Python模板匹配识别计算题验证码:固定场景下的轻量OCR识别方案
前言
在验证码、题库截图、训练样本识别这类场景里,经常会遇到一种非常固定的图片:
比如一张图片里只会出现 3+4、7x2、9-1 这种 10 以内的加减乘除表达式。
这种问题如果直接上 OCR,当然也能做,但并不划算。因为 OCR 的优势在于处理复杂文本、多字体、多背景、多版式,而这里的输入非常规整,完全可以用更轻量、更可控的方式解决。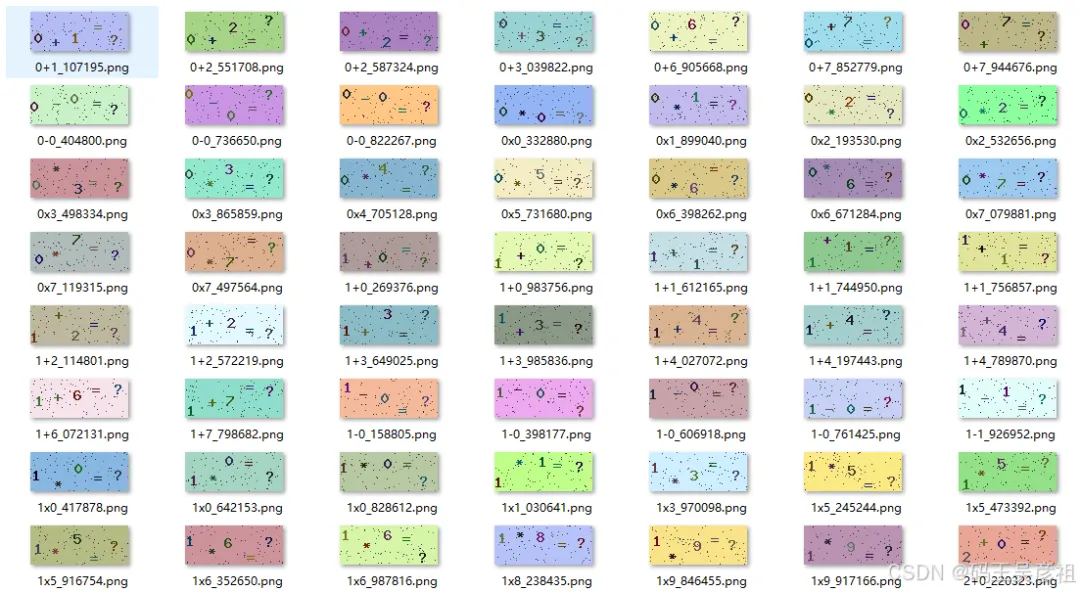
最合适的办法就是:模板匹配。
这篇文章只讨论一个核心问题:
如何用模板匹配识别固定样式的数学表达式图片。
一、为什么这个场景适合模板匹配
模板匹配不是万能方案,但它非常适合以下条件:
而本文这个场景正好全部满足。
识别对象只包括:
并且表达式结构固定为:
左数字 + 运算符 + 右数字
这就意味着我们根本不需要做复杂文本检测,只需要把图片切成三块,再分别判断这三块最像哪个模板即可。
二、先看原始样本图
下图是一张实际样本图,内容是 0+1。
从这类图的特征可以看出来,它非常适合做固定规则识别:
这就是模板匹配能成立的基础。
三、整体识别思路
整个方案可以概括为下面几个步骤:
也就是说,这不是“识别整张图里的文字”,而是:
问题规模被压得非常小,所以实现也会非常直接。
四、固定布局下的区域切分
既然图片排版固定,就没必要做通用字符分割。最简单的做法就是直接按横向坐标切块。
例如:
SIDE_RANGES = { "L": (0, 18), "OP": (18, 38), "R": (38, 58),}
含义如下:
对应的横向范围分别是:
下图是按区域切分后的可视化效果: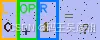
对应代码可以写成:
def split_regions(image): return { "L": image[:, 0:18], "OP": image[:, 18:38], "R": image[:, 38:58], }
这种方式的核心前提只有一个:
所有图片的字符位置必须稳定。
如果你的样本集已经满足这个条件,那么直接切块会比轮廓检测、投影分割、连通域分析更稳定、更省事。
五、字符前景提取的关键思路
切出局部区域后,接下来要解决的问题是:
怎样把字符本体从背景中提出来。
在固定样式图片中,通常存在一个明显特征:
因此可以直接统计区域中的颜色分布:
关键代码如下:
from collections import Counterimport numpy as npdef extract_exact_mask(image, x1, x2, min_count=6): roi = image[:, x1:x2] colors = Counter(tuple(int(v) for v in px) for row in roi for px in row) candidate_rgb = None for rgb, count in colors.most_common()[1:]: if count >= min_count: candidate_rgb = rgb break if candidate_rgb is None: raise ValueError("no foreground color found") color = np.array(candidate_rgb, dtype=np.uint8) mask = np.all(roi == color, axis=2).astype(np.uint8) * 255 ys, xs = np.where(mask > 0) return mask[ys.min(): ys.max() + 1, xs.min(): xs.max() + 1]
这个方法比简单二值化更适合固定色块图片,因为它直接利用了“字符颜色稳定”这一先验条件。
六、归一化处理为什么重要
很多人第一次做模板匹配,会直接把切出来的字符区域和模板图一对一比较。这通常不够稳,原因是:
因此模板匹配之前,必须先统一字符表示。
这里采用的方法是:
关键代码如下:
import cv2import numpy as npdef normalize_mask(mask, size=32): canvas = np.zeros((size, size), dtype=np.uint8) h, w = mask.shape scale = min((size - 4) / w, (size - 4) / h) nw = max(1, int(round(w * scale))) nh = max(1, int(round(h * scale))) resized = cv2.resize(mask, (nw, nh), interpolation=cv2.INTER_NEAREST) ox = (size - nw) // 2 oy = (size - nh) // 2 canvas[oy:oy + nh, ox:ox + nw] = resized return (canvas > 0).astype(np.uint8)
下图展示了三个区域从原始裁剪、前景 mask 到归一化结果的全过程:
这一步的意义非常大:
可以说,归一化质量几乎直接决定了模板匹配的稳定性。
七、模板库应该怎么设计
模板匹配的核心不是“有没有模板”,而是“模板是否足够稳定”。
在这个项目里,模板库只需要覆盖三类字符:
为什么左右数字要分开?
因为虽然字符本身相同,但在真实图片中:
把左模板和右模板分开,匹配会更稳。
模板来源有两种常见做法:
1. 运行时从样本文件学习
优点:
缺点:
2. 预先固化模板到代码中
优点:
缺点:
如果你的图片样式长期稳定,那么直接把模板固化进代码会更省事。
八、模板匹配到底比什么
归一化之后,每个字符都可以表示成一个固定大小的二值矩阵。
例如 32x32,本质上就是 1024 个 0/1 点位。
那么两个字符图像是否相似,就变成了一个非常直接的问题:
有多少个像素位置相同,有多少个位置不同。
这里可以使用汉明距离:
import numpy as npdef hamming_distance(a, b): return float(np.mean(a != b))
距离越小,说明两个字符越像。
然后在模板集合里取最小值对应的标签:
def predict_part(image, side, templates): x1, x2 = SIDE_RANGES[side] mask = normalize_mask(extract_exact_mask(image, x1, x2)) return min(templates[side], key=lambda sample: hamming_distance(mask, sample.mask)).label
这其实就是一个很纯粹的最近邻匹配,只不过特征不是向量嵌入,而是二值图形本身。
九、为什么这种方法速度很快
模板匹配方案快,主要原因有三点:
1. 搜索空间极小
左侧只需要在 10 个数字里比较。
右侧也只需要在 10 个数字里比较。
运算符只需要在 3 个符号里比较。
整个识别过程最多也就是几十次小矩阵比较。
2. 不做复杂检测
没有目标检测。
没有字符定位网络。
没有 OCR 解码过程。
没有语言模型推理。
整个流程就是固定切块 + 二值图比较。
3. 数据结构简单
模板本身就是小尺寸二值矩阵,内存占用很低,比较操作也很轻。
在这种场景下,模板匹配的响应速度通常会明显快于通用 OCR。
十、这种方案的边界在哪里
模板匹配虽然简单有效,但它的适用边界非常明确。
适合:
不适合:
换句话说,这类方案本质上是一种:
针对固定样式输入做强约束优化的工程方案。
它不是通用 OCR 的替代品,而是在小范围问题里更务实的解法。
十一、总结
对于固定样式的数学表达式图片,模板匹配是一个非常高性价比的方案。
它的核心并不复杂:
真正让它有效的原因,不是算法有多高级,而是它充分利用了场景先验:
这类问题如果硬套通用 OCR,往往是在用更重的方案解决更小的问题。
而模板匹配的价值恰恰在于:
在受控场景下,用最简单的办法拿到足够稳定的结果。



