Python对同一文件夹下的工作簿进行汇总
- 2026-06-29 21:27:07
Python对同一文件夹下的工作簿进行汇总上一篇讲了Python对同一文件夹下工作簿的合并,有读者问能不能对文件夹下的文件进行汇总,如下,同一文件夹下有多个学生成绩的工作簿: 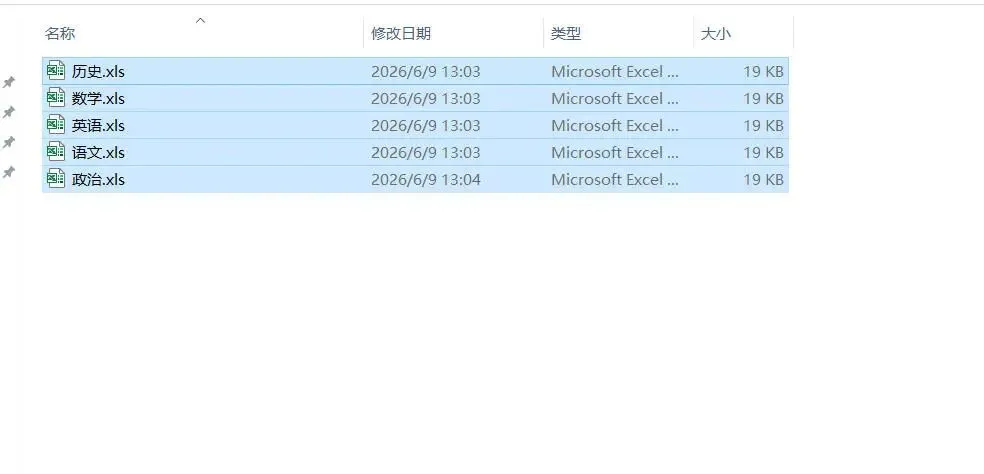
每个工作簿下有学生各科的成绩: 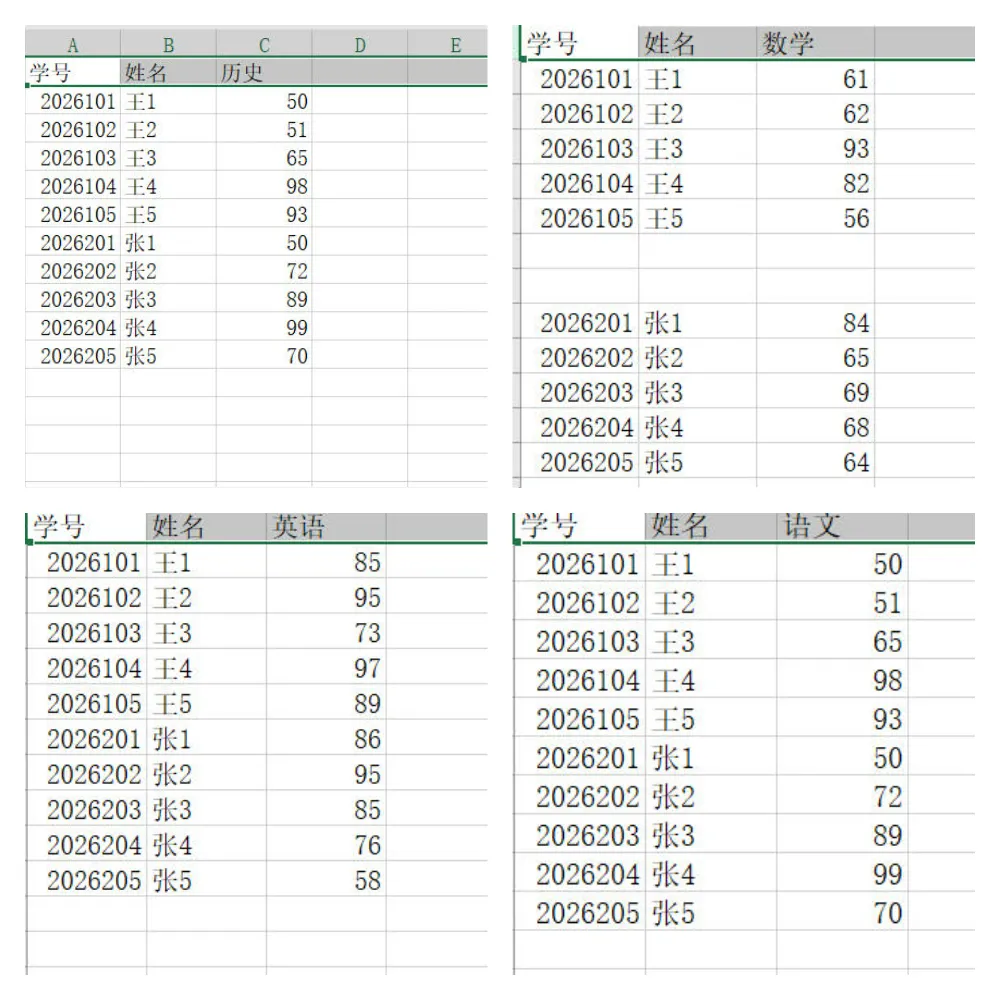
按唯一的学号进行汇总: 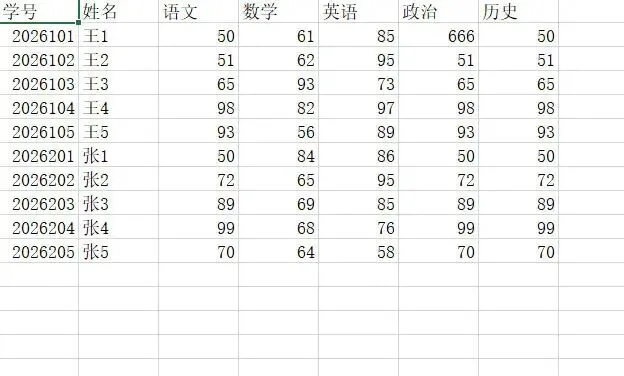
这个案例直接用合并的脚本是无法直接得出上面结果的,因为合并只会按原有的数据进行叠加,得到如下数据: 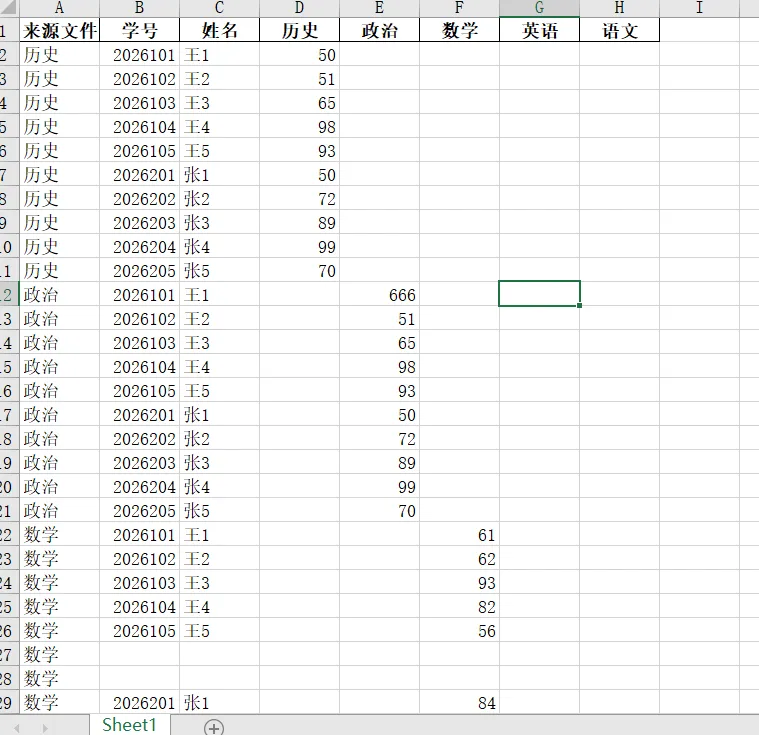
如想得到汇总的结果,需要做以下改变 1、按目标格式创建相应的列: 2、清洗数据删除空行: 3、以第一个文件的 学号+姓名 为基础,依次 merge 各科成绩 4、按参考文件列顺序排列 5、写入新文件 完整的代码如下: 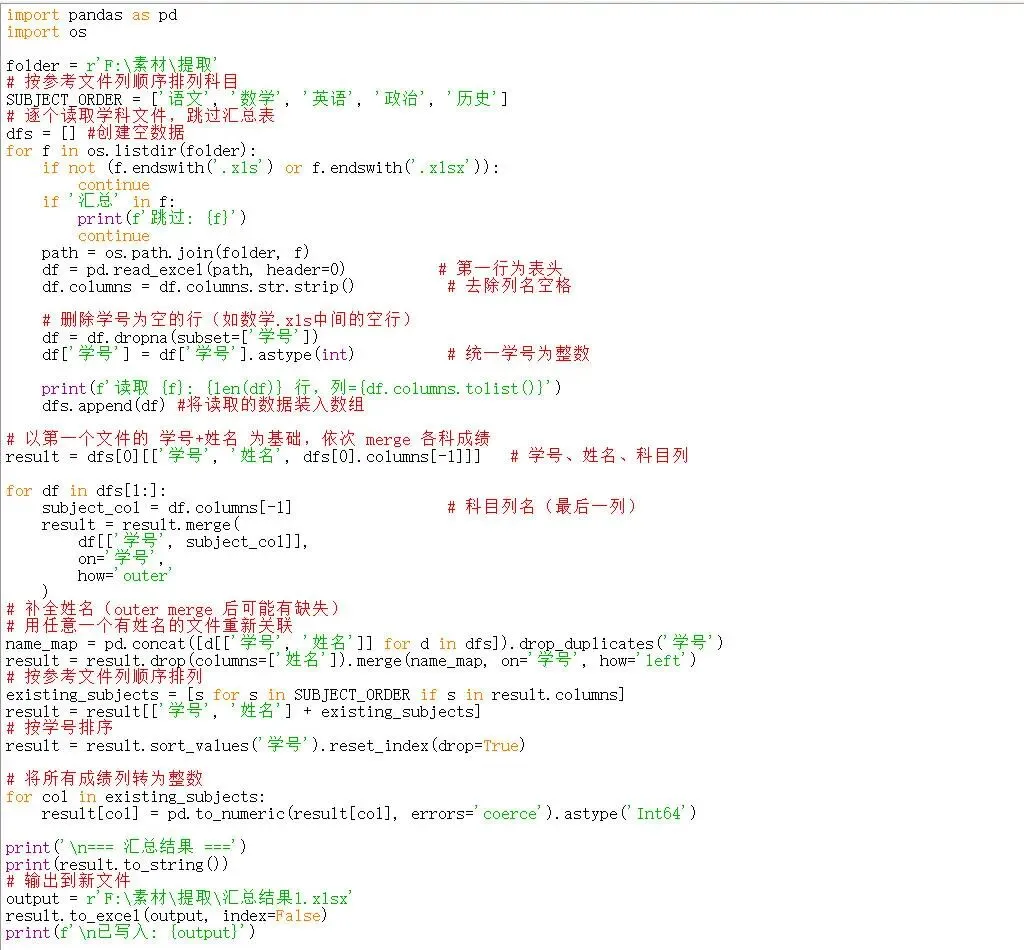
看下执行过程: 知道想要的结果, 再对应按步骤写代码,就能输出目标数据。
SUBJECT_ORDER= ['语文', '数学', '英语', '政治', '历史']
#删除学号为空的行(如数学.xls中间的空行)
df=df.dropna(subset=['学号'])
....
result=dfs[0][['学号', '姓名', dfs[0].columns[-1]]]
....
existing_subjects= [sforsinSUBJECT_ORDERifsinresult.columns]
result.to_excel(output, index=False)
已关注
关注
重播 分享 赞
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

