Python爬虫入门连载06:分页爬取,自动翻页抓取多页新闻/图片数据
但实际使用中,数据都有很多页:
新闻列表1页、2页、3页…
壁纸图库第1页、第2页、第10页…手动改网址爬太慢,今天教你:
分析分页网址规律 → 循环自动翻页 → 批量爬取多页所有数据
一、分页核心原理
90%网站分页网址都有固定规律:
举例常见格式:
·page=1 第一页
·page=2 第二页
·page=3 第三页
只要找到页码变化的位置,用循环替换页码,就能自动翻页。
二、找分页网址规律(手把手方法)
1.打开列表网页第1页,复制URL
2.点下一页,复制第2页URL
3.对比两个链接,找出数字变化的位置
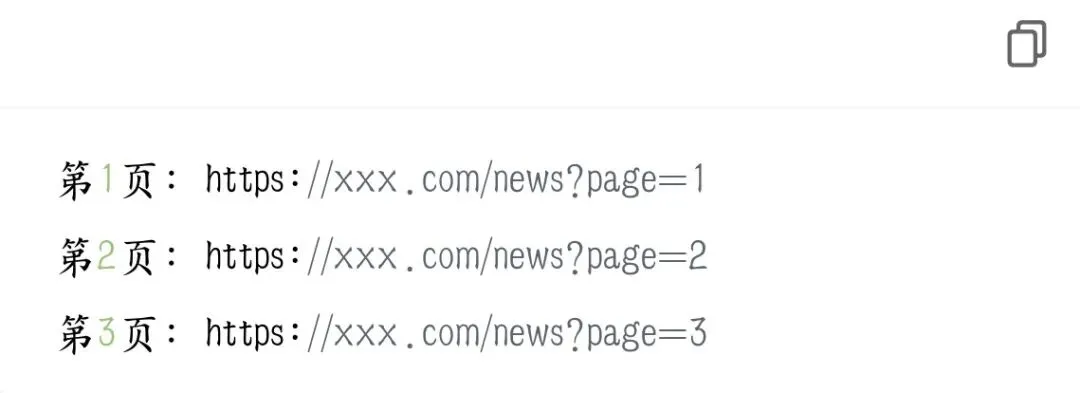
示例假设规律:
规律:只有 page=后面 的数字在变。
三、完整实战:自动翻页爬取1~5页新闻标题
可直接运行,自动爬取第1页到第5页:
四、代码核心讲解
1. for循环控制页码
自动遍历 1、2、3、4、5 页。
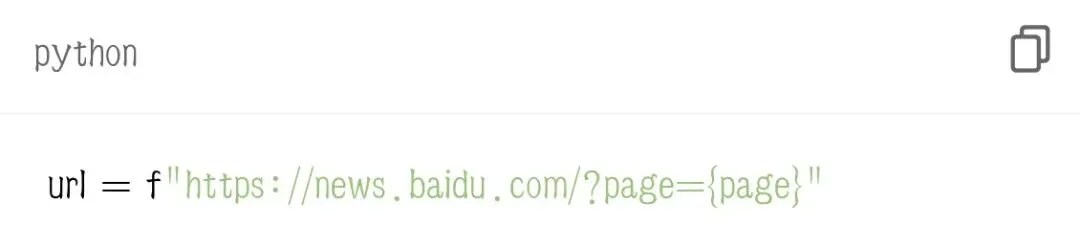
2. f-string 动态拼接网址
每循环一次,自动替换页码,生成新一页地址。3. 每页统一解析提取
每页结构一样,不用改代码,循环复用一套解析逻辑。
五、两种常见分页URL格式
格式1:参数型(最常见)
格式2:路径型
拼接方式同理,只改数字部分即可。
六、分页爬取通用步骤口诀
1.打开第1页、第2页网址
2.对比找出只有数字变化的地方
3.用for循环遍历页码
4.f-string动态拼接每页URL
5.每页请求、解析、提取数据
6.可保存到文本/Excel
七、新手避坑要点
❌ 不是所有网站都是 page=数字,一定要自己对比两页URL
❌ 不要请求太快,可加 time.sleep(1) 暂停1秒,防封IP
❌ 页数不要一次性爬太多,先测3页没问题再加大
❌ 网页结构改版后,要重新匹配标签和类名
八、加延时防被封(推荐加上)
导入time,每页暂停1秒,模拟人浏览节奏:
本期小结
1.分页爬虫核心:找URL页码规律 + 循环拼接网址
2.用 for + range 控制爬取页数
3.f-string 动态生成每一页链接
4.一套解析代码,自动爬多页
5.加 time.sleep 延时,礼貌爬取防拦截
小作业
找一个有分页的资讯/图片网站,分析URL规律,写代码自动爬取1~3页内容并打印。
下期预告
Python爬虫连载07:爬取数据保存到Excel表格把爬来的标题、链接、内容,一键存入Excel,做成可统计的表格报表,办公直接能用!





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
