学到模块这一阶段,很多人第一次看到下面这行代码时,都会有点懵:
if __name__ == '__main__': ...
它长得有点奇怪。 前后都是双下划线。 中间还要和一个字符串比较。 看起来既不像普通变量,也不像函数。
于是很多新手会产生几个典型疑问:
这行代码到底在判断什么 为什么很多教程、很多项目里都写它 不写行不行 它和模块导入到底有什么关系
这一章,我们就把这件事彻底讲清。
你会发现,它其实一点都不玄。 它解决的,是一个非常实际的问题:
同一个 Python 文件,有时候既想让它能直接运行,又想让它能被别的文件导入复用。
而 __name__ == "__main__",就是专门用来区分这两种情况的。
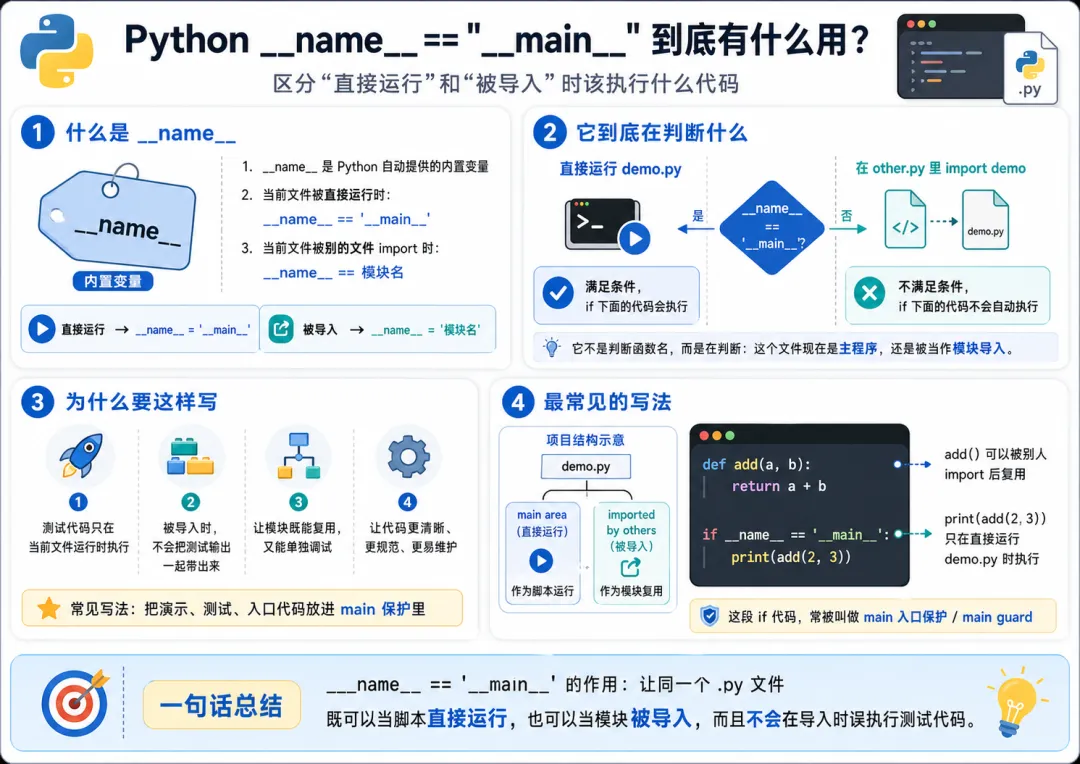
一、先说最直接的结论
你先记住一句最够用的话:
if __name__ == '__main__': 这一段里的代码,只会在当前文件被“直接运行”时执行。
如果这个文件是被别的文件导入的,那么这段代码通常不会执行。
这就是它最核心的作用。
也就是说,它像一个开关,用来判断:
当前文件现在是主程序入口 还是只是被别人拿来用的一个模块
这个判断,在模块化开发里非常重要。
二、先别急着理解变量,先看一个现实场景
假设你写了一个文件 my_math.py,内容如下:
defadd(a, b):return a + bprint('my_math 模块被执行了')
然后你写另一个文件 main.py:
import my_mathprint(my_math.add(3, 5))
很多新手第一次运行 main.py 时,会发现输出可能是这样:
my_math 模块被执行了8
这里为什么会多出一句:
my_math 模块被执行了
因为当你导入 my_math 时,Python 会执行这个模块顶层的代码。 而那句 print() 正好就在顶层。
这就引出了一个很现实的问题:
如果某个文件既要提供函数给别人导入,又在文件底部写了测试代码、演示代码、运行代码,那它一旦被导入,这些内容也可能跟着跑。
这通常不是你想要的结果。
三、为什么这会成为问题
因为模块通常是拿来复用的。
比如你写 my_math.py 的本意,可能只是提供:
add()sub()mul()
这些函数给别的文件用。
那别人导入它时,最理想的效果应该是:
安静地拿到这些函数 不要顺手把你测试时写的演示代码也执行一遍
否则就会出现很多奇怪现象。
比如导入一个工具模块时,屏幕突然打印一堆内容。 导入一个类文件时,里面顺手跑了一段测试代码。 导入一个配置模块时,意外触发了某些初始化逻辑。
这会让模块变得很不“干净”。
所以你就需要一种机制:
测试代码、演示代码、主程序入口代码,只在“直接运行这个文件”时执行;如果只是导入,就别执行。
这就是 __name__ == '__main__' 的意义。
四、那 __name__ 到底是什么
现在来解释这个变量本身。
你可以先这样理解:
__name__ 是 Python 自动提供的一个特殊变量,用来表示“当前模块的名字”。
注意,这个变量不是你手动定义的。 Python 在运行文件时会自动给它赋值。
它的值会根据当前文件的运行方式不同而不同。
如果这个文件是被直接运行的,__name__ 的值通常就是:
'__main__'
如果这个文件是被当成模块导入的,__name__ 的值通常就是它的模块名。
比如 my_math.py 被导入时,__name__ 往往就是:
'my_math'
这就是整个判断语句成立的基础。
五、直接运行和导入,__name__ 到底分别是什么
我们来把这件事说得更清楚一点。
假设有一个文件:
my_math.py
内容如下:
print(__name__)
情况一,你直接运行:
python my_math.py
这时输出通常会是:
__main__
情况二,你在别的文件里写:
import my_math
这时 my_math.py 被执行时,打印出来的通常是:
my_math
这说明什么?
说明同一个文件,在不同使用方式下,__name__ 的值不一样。
所以:
if __name__ == '__main__':
本质上就是在问:
当前这个文件,是不是作为主程序被直接运行的。
如果是,就执行下面缩进的代码。 如果不是,就跳过。
六、现在再看这句判断,就一点都不神秘了
if __name__ == '__main__': print('这是主程序入口')
你现在应该能把它翻译成人话了:
如果当前文件是直接运行的主程序 那就执行这里的内容
是不是一下子顺多了。
所以很多人刚看到这句代码时,觉得它难,主要不是因为逻辑难,而是因为 __name__ 和 __main__ 这两个名字长得比较特殊。 一旦你知道它其实只是在判断“当前文件是不是主程序”,这个知识点就一下落地了。
七、最常见的用法:把测试代码放进去
这是你当前阶段最实用的用法。
比如你写了一个模块 my_math.py:
defadd(a, b):return a + bdefsub(a, b):return a - b
你自己写完后,当然想顺手测试一下:
print(add(3, 5))print(sub(10, 4))
如果你直接把这两句写在文件底部,那么别人以后导入这个模块时,这两句也会执行。 这就不合适。
正确做法是这样:
defadd(a, b):return a + bdefsub(a, b):return a - bif __name__ == '__main__': print(add(3, 5)) print(sub(10, 4))
这样一来:
你直接运行 my_math.py 时,这两句测试代码会执行。 别人导入 my_math 时,这两句不会执行。
这就是最经典、最常见的用法。
八、这相当于把“模块功能”和“测试入口”分开了
这一点特别值得你体会。
模块本身真正要对外提供的,是:
add()sub()
而底部这段:
if __name__ == '__main__': ...
里面放的是当前文件自己运行时的测试或演示逻辑。
也就是说,它把一个文件里的两种角色区分开了:
模块角色 主程序角色
如果没有这个判断,这两个角色会搅在一起。 而有了这个判断,边界就清楚了。
这其实也是一种结构化思维。
九、一个更完整的小例子
假设你写一个 book.py,里面放图书类:
classBook:def__init__(self, title, author): self.title = title self.author = authordefshow_info(self): print(f'书名:{self.title},作者:{self.author}')
你当然想测试一下这个类有没有写对,于是可以这样写:
classBook:def__init__(self, title, author): self.title = title self.author = authordefshow_info(self): print(f'书名:{self.title},作者:{self.author}')if __name__ == '__main__': book1 = Book('Python 入门', '小王') book1.show_info()
这样:
直接运行 book.py 时,会看到测试结果。 如果别的文件写:
from book import Book
那底部的测试代码就不会乱跑。
这就是它在面向对象模块里特别常见的原因。
十、为什么很多正式项目都会写这一段
因为正式项目里,一个文件往往不只承担一种用途。
它可能既是一个模块,提供函数和类; 又希望开发者自己单独运行它时,能做简单测试、演示或调试。
这时候,if __name__ == '__main__': 就像一个非常自然的分界线。
你可以把它理解成:
上面是给别人导入用的“公共能力” 下面是这个文件自己单独运行时的“临时入口”
这样文件既能复用,又能单测,非常方便。
所以它不是“教程里喜欢装饰一下的标准姿势”,而是一个真正非常实用的结构工具。
十一、不写行不行
当然行。
Python 不会强制每个文件都必须写:
if __name__ == '__main__':
如果一个文件纯粹就是拿来当模块给别人导入的,里面也没有测试代码、演示代码、启动代码,那你完全可以不写。
但只要一个文件里既有可复用代码,又有一些“只想在自己运行时才执行”的内容,这时候它就非常值得写。
所以更准确地说:
不是所有文件都必须有它,但很多模块型文件一旦带测试逻辑,就很适合用它。
十二、为什么初学者特别容易低估它
因为在小练习阶段,你可能经常就是一个文件写到底。 既没有模块拆分,也没有“导入后不该执行”的困扰。 所以你会觉得这句代码可有可无。
但只要你开始把代码拆成多个模块,这个问题几乎很快就会冒出来。
尤其是下面这类场景:
工具模块里写了测试代码 类模块里写了示例代码 文件一导入就开始打印东西 甚至导入时顺手执行了一段主流程
这时候你就会意识到,这句判断不是装饰品,而是非常实际的边界控制工具。
十三、现在可以把它理解成“模块的自测开关”
这是个特别好记的说法。
你可以粗略地把:
if __name__ == '__main__':
理解成:
如果我是自己被单独运行,那就执行下面这些自测、演示或入口代码。
否则:
如果我是被别人导入当工具用 那下面这些代码就不要跑
这个翻译虽然不够学术,但特别实用,而且很适合当前阶段。
十四、一个特别常见的项目写法
比如你写一个工具模块 string_tools.py:
defreverse_text(text):return text[::-1]defcount_words(text):return len(text.split())
然后底部这样写:
if __name__ == '__main__': text = 'Python is very useful' print(reverse_text(text)) print(count_words(text))
这就非常合理。
上面是正式能力。 下面是本模块直接运行时的简单验证。
以后你在别处导入:
from string_tools import reverse_text
它就只会安静地把函数给你,不会顺带执行测试代码。
这种结构在真实项目里非常常见。
十五、这句代码和“程序入口”有什么关系
这个词你以后会经常看到:程序入口。
所谓入口,简单说就是:
程序真正开始运行的地方。
对于一个大型项目来说,不是每个模块都应该一导入就开跑。 通常只有那个主入口文件,才适合启动主要流程。
而:
if __name__ == '__main__':
就经常被用来标识这种入口。
比如:
defmain(): print('程序开始运行')# 主流程逻辑if __name__ == '__main__': main()
这个结构特别常见。
意思就是:
定义好主流程函数 main()只有当这个文件被直接运行时,才真正执行它
这会让程序结构很清楚。
十六、为什么很多人喜欢再配一个 main() 函数
比如这样:
defmain(): print('欢迎使用图书管理系统')# 其他主流程代码if __name__ == '__main__': main()
为什么不直接把逻辑全写进 if 下面?
当然也可以,但单独再包一层 main(),通常更清晰。
因为这样一来:
真正的主流程被封装成一个函数 入口判断只负责决定要不要启动 代码结构会更整洁
你以后在很多正式代码里都会看到这种组合:
main()加if __name__ == '__main__':
你现在先知道它是一个很常见、很推荐的结构就够了。
十七、一个最容易踩的坑:把所有代码都放在顶层
比如有人这样写:
print('程序启动')book1 = Book('Python 入门', '小王')book1.show_info()
如果这个文件以后被别的模块导入,这些代码也会跟着执行。 而导入模块时,通常你并不希望它自动开始跑业务逻辑。
所以从这一章开始,你要慢慢形成一个习惯:
模块顶层尽量放定义,不要乱放执行性代码。
什么叫定义?
函数定义 类定义 常量定义
什么叫执行性代码?
创建对象 打印结果 运行主流程 做测试
这些内容,如果只想在直接运行文件时执行,就尽量放到:
if __name__ == '__main__':
里面。
这会让你的模块更“干净”。
十八、和前面模块知识怎么串起来理解
现在你可以把前几章串起来了。
模块,就是一个独立的 .py 文件。 这个文件有时候既想提供能力给别人导入,又想在自己运行时做测试或演示。 那就需要一种方式,把“定义”和“直接运行时才该执行的代码”分开。__name__ == '__main__' 就是这个分界线。
所以它不是孤零零的语法点,而是模块化开发中非常自然会出现的一种结构安排。
这样一串起来,这个知识点就不会显得突兀。
十九、本章小练习
你可以做两个非常适合巩固的练习。
第一个练习:
新建一个 my_math.py 文件,里面写两个函数:
add(a, b)sub(a, b)
然后把测试代码写进:
if __name__ == '__main__':
里。 接着再新建一个 main.py 去导入 my_math,看看测试代码会不会执行。
第二个练习:
把你之前写过的 Book 类单独放进 book.py。 文件底部用 if __name__ == '__main__': 写一个简单示例。 再在另一个文件里导入 Book,观察底部示例代码是否还会执行。
这个练习特别有帮助,因为你一旦亲手试一遍,就会马上明白这句判断到底挡住了什么。
二十、本章总结
这一章最重要的,是把这句很多人第一次看到会发懵的代码真正看懂。
__name__ 是 Python 自动提供的一个特殊变量,用来表示当前模块的名字。 如果一个文件被直接运行,__name__ 通常等于 '__main__'。 如果一个文件被当作模块导入,__name__ 通常等于模块名。 所以 if __name__ == '__main__': 本质上是在判断:当前文件是不是作为主程序直接运行。 它最常见的作用,是把测试代码、演示代码、主程序入口代码和模块定义分开。 有了它,模块既可以被别人安静导入,又可以在自己单独运行时执行测试或主流程。
下一章我们继续往前走,进入标准库部分:085|标准库初识:为什么 Python 自带这么多工具。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
