建一个 LUN
targetcli
/> /backstores/block create name1 /dev/sdb
/> /iscsi create iqn.2026-06.com.example:storage
/> /iscsi/iqn.2026-06.com.example:storage/tpg1/luns create /backstores/block/name1
/> /iscsi/iqn.2026-06.com.example:storage/tpg1/acls create iqn.2026-06.com.example:client
/> saveconfig
/> exit
systemctl start target
systemctl enable target
# 客户端
yum install -y iscsi-initiator-utils
# 发现
iscsiadm -m discovery -t st -p 10.20.0.100
# 10.20.0.100:3260,1 iqn.2026-06.com.example:storage
# 登录
iscsiadm -m node -T iqn.2026-06.com.example:storage -p 10.20.0.100 -l
# 登录后多出一个 /dev/sdc
lsblk
# 就可以像本地盘一样用
iSCSI 适合做共享存储、灾备链路。
22.3 GlusterFS / Ceph
分布式文件系统适合大数据 / K8s 场景,本篇不展开。
二十三、磁盘相关问题 FAQ
23.1 Buffer I/O error on device sda1, logical block xxx
# 原因:磁盘坏块
# 1. 看 SMART
smartctl -A /dev/sda
# 5 Reallocated_Sector_Ct > 0:坏块已被重映射
# 2. 备份数据
dd if=/dev/sda1 of=/backup/sda1.img bs=4M conv=noerror,sync
# 3. fsck 修复
umount /data
fsck.ext4 -y /dev/sda1
# 4. 换盘
23.2 No space left on device 但 df 看有空间
# 原因 1:inodes 满
df -i
# 处理:清理小文件
# 原因 2:ext4 保留块(5% 给 root)
df -h
# Filesystem Size Used Avail Use% Mounted on
# /dev/sda1 50G 48G 500M 98% /
# 实际可用 500M
# 保留块 5% = 2.5G,root 占用
# 处理(数据库盘推荐):
tune2fs -m 1 /dev/sda1
# 把保留块从 5% 调到 1%
# 原因 3:文件系统被 mount 成 ro
mount | grep /data
# 看是不是 ro
# 处理:mount -o remount,rw
# 原因 4:nfs / iSCSI 链接断了
mount
# 处理:重新挂载
23.3 Input/output error 读文件
# 1. 确认是不是磁盘问题
dmesg | tail
# 看有没有 I/O error
# 2. dd 救数据
dd if=/dev/sda1 of=/backup/broken_file conv=noerror,sync
# conv=noerror 出错不中断
# 3. 备份出来就行,原盘建议换
23.4 ext4-fs warning: mounting fs with errors
# 说明:fstab 挂了 errors=remount-ro
# 已经是 ro,需要修复
umount /data
fsck.ext4 -y /dev/sda1
mount /data
23.5 device or resource busy
# umount 不了?看谁在用
fuser -m /data
lsof +D /data
# 找到进程,kill 或 cd 出去
# 强制 umount(不推荐)
umount -l /data
# -l:lazy unmount,等占用结束后再卸
23.6 Cannot allocate memory
# vm.overcommit_memory 问题
cat /proc/sys/vm/overcommit_memory
# 临时调
sysctl vm.overcommit_memory=1
# 永久
echo"vm.overcommit_memory = 1" >> /etc/sysctl.conf
sysctl -p
二十四、与其他组件的协同
24.1 数据库(MySQL / PG)
数据库盘独立,不要和系统盘混用。 noatime必加。xfs 比 ext4 在数据库场景更稳。 监控: SHOW ENGINE INNODB STATUS、pg_stat_activity配合 iostat 看。
24.2 Elasticsearch
ES 倒排索引大量小文件, vm.dirty_ratio调小。不要用机械盘,SSD 必选。 大量小文件场景,inodes 监控要拉满。
24.3 Docker / K8s
容器数据盘用 localPV绑物理盘。StatefulSet 每个 Pod 独立 PVC。 日志盘限制 log-driver大小。镜像盘 overlay2用单独盘。
24.4 日志收集
ELK / Loki 一般落本地盘转 Kafka / 对象存储。 logrotate+rsyslog输出到独立盘。大日志场景用 lumberjack自动切分。
二十五、磁盘选型
25.1 服务器盘
25.2 云盘
普通云盘:HDD 类型,低成本,低 IO。 SSD 云盘:中性能,中等价格。 ESSD PL0/1/2/3:阿里云分档,PL3 100K IOPS。 本地 NVMe:性能最高,但有丢失风险。
云盘 IOPS 不是无限给的,按规格配额。规格选错容易触发 IO 限速("IO hang")。
25.3 RAID 选择
RAID 0:无冗余,性能高,不推荐生产。 RAID 1:镜像,可用 50% 容量。 RAID 5:单盘校验,可用 (N-1) 容量。 RAID 6:双盘校验,可用 (N-2) 容量。 RAID 10:先镜像再条带,可用 50%,性能 + 冗余。
数据库盘推荐 RAID 10。备份盘 RAID 5/6 够用。
二十六、Disk Performance 实战
26.1 fio 压测
# 装
yum install -y fio
# 顺序读
fio --name=seqread --filename=/data/test --rw=read --bs=1M --size=10G --numjobs=1 --runtime=30 --time_based --direct=1 --group_reporting
# 顺序写
fio --name=seqwrite --filename=/data/test --rw=write --bs=1M --size=10G --numjobs=1 --runtime=30 --time_based --direct=1 --group_reporting
# 随机读
fio --name=randread --filename=/data/test --rw=randread --bs=4k --size=10G --numjobs=4 --runtime=30 --time_based --direct=1 --group_reporting
# 混合 70 读 30 写
fio --name=mix --filename=/data/test --rw=randrw --rwmixread=70 --bs=4k --size=10G --numjobs=4 --runtime=30 --time_based --direct=1 --group_reporting
输出关键指标:
IOPS: iops:每秒 IO 次数。BW: bw:带宽(KB/s)。Latency: lat (usec):平均 / P50 / P99 / P99.9 延迟。
26.2 数据库盘推荐
IOPS > 50K 顺序写吞吐 > 500 MB/s 随机写延迟 P99 < 1 ms
达不到这指标的盘,跑 MySQL / PG 都很勉强。
26.3 日志盘推荐
顺序写吞吐 > 200 MB/s 顺序读吞吐 > 200 MB/s 容量大,单盘 4T+ 常见
二十七、磁盘趋势与新技术
27.1 NVMe over Fabrics
把 NVMe 协议跑在 RDMA / TCP 上,跨主机高性能块设备。延迟 100us 级别。
27.2 Persistent Memory (PMem)
Intel Optane 这种,介于内存和 SSD 之间。能做块设备,也能做 DAX 模式(绕过 page cache)。
27.3 ZNS SSD
分区命名空间 SSD,App 主动管理数据布局,减少写入放大。数据库场景有优势。
27.4 CXL
Compute Express Link,CPU 和设备之间的高速互联,未来可能替代 PCIe。存储应用还在早期。
二十八、风险与回滚
28.1 误操作回滚
# 1. 误 fdisk:先看是否已经 w
# 如果只是改了内存分区表(没 w),q 退出即可
# 如果已经 w 了,恢复难了,需要从备份还原
# 2. 误 mkfs:文件系统级别操作
# 立即 umount
# 如果没有备份,找 testdisk / photorec 救
# 3. 误 rm:找 extundelete(只对 ext4 有效)
yum install -y extundelete
umount /data
extundelete /dev/sda1 --restore-all
# 注意:rm 后不要再写新数据
# 4. 误 lvreduce:缩 LV
# ext4:先 fsck 确认
# xfs:不支持缩,需要回滚数据
# 5. 误 resize2fs:缩 FS
# 立刻 umount,不要再 mount
# 试 resize2fs 反向扩回去(如果空间够)
风险提示:任何破坏性操作前先备份。
28.2 数据丢失恢复
# ext4
extundelete /dev/sda1 --restore-all
# xfs
xfs_undelete(工具不完善)
# 实际只能从备份恢复
# 通用
testdisk /dev/sda
# 全盘扫,按文件类型恢复
photorec
# 按文件类型扫描恢复
文章到这里就结束了。Linux 磁盘这一块,**最容易踩坑的是"破坏性操作没备份"和"扩容时算错顺序"**。把分清楚 PV / VG / LV、xfs 只能扩不能缩、ext4 缩要 umount 这三件事搞清楚,再配合 iostat 跟 SMART 监控,生产里大多数磁盘问题都能 10 分钟内定位。
文末福利
网络监控是保障网络系统和数据安全的重要手段,能够帮助运维人员及时发现并应对各种问题,及时发现并解决,从而确保网络的顺畅运行。
谢谢一路支持,给大家分享6款开源免费的网络监控工具,并准备了对应的资料文档,建议运维工程师收藏(文末一键领取)。


100%免费领取
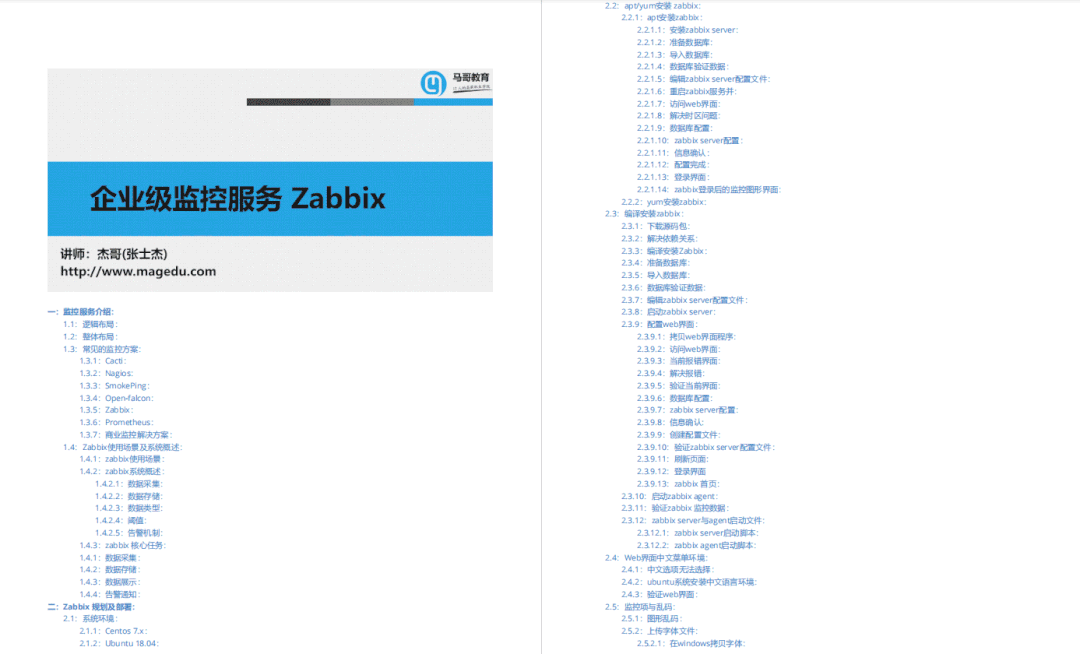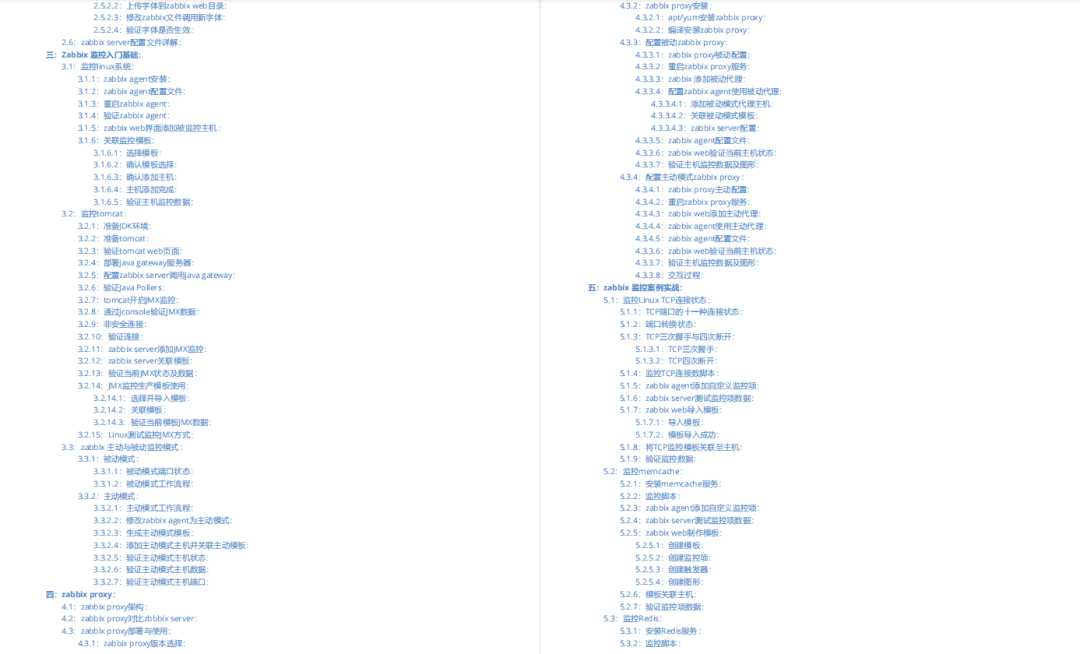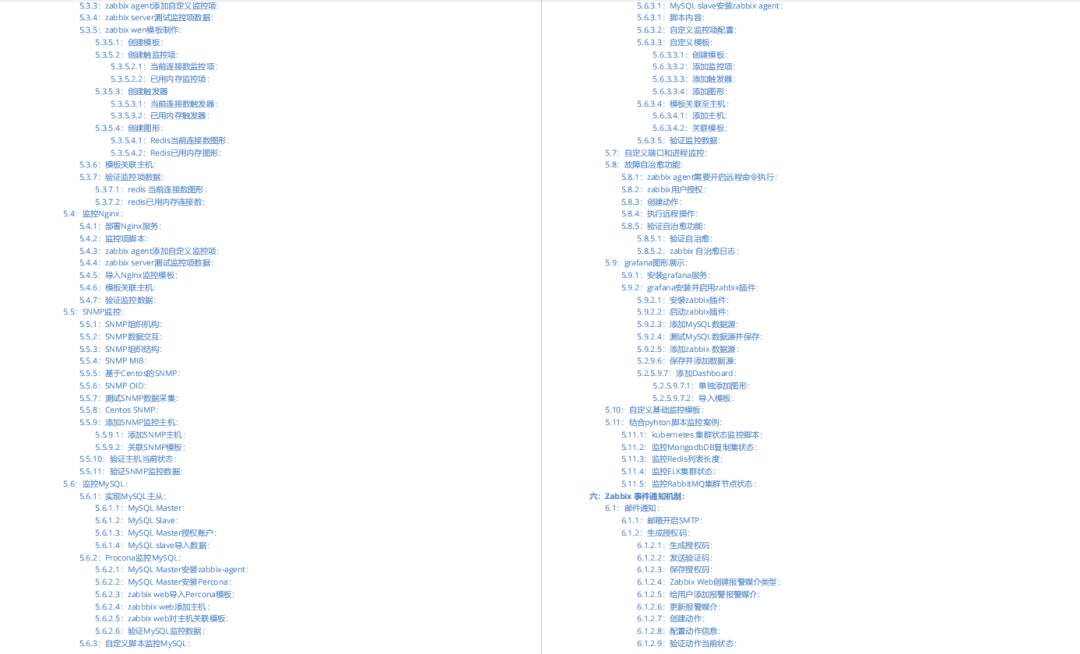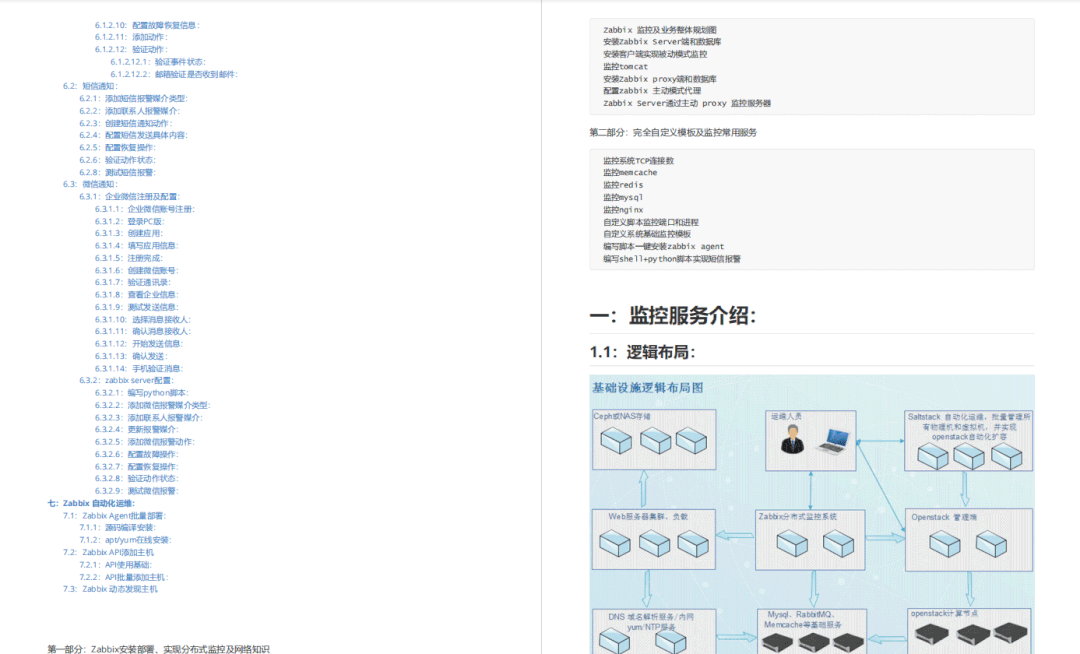
一、zabbix

二、Prometheus
内容较多,6款常用网络监控工具(zabbix、Prometheus、Cacti、Grafana、OpenNMS、Nagios)不再一一介绍, 需要的朋友扫码备注【监控合集】,即可100%免费领取。

以上所有资料获取请扫码

100%免费领取
(后台不再回复,扫码一键领取)
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 学习Python做的软件荣获公司5000元奖励 特此感谢郑老师!
- 零基础稳过!计算机二级Python超全备考攻略,小白也能一次通关
- 【Python练习题】吃透这130道练习题,轻松搞定Python95%知识点 (含答案解析)
- 在 TinaLinux 开启 gdbserver
- ZODB,一个透明的 Python 库
- 用Python做自动化报表,每天节省1小时
- python环境|pip安装|pip镜像使用
- Python爬虫实战,手把手教你采集豆瓣电影Top250
- 【视频课程】Linux云计算&运维工程师
- 会写Python的炒股人必看!手动下单慢亏滑点,这款GitHub工具不用申券商API就能自动交易
