Ruff:Python代码治理新标配
- 2026-06-28 03:37:48
热门产品推荐: 天翼云高性能服务器套餐,4核8G5M带宽年度仅需680元!技术人必看的超值之选 1. 项目背景及简介
Python 项目最容易失控的,往往不是业务逻辑,而是格式、导入顺序、未使用变量、复杂度、历史语法和团队规范。很多团队一开始只靠人工 Code Review,后来又陆续接入 Flake8、isort、Black、pyupgrade、autoflake 等工具,结果 CI 流水线越来越长,配置文件越来越多,新人也很难一次搞清楚到底该跑哪个命令。
Ruff 的爆火,正是踩中了这个痛点:它用 Rust 重写 Python 代码检查与格式化能力,把多个工具链压缩成一个高性能二进制。项目地址已通过 GitHub API 与 git ls-remote 验证,仓库真实有效;截至本次核验,Ruff 拥有 47,868 Star、2,135 Fork,主语言为 Rust,最近更新时间为 2026-06-08。这不是一个小众工具,而是正在进入 Python 主流工程体系的基础设施。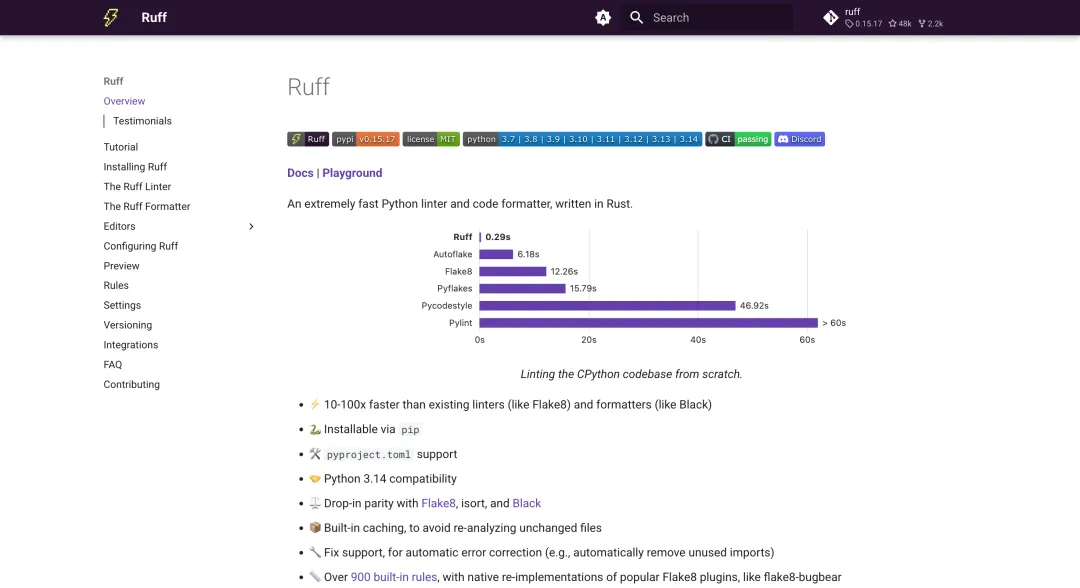
2. 技术栈解析
Ruff 的核心是 Rust + Python 语法分析 + 规则引擎 + Formatter。Rust 负责提供极快的启动速度、低内存占用和高吞吐扫描能力;Python 兼容层负责理解现代 Python 语法,包括类型标注、模式匹配、pyproject.toml 配置以及常见项目结构。对团队来说,它带来的不是“又多一个检查器”,而是把代码质量反馈从分钟级拉回秒级。
它还主动兼容 Python 生态的既有习惯:配置可以写在 pyproject.toml,规则覆盖大量 Flake8 插件场景,格式化风格接近 Black,导入排序可以替代 isort。这个设计非常聪明,因为它没有要求团队推翻原有规范,而是让老项目可以一项一项迁移,新项目可以直接把 Ruff 放进模板。
3. 核心功能
Ruff 的功能可以分成四类:检查、修复、排序和格式化。它可以发现未使用导入、变量覆盖、异常写法、复杂度过高、过时语法、潜在 Bug 风险等问题,也可以对安全规则执行 --fix 自动修复,让开发者少做机械修改。
更关键的是,它把多个高频动作统一到几个命令里:
Lint 检查:快速发现风格、质量和潜在错误。 自动修复:对确定安全的问题直接修复,减少人工成本。 导入排序:替代 isort,统一标准库、第三方库和本地模块顺序。 代码格式化:提供 formatter,减少 Black、isort、Flake8 多工具冲突。 编辑器集成:可接入 VS Code、Neovim、PyCharm 等环境,保存时即时反馈。
这些能力组合起来,Ruff 解决的是团队工程治理中的“最后一公里”:让规范不是上线前才发现的问题,而是在写代码时就被修掉。
4. 项目优势
Ruff 最大的优势是快。传统 Python 工具多为解释器脚本,启动、扫描和规则执行都有明显成本;Ruff 用 Rust 实现后,大型仓库也能快速反馈。对于每天多次提交、频繁跑 CI 的团队,这种速度不是锦上添花,而是能直接减少等待时间。
第二个优势是统一。以前团队要维护多套配置:.flake8、pyproject.toml、isort.cfg、Black 参数、CI 命令。Ruff 把多数场景收敛到一个入口,工具链越少,团队协作越稳定。推荐场景是:新 Python 项目、FastAPI/Django 后端、AI 工程仓库、数据处理脚本、开源项目维护。不推荐的场景是:团队已经有非常重的自定义 Flake8 插件体系,且短期无法迁移,可以先局部试点,不要一次性替换全部规则。
第三个容易出爆款的点,是 Ruff 对团队协作的影响非常直接。很多开发者并不排斥规范,排斥的是规范反馈太慢、规则太散、修复太机械。Ruff 把这些问题压缩到一个命令里,新人提交前可以自查,老项目可以逐步治理,负责人也能把规范沉淀进模板,而不是靠口头提醒。
落地时有一个关键建议:不要一开始就追求规则大而全。更稳的方式是先启用基础错误和导入顺序规则,把明显问题清理掉;第二阶段再加入 Bug 风险、复杂度和现代语法规则;最后才把格式化纳入统一流程。这样既能看到收益,又不会因为一次性改动太大影响业务迭代。
5. 安装使用
Ruff 安装非常简单,适合直接写入项目初始化文档。使用 uv 安装:
uv tool install ruff
也可以用 pip:
pip install ruff
日常开发中,建议把检查、修复和格式化拆成三个命令,分别用于本地开发和 CI:
ruff check .ruff check . --fixruff format .
推荐在 pyproject.toml 中统一配置,让团队所有人使用同一套规则:
[tool.ruff]line-length = 88target-version = "py311"[tool.ruff.lint]select = ["E", "F", "I", "UP", "B", "SIM"]ignore = []
6. 代码示例
下面示例故意包含未使用导入、导入顺序问题和可升级类型标注,保存为 demo.py 后可以直接运行,再用 Ruff 检查修复。
import osimport jsonfrom typing import Listdefbuild_names(items: List[str]) -> list[str]: result = []for item in items:if item != "": result.append(item.strip().title())return resultif __name__ == "__main__": names = build_names(["alice", "", " bob "]) print(json.dumps({"names": names}, ensure_ascii=False))
运行方式:
python demo.pyruff check demo.py --fixruff format demo.pypython demo.py
Ruff 会提示 os 未使用,并可以自动处理导入和部分现代化规则。这个例子很小,但放到真实项目里,价值会被放大:新人提交代码前先跑一次,CI 再做兜底,维护者就不用在 Review 中反复指出格式和导入问题。
7. 应用场景及案例说明
Ruff 最适合四类场景。第一类是 Python Web 后端,例如 FastAPI、Django、Flask 项目,接口多、文件多、多人协作,统一规范可以减少 Review 摩擦。第二类是 AI 与数据工程仓库,训练脚本、评测脚本、推理服务经常多人快速迭代,Ruff 可以把杂乱脚本逐步拉回工程化状态。
第三类是 企业存量项目治理。老项目不要一上来启用所有规则,可以先从 E、F、I 开始,解决未使用导入、明显错误和导入顺序,再逐步加入复杂度、Bug 风险和语法升级规则。第四类是 开源项目维护,通过 GitHub Actions 阻断低质量 PR,把维护者精力留给架构和业务判断,而不是机械格式问题。
还有一个真实场景是“老项目体检”。团队可以先在 CI 中只运行 ruff check .,不阻断合并,只收集问题数量;等问题收敛后再开启阻断。这样管理层能看到质量趋势,开发者也不会突然被几百条历史问题压垮。对公众号读者来说,这种渐进式方案比单纯介绍命令更有参考价值。
最后要提醒一点:代码规范工具只有进入日常流程才有价值。Ruff 最好同时出现在本地命令、编辑器保存动作和 CI 检查中。本地负责快速修复,编辑器负责即时提醒,CI 负责兜底阻断。三层配合起来,团队规范才不会只停留在文档里。
8. 总结
Ruff 的价值不是“多快一点”的单点优化,而是让 Python 团队重新整理代码治理流程。它把检查、修复、导入排序和格式化收敛到一个工具里,降低配置复杂度,也让规范反馈足够快,快到开发者愿意主动使用。
如果你正在维护 Python 项目,我的建议是:新项目直接把 Ruff 放进模板;老项目从基础规则开始渐进接入;CI 中先检查不自动修复,本地开发再使用 --fix 和 format。这样既不会制造大规模重构压力,又能持续提升代码质量。
项目地址:https://github.com/astral-sh/ruff
1. 项目背景及简介
Python 项目最容易失控的,往往不是业务逻辑,而是格式、导入顺序、未使用变量、复杂度、历史语法和团队规范。很多团队一开始只靠人工 Code Review,后来又陆续接入 Flake8、isort、Black、pyupgrade、autoflake 等工具,结果 CI 流水线越来越长,配置文件越来越多,新人也很难一次搞清楚到底该跑哪个命令。
Ruff 的爆火,正是踩中了这个痛点:它用 Rust 重写 Python 代码检查与格式化能力,把多个工具链压缩成一个高性能二进制。项目地址已通过 GitHub API 与 git ls-remote 验证,仓库真实有效;截至本次核验,Ruff 拥有 47,868 Star、2,135 Fork,主语言为 Rust,最近更新时间为 2026-06-08。这不是一个小众工具,而是正在进入 Python 主流工程体系的基础设施。
2. 技术栈解析
Ruff 的核心是 Rust + Python 语法分析 + 规则引擎 + Formatter。Rust 负责提供极快的启动速度、低内存占用和高吞吐扫描能力;Python 兼容层负责理解现代 Python 语法,包括类型标注、模式匹配、pyproject.toml 配置以及常见项目结构。对团队来说,它带来的不是“又多一个检查器”,而是把代码质量反馈从分钟级拉回秒级。
它还主动兼容 Python 生态的既有习惯:配置可以写在 pyproject.toml,规则覆盖大量 Flake8 插件场景,格式化风格接近 Black,导入排序可以替代 isort。这个设计非常聪明,因为它没有要求团队推翻原有规范,而是让老项目可以一项一项迁移,新项目可以直接把 Ruff 放进模板。
3. 核心功能
Ruff 的功能可以分成四类:检查、修复、排序和格式化。它可以发现未使用导入、变量覆盖、异常写法、复杂度过高、过时语法、潜在 Bug 风险等问题,也可以对安全规则执行 --fix 自动修复,让开发者少做机械修改。
更关键的是,它把多个高频动作统一到几个命令里:
Lint 检查:快速发现风格、质量和潜在错误。 自动修复:对确定安全的问题直接修复,减少人工成本。 导入排序:替代 isort,统一标准库、第三方库和本地模块顺序。 代码格式化:提供 formatter,减少 Black、isort、Flake8 多工具冲突。 编辑器集成:可接入 VS Code、Neovim、PyCharm 等环境,保存时即时反馈。
这些能力组合起来,Ruff 解决的是团队工程治理中的“最后一公里”:让规范不是上线前才发现的问题,而是在写代码时就被修掉。
4. 项目优势
Ruff 最大的优势是快。传统 Python 工具多为解释器脚本,启动、扫描和规则执行都有明显成本;Ruff 用 Rust 实现后,大型仓库也能快速反馈。对于每天多次提交、频繁跑 CI 的团队,这种速度不是锦上添花,而是能直接减少等待时间。
第二个优势是统一。以前团队要维护多套配置:.flake8、pyproject.toml、isort.cfg、Black 参数、CI 命令。Ruff 把多数场景收敛到一个入口,工具链越少,团队协作越稳定。推荐场景是:新 Python 项目、FastAPI/Django 后端、AI 工程仓库、数据处理脚本、开源项目维护。不推荐的场景是:团队已经有非常重的自定义 Flake8 插件体系,且短期无法迁移,可以先局部试点,不要一次性替换全部规则。
第三个容易出爆款的点,是 Ruff 对团队协作的影响非常直接。很多开发者并不排斥规范,排斥的是规范反馈太慢、规则太散、修复太机械。Ruff 把这些问题压缩到一个命令里,新人提交前可以自查,老项目可以逐步治理,负责人也能把规范沉淀进模板,而不是靠口头提醒。
落地时有一个关键建议:不要一开始就追求规则大而全。更稳的方式是先启用基础错误和导入顺序规则,把明显问题清理掉;第二阶段再加入 Bug 风险、复杂度和现代语法规则;最后才把格式化纳入统一流程。这样既能看到收益,又不会因为一次性改动太大影响业务迭代。
5. 安装使用
Ruff 安装非常简单,适合直接写入项目初始化文档。使用 uv 安装:
uv tool install ruff也可以用 pip:
pip install ruff日常开发中,建议把检查、修复和格式化拆成三个命令,分别用于本地开发和 CI:
ruff check .ruff check . --fixruff format .推荐在 pyproject.toml 中统一配置,让团队所有人使用同一套规则:
[tool.ruff]line-length = 88target-version = "py311"[tool.ruff.lint]select = ["E", "F", "I", "UP", "B", "SIM"]ignore = []6. 代码示例
下面示例故意包含未使用导入、导入顺序问题和可升级类型标注,保存为 demo.py 后可以直接运行,再用 Ruff 检查修复。
import osimport jsonfrom typing import Listdefbuild_names(items: List[str]) -> list[str]: result = []for item in items:if item != "": result.append(item.strip().title())return resultif __name__ == "__main__": names = build_names(["alice", "", " bob "]) print(json.dumps({"names": names}, ensure_ascii=False))运行方式:
python demo.pyruff check demo.py --fixruff format demo.pypython demo.pyRuff 会提示 os 未使用,并可以自动处理导入和部分现代化规则。这个例子很小,但放到真实项目里,价值会被放大:新人提交代码前先跑一次,CI 再做兜底,维护者就不用在 Review 中反复指出格式和导入问题。
7. 应用场景及案例说明
Ruff 最适合四类场景。第一类是 Python Web 后端,例如 FastAPI、Django、Flask 项目,接口多、文件多、多人协作,统一规范可以减少 Review 摩擦。第二类是 AI 与数据工程仓库,训练脚本、评测脚本、推理服务经常多人快速迭代,Ruff 可以把杂乱脚本逐步拉回工程化状态。
第三类是 企业存量项目治理。老项目不要一上来启用所有规则,可以先从 E、F、I 开始,解决未使用导入、明显错误和导入顺序,再逐步加入复杂度、Bug 风险和语法升级规则。第四类是 开源项目维护,通过 GitHub Actions 阻断低质量 PR,把维护者精力留给架构和业务判断,而不是机械格式问题。
还有一个真实场景是“老项目体检”。团队可以先在 CI 中只运行 ruff check .,不阻断合并,只收集问题数量;等问题收敛后再开启阻断。这样管理层能看到质量趋势,开发者也不会突然被几百条历史问题压垮。对公众号读者来说,这种渐进式方案比单纯介绍命令更有参考价值。
最后要提醒一点:代码规范工具只有进入日常流程才有价值。Ruff 最好同时出现在本地命令、编辑器保存动作和 CI 检查中。本地负责快速修复,编辑器负责即时提醒,CI 负责兜底阻断。三层配合起来,团队规范才不会只停留在文档里。
8. 总结
Ruff 的价值不是“多快一点”的单点优化,而是让 Python 团队重新整理代码治理流程。它把检查、修复、导入排序和格式化收敛到一个工具里,降低配置复杂度,也让规范反馈足够快,快到开发者愿意主动使用。
如果你正在维护 Python 项目,我的建议是:新项目直接把 Ruff 放进模板;老项目从基础规则开始渐进接入;CI 中先检查不自动修复,本地开发再使用 --fix 和 format。这样既不会制造大规模重构压力,又能持续提升代码质量。
项目地址:https://github.com/astral-sh/ruff
IT技术学习交流群:

软件接单交流:

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Vue 3+ Python + MySQL 开发的监控数据可视化平台
- "純純的係統"——用python來實現反算法(防止app讀電話本),在黑窗口來玩wx和打電話等等.
- 整理一波 Linux 常用命令,记得收藏哦
- Python快速入门学习笔记四十:协程 Coroutine 进阶 asyncio 与 IO 密集型场景深度对比、深度理解 asyncio 核心概念和入门语法
- 2025 年全国青少年信息素养大赛 Python 复赛真题
- 内黄创客 Python 代码编程培训
- 小小电脑 v1.1.0|手机上运行完整Linux桌面
- Python接单神器:10个Web开发利器,你能直接上手吃活
- Python零基础第一课|告别积木!第一行代码,无缝衔接图形化编程
- Python学习【182】:从冯・诺依曼架构到 Hello World:彻底讲清硬盘、内存、CPU 三级缓存的关系
